Hadoop三大核心组件,hadoop原理
Hadoop的三大核心组件分别是:
- HDFS(Hadoop Distribute File System):hadoop的数据存储工具。
- YARN(Yet Another Resource Negotiator,另一种资源协调者):Hadoop 的资源管理器。
- Hadoop MapReduce 分布式计算框架
一.HDFS
1.HDFS概述
HDFS是google三大论文之一的GFS的开源实现,是一个高度容错性的系统,适合部署在廉价的机器上的,适合存储海量数据的分布式文件系统。
在HDFS中,1个文件会被拆分成多个Block,每个Block默认大小为128M(可调节)。这些Block被复制为多个副本,被存放在不同的主机上,这也保证了HDFS的高容错性。
2.HDFS架构
下图展示了HDFS的基本架构

HDFS采用Master/slave架构模式,1一个Master(NameNode/NN) 带 N个Slaves(DataNode/DN)。
从内部来看,数据块存放在DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
NN:
1)负责客户端请求的响应
2)负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN:
1)存储用户的文件对应的数据块(Block)
2)要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
3.HDFS读写流程
写数据流程
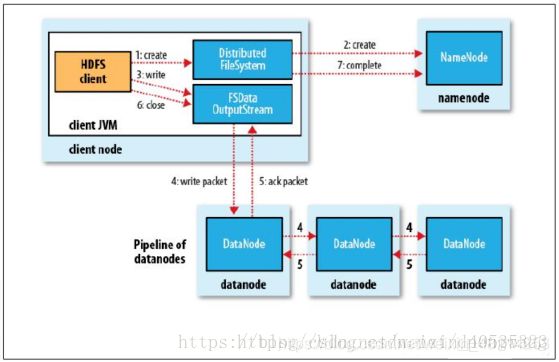
- 客户端Client向远程的Namenode发起RPC请求.
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录, 否则会让客户端抛出异常
- 当客户端开始写入文件的时候, 客户端会将文件切分成多个packets, 并在内部以数据队列“data queue( 数据队列) ”的形式管理这些packets, 并向Namenode申请blocks, 获取用来存储replications的合适的datanode列表, 列表的大小根据Namenode中replication的设定而定;
- 开始以pipeline( 管道) 的形式将packet写入所有的replications中。 客户端把packet以流的方式写入第一个datanode, 该datanode把该packet存储之后, 再将其传递给在此pipeline中的下一个datanode, 直到最后一个datanode, 这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet( 确认队列) , 在pipeline里传递至客户端, 在客户端的开发库内部维护着”ack queue”, 成功收到datanode返回的ack packet后会从”ack queue”移除相应的packet。
- 如果传输过程中, 有某个datanode出现了故障, 那么当前的pipeline会被关闭, 出现故障的datanode会从当前的pipeline中移除, 剩余的block会继续剩下的datanode中继续以pipeline的形式传输, 同时Namenode会分配一个新的datanode, 保持replications设定的数量。
- 客户端完成数据的写入后, 会对数据流调用close()方法, 关闭数据流;
- 只要写入了dfs.replication.min的副本数( 默认为1),写操作就会成功, 并且这个块可以在集群中异步复制, 直到达到其目标复本数(replication的默认值为3),因为namenode已经知道文件由哪些块组成, 所以它在返回成功前只需要等待数据块进行最小量的复制。
读数据流程
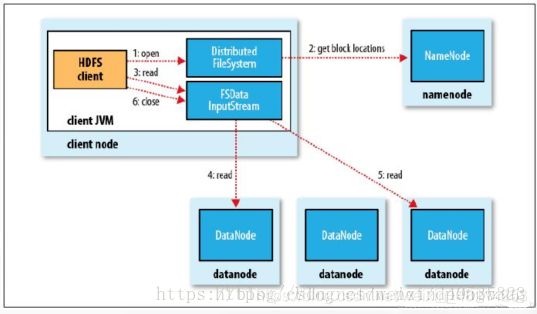
- 使用HDFS提供的客户端Client, 向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表, 对于每个block, Namenode都会返回有该block拷贝的DataNode地址;
- 客户端Client会选取离客户端最近的DataNode来读取block; 如果客户端本身就是DataNode, 那么将从本地直接获取数据;
- 读取完当前block的数据后, 关闭当前的DataNode链接, 并为读取下一个block寻找最佳的DataNode;
- 当读完列表block后, 且文件读取还没有结束, 客户端会继续向Namenode获取下一批的block列表;
- 读取完一个block都会进行checksum验证, 如果读取datanode时出现错误, 客户端会通知Namenode, 然后再从下一个拥有该block拷贝的datanode继续读。
