CVPR 2023 Universal Instance Perception as Object Discovery and Retrieval
文章目录
- 背景
- 摘要
- 介绍
- 贡献
- 方法
-
- 1.提示生成
- 2.图像提示特征融合
- 3.目标发现和检索
- 训练
- 推理
- 结果
- 展望
- 相关
-
- IDOL | ECCV2022
- OFA

作者:大连理工大学信息与通信工程学院,字节跳动,香港大学,鹏城实验室
论文:https://arxiv.org/pdf/2303.17225.pdf
代码在https://github.com/MasterBin-IIAU/UNINEXT
中文名称:将统一实例感知任务 作为 目标发现和检测范式
背景
所有的实例感知任务都旨在寻找由类别名称、语言表达式和目标注释等查询指定的某些对象,但是这个完整的字段被分成了多个独立的子任务。
实例感知任务通常会分成很多子任务,分散的设计理念带来以下缺点:
(1)独立设计阻碍模型在不同任务和领域之间学习和共享通用知识,导致冗余参数。
(2)不同任务之间相互协作的可能性被忽略了。
(3)受固定大小分类器的限制,传统的对象检测器难以在具有不同标签词汇的多个数据集上联合训练,并在推理过程中动态更改对象目录以进行检测。
VOS:video object segmentatioin
SOT: single object tracking
VIS: video instance segmentation
MOTS: multi-object tracking and segmentation

Unified-IO和OFA提出了一个统一的sequence-to-sequence框架,可以处理各种视觉、语言和多模态任务。虽然这些工作可以执行许多任务,但不同任务之间的共性和内在关系却很少被探索和利用。
统一模型架构。这些作品通常为一组密切相关的任务设计统一的公式或模型架构。例如,Mask R-CNN提出了一个统一的网络来同时执行目标检测和实例分割。Mask2Ex提出了一个能够处理全景、实例和语义的通用档案结构Tik分割。Pix2SeqV2为四个视觉任务设计了统一的像素到序列接口,即目标检测、实例分割、关键点检测和图像字幕。GLIP通过用单词区域对齐取代经典的分类,巧妙地将目标检测重新表述为短语接地。这种新格式允许对检测和接地数据进行联合训练,显示出对各种对象级识别任务的强大可移植性。然而,GLIP[54]不支持其他模式中的提示,如图像和注释,也不支持视频级跟踪任务。在跟踪目标方面,Unicorn提出了SOT、VOS、MOT和MOTS的统一解决方案,在8个具有相同模型权重的基准测试上实现了卓越的性能。然而,Unicorn在训练和推理过程中仍然难以处理多样化的标签词汇表。在这项工作中,我们为10个实例感知任务提出了一种通用的提示引导架构,同时克服了GLIP和Unicorn的缺点。
摘要
所有的实例感知任务都旨在寻找由类别名称、语言表达式和目标注释等查询指定的某些对象,但是这个完整的字段被分成了多个独立的子任务。
在这项工作中,我们提出了下一代的通用实例感知模型,称为UNINEXT。UNINEXT将不同的实例感知任务重新制定为统一的对象发现和检索范式,并且可以通过简单地改变输入提示来灵活地感知不同类型的对象。
这种统一的公式带来了以下好处:
(1)来自不同任务和标签词汇表的大量数据可以被利用来联合训练通用实例级表示,这对于缺乏训练数据的任务特别有益。