从上面的流程我们可以更清晰地理解HDFS各个组件的作用:namenode负责管理,不接触数据,datanode负责存储数据,在写数据时,每份数据复制多个副本以pipeline的方式在datanode中流动。读数据时,namenaode的作用只是提供datanode的信息,又客户端自己从datanode读取。
可以看出,HDFS的一个特点是,适合一次写入多次存取的场景。
另外还有一个小知识点,在实际应用中存储数据时,数据的第一份副本存放在离客户端最近的一台主机上,第二份副本存放在与第一台主机不同机架的主机上,第三个副本存放在与上一个副本同一个机架的不同主机上。这样也是保证了HDFS的高容错性。
二.YARN和MapReduce
为什么要把这两个放到一块说呢,因为YARN可以说是为了弥补MRv1的缺陷而诞生的,所以两者放到一块说比较合适
1.什么是MapReduce
Hadoop的MapReduce是对google三大论文的MapReduce的开源实现,实际上是一种编程模型,是一个分布式的计算框架,用于处理海量数据的运算。
2.MapReduce的流程
MapReduce主要由下面几个过程组成,理解了这几个过程,基本上就可以理解MapReduce了
先上一张图再说
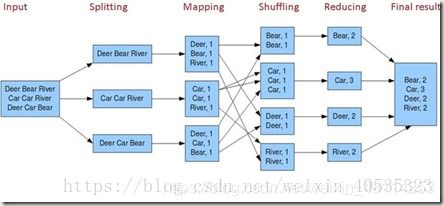
- input:不用说,就是输入数据,在编程中会有Textformat方法专门处理输入。
- splitting:将数据分片,一般来说这个片和HDFS的分块大小是一致的,默认为128M,但是这个大小也可以调节。(https://blog.csdn.net/dr_guo/article/details/51150278这篇博客对分片理解的很到位,可以看一下)。
- record reader:record reader通过输入格式将输入split解析成记录。record reader的目的只是将输入数据解析成记录,但不负责解析记录本身。它将数据转化为键/值(key/value)对的形式,并传递给mapper处理。通常键是数据在文件中的位置,值是组成记录的数据块。以图片中的程序(其实也就是wordcount)为例,spliting将输入文本以行为单位分片,record reader把分片结果转化为为多个以行偏移量为key,对应内容为value的key/value对,将这些key/value对作为参数输入到mapping中
- mapping:处理record reader解析的每个键/值对来产生0个或多个新的key/value对结果。key/value的选择对MapReduce作业的完成效率来说非常重要。key是数据在reducer中处理时被分组的依据,value是reducer需要分析的数。上图程序中,将输入的value进行解析,产生多个以单词为key,单词数量(其实也就是1)为value的新key/value对,并输出。
- shuffing:
数据从map中出来到进入reduce之前称为shuffle阶段,shuffle的处理任务:将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
1)、maptask收集我们的map()方法输出的k、v对,放到内存缓冲区中
2)、从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3)、多个溢出文件会被合并成大的溢出文件
4)、在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5)、reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6)、reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7)、合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
备注:Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M - reduce:reduce阶段是一个归约过程,实现单词的计数。最后,得到整个文档的词频统计。
MR过程中的数据流向:一个文件在HDFS中是分布存储在不同节点的block中,每一个block对应一个Mapper,每一条数据以K,V的形式进入一个map()方法,map()方法中对数据进行处理(数据筛选,业务逻辑以及分区),再将处理结果以K,V的形式写入环形缓冲区,一个Mapper对应一个context,context对写入的数据按key进行聚合、排序、归约。context的大小默认为100M,当context容量达到80%或Mapper处理结束时,context会向外溢出,形成许多小文件,小文件为一个K和许多V的集合。处理完成后,这些文件会发送到Reducer所在节点,在该节点的context中,会对不同节点发送过来的数据按key进行再一次的聚合、排序和归约,最后进入Reducer,在reduce方法中对同一个