(2)统一模型具有参数效率,并且可以在同时处理多个任务时节省多余的计算。UNINEXT在10个实例级任务的20个具有挑战性的基准测试中表现出色,包括经典图像级任务(目标检测和实例分割)、视觉和语言任务(引用环表情理解和分割)以及6个视频级目标跟踪任务。
介绍
由于上述所有任务都旨在感知某些属性的实例,因此我们将它们统称为实例感知。
但实例感知任务通常会分成很多子任务,分散的设计理念带来以下缺点:
1)独立设计阻碍模型在不同任务和领域之间学习和共享通用知识,导致冗余参数。
2)不同任务之间相互协作的可能性被忽略了。(
3)受固定大小分类器的限制,传统的对象检测器难以在具有不同标签词汇的多个数据集上联合训练,并在推理过程中动态更改对象目录以进行检测。
我们首先根据不同的输入提示将10个实例感知任务重组为三种类型:
(1)类别名称作为提示(对象检测、实例分割、VIS、MOT、MOTS)。
(2)语言表达式作为提示(REC、RES、R-VOS)。
(3)引用注释作为提示(SOT、VOS)。
UNINEXT首先在提示的引导下发现N个对象提案,然后根据实例提示匹配分数从提案中检索最终实例。
为了处理不同的提示方式,我们采用了一个提示生成模块,该模块由一个参考文本编码器和一个参考视觉编码器组成。然后使用早期融合模块来增强当前图像的原始视觉特征和提示嵌入。该操作实现了深度信息交换,并为后面的实例预测步骤提供了高度判别的表示。考虑到灵活的查询到实例方式,我们选择了基于Transform的对象解码器作为实例解码器。具体来说,解码器首先生成N个实例提案,然后使用提示从这些提案中检索匹配的对象。这种灵活的检索机制克服了传统固定大小分类器的缺点,并实现了对来自不同任务和领域的数据的联合训练.
贡献
为通用实例感知提出了一个统一的提示引导公式,将以前分散的实例级子任务重新组合成一个整体。
受益于灵活的对象发现和重新分类范式,UNINEXT可以在不同的任务和领域进行训练,而不需要特定于任务的头部。
UNINEXT使用具有相同模型参数的单个模型,在来自10个实例感知任务的20个标尺长度基准上实现了卓越的性能。
方法
感知任务分类:对象检测、实例分割、MOT、MOTS和VIS 以类别名称作为提示 查找特定类的所有实例。REC、RES和R-VOS 利用表达式作为提示 来定位某个目标。SOT和VOS 使用第一帧中给出的注释 作为预测被跟踪目标轨迹的提示。
如图2所示,UNINEXT由三个主要组成部分组成:
(1)提示生成(2)图像提示特征融合(3)对象发现和检索。
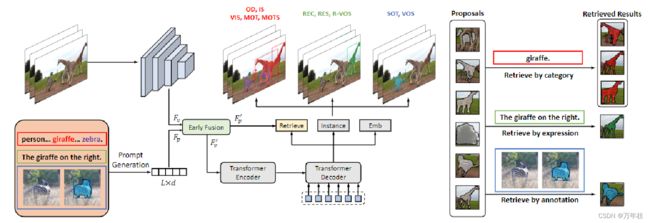
1.提示生成
label为提示:class-name, 例如“person. bicycle. … . toothbrush”for COCO, 进入 text encoder;;
expression为提示:原expression 进入 text encoder;
视频中的注释为提示:首先以引用框架上的目标位置为中心裁剪目标框面积为4倍的模板。然后将模板调整为256×256的固定大小。为了引入更精确的目标信息,将一个名为目标先验的额外通道连接到模板图像,形成4通道输入。在更详细的情况下,目标先验在目标区域上的值为1,否则为0。然后将模板图像与target先验一起传递给参考视觉编码器Encref V,获得分层特征金字塔{C3, C4,C5,C6}。对应的空间大小为32×32、16×16、8×8和4×4。为了保持精细的目标信息,并以与其他任务相同的格式得到提示嵌入,应用了合并模块。即首先将所有级别的特征上采样到32×32,然后加和,并扁平化为最终的提示嵌入 F p ∈ R 1024 × d F_p \in R^{1024×d} Fp∈R1024×d

2.图像提示特征融合
将现有图像输入到另一个visual encoder 获取结构化的视觉特征 F v F_v Fv;
考虑结合原始视觉特征的提示效果,通过图像上下文增强原始提示嵌入,进行早期融合;
具体来说,使用双向交叉注意力从不同的输入中检索信息,然后将检索到的表示添加到原始特征中;
F p 2 v , F v 2 p = B i − X A t t ( F v , F p ) F_{p2v},F_{v2p}=Bi−XAtt(F_v,F_p) Fp2v,Fv2p=Bi−XAtt(Fv,Fp) F v ′ = F v + F p 2 v ; F p ′ = F p + F v 2 p F_v^′=F_v+F_{p2v};F_p^′=F_p+F_{v2p} Fv′=Fv+Fp2v;Fp′=Fp+Fv2p

3.目标发现和检索
有了判别的视觉和提示表示,下一个关键步骤是将输入特征转换为各种感知任务的实例。
UNINEXT采用了可变形DETR提出的编码器-解码器架构,因为它具有灵活的查询到实例的方式。
Encoder 输入为 结构化的prompt-aware 视觉信息,借助高效的多尺度可变形自注意力,可以充分交换来自不同尺度的目标信息,为后续的实例解码带来更强的实例特征;最后输出中间变量和一个辅助预测头生成N个得分最高的初始的参考点;
Decoder将加强的多尺寸视觉特征、N个参考点和N个目标queries作为输入,Decoder最后又一群预测头来生成最后的实例预测(一个实例包括 boxes 和 masks of the targets)。
query生成策略:
静态queries:nn.Embedding(N,d);
动态queries:对增强的prompt features进行pooling操作获取全局特征,再进行N次。
静态queries表现更好,可能是因为其包含更丰富的信息而且训练时更稳定。
F p ′ F_p^′ Fp′代表prompt embedding。
借助可变形注意力,对象查询可以有效地检索提示感知的视觉特征,并学习强实例嵌入 F i n s = R N × d F_ins=R^{N×d} Fins=RN×d。
在解码器的最后,利用一组预测头来获得最终的实例预测(同时包含boxes和masks)。
同时引入了一个嵌入头,用于将当前检测到的结果与MOT、MOTS和VIS中先前的轨迹相关联。
最后挖掘了N个潜在的实例提案,如图中灰色掩码。
进一步挑选匹配的proposals。
给定早期融合后的提示嵌入 F p ′ F_{p}^′ Fp′,将每个类别名称 或 expression/annotation(avg-pool)的嵌入作为权重矩阵W。
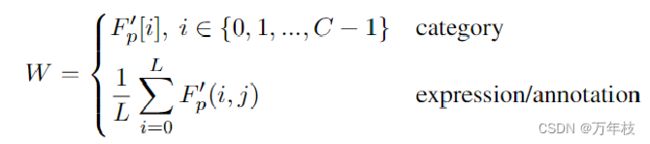
实例提示匹配分数S 为 目标特征和转置权重矩阵的矩阵乘法 S = F i n s W T S=F_{ins}W^T S=FinsWT。
与以前的固定大小分类器不同,所提出的检索头通过提示实例匹配机制选择对象。这种灵活的设计使UNINEXT能够在来自不同任务的具有不同标签词汇表的庞大数据集上联合训练,学习通用实例表示。
训练
整个训练过程包括三个连续的阶段:
(1)通用感知预训练(2)图像级联合训练(3)视频级联合训练
(1) 具体来说,在大规模目标检测数据集Objects365上预训练UNINEXT,以学习关于对象的通用知识;
模型在 32 A100 GPUs 上进行 Objects365 预训练,在16 A100 GPUs 进行其他阶段训练。
推理
对于类别引导的任务,UNINEXT预测不同类别的实例并将它们与之前的轨迹相关联。该关联以在线方式进行,并且纯粹基于以下[79,105]的学习实例嵌入。对于表达式引导和注释引导的任务,我们直接在给定提示下选择匹配分数最高的对象作为最终结果。与以前受离线方式或复杂后处理限制的工作[94,104]不同,我们的方法简单、在线、post-processing free(免后处理)。
结果
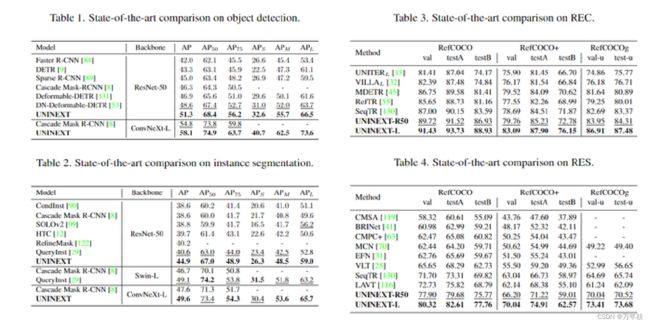
可以看出,效果很好,对于RES指标确实变高。
展望
我们提出了下一代的通用实例感知模型UNINEXT。UNINEXT首次将10个实例感知任务与提示引导的对象发现和检索范式相结合。广泛的实验表明,UNINEXT在具有相同模型参数的单个模型的20个具有挑战性的基准上实现了卓越的性能。我们希望UNINEXT可以作为未来实例感知研究的坚实基线.
相关
IDOL | ECCV2022
In Defense of Online Models for Video Instance Segmentation, ECCV, 2022 (Oral).
在线视频实例分割新范式
Unified-IO文章首先分析了在VIS任务中,offline算法往往领先同时期online算法达到 10AP 左右的现象,并深入分析了导致 online 模型和 offline 模型的巨大性能差距的原因,提出了一个基于contrastive learning的 online 算法:IDOL。该算法可以学习更具有区分度的instance embedding,并且充分利用了视频的历史信息来保证算法的稳定性,将online模型表现提高到一个与offline模型相当甚至更高的水平上。IDOL 在 YouTube-VIS 2019 上达到了 49.5 AP,分别超越了之前的最优的 online / offline 算法 13.2 / 2.1 AP。在更有挑战的OVIS数据集上,IDOL 更是达到了30.2 AP,超越了之前的最优算法一倍。而在最近举行的 CVPR 2022 Large-Scale Video Object Segmentation Challenge, Video Instance Segmentation Track 上,IDOL也超越了一众 online/offline 模型,取得了第一名。

OFA
OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
URL: https://proceedings.mlr.press/v162/wang22al/wang22al.pdf
代码 URL: https://github.com/OFA-Sys/OFA
文中认为大一统模型需要具备的 3 个性质
Task-Agnostic (TA):统一的任务表示,以支持不同类型的任务,包括分类、生成、自监督任务等,并且对预训练或微调兼容
Modality-Agnostic (MA):在所有任务之间共享统一的输入和输出表示,以处理不同的模式
Task Comprehensiveness (TC):足够的任务种类,以稳健地积累泛化能力