3.MapReduce1.x的架构
MapReduce的架构模式分为两个阶段,MR1.x和MR2.x时期,先说MR1.x,上一张图
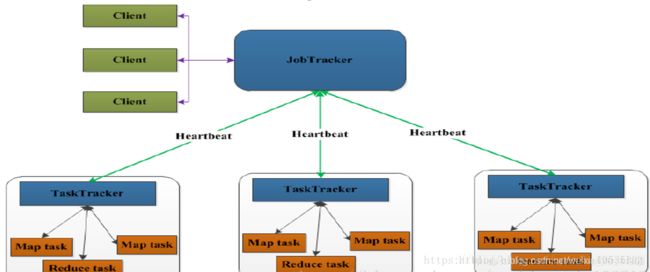
MapReduce采用Master/Slave架构,1个JobTracker带多个TaskTracker
1)JobTracker: JT
- 作业的管理者 管理的
- 将作业分解成一堆的任务:Task(MapTask和ReduceTask)
- 将任务分派给TaskTracker运行
- 作业的监控、容错处理(task作业挂了,重启task的机制)
- 在一定的时间间隔内,JT没有收到TT的心跳信息,TT可能是挂了,TT上运行的任务会被指派到其他TT上去执行
2)TaskTracker: TT
- 任务的执行者 干活的
- 在TT上执行我们的Task(MapTask和ReduceTask)
- 会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT
3)MapTask
- 自己开发的map任务交由该Task处理
- 解析每条记录的数据,交给自己的map方法处理
- 将map的输出结果写到本地磁盘(有些作业只仅有map没有reduce==>HDFS)
4)ReduceTask
- 将Map Task输出的数据进行读取
- 按照数据进行分组传给我们自己编写的reduce方法处理
- 输出结果写到HDFS
可以看出来,这种架构模式有很大的缺陷:
1、只有一个JobTracker,容易出现单点故障
2、JobTracker同时负责资源管理和作业调度,节点的工作压力巨大
3、可扩展性差
出现了缺陷,就该寻找解决的办法,这时候,我们的YARN就闪亮登场了。
4.什么是YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。通过YARN,不同计算框架可以共享同一个HDFS集群上的数据,享受整体的资源调度。
5.YARN的基本架构
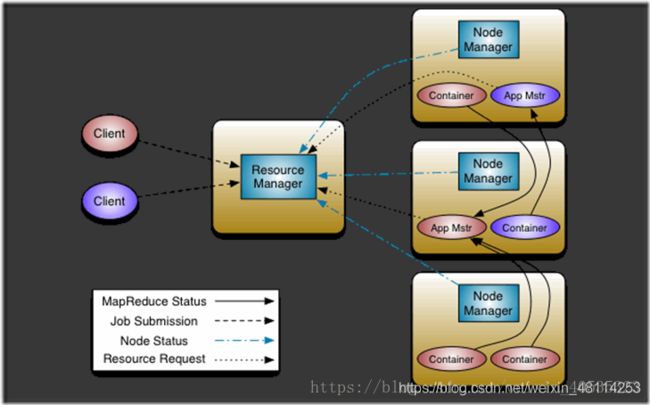
1)ResourceManager: RM
- 整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度
- 处理客户端的请求: 提交一个作业、杀死一个作业
- 监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理
- NodeManager: NM
- 整个集群中有多个,负责自己本身节点资源管理和使用
- 定时向RM汇报本节点的资源使用情况
- 接收并处理来自RM的各种命令:启动Container
- 处理来自AM的命令
- 单个节点的资源管理
- ApplicationMaster: AM
- 每个应用程序对应一个:MR、Spark,负责应用程序的管理
- 为应用程序向RM申请资源(core、memory),分配给内部task
- 需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面
- Container
- 封装了CPU、Memory等资源的一个容器
- 是一个任务运行环境的抽象
- Client
- 提交作业
- 查询作业的运行进度
- 杀死作业
6.YARN的工作流程
1、用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster命令、用户程序等
2、resourceManager为该应用程序分配第一个container,并与对应的nodeManager通信,要求它在这个container中启动应用程序的ApplicationMaster
3、ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复4~7
4、ApplicationMaster采用轮询的方式通过RPC协议向resourceManager申请和领取资源
5、一旦ApplicationMaster申请到资源后,便与对应的Nodemanager通信,要求它启动任务。
6、NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7、各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态
8、应用程序运行完成后,ApplicationMaster向resourceManager注销并关闭自己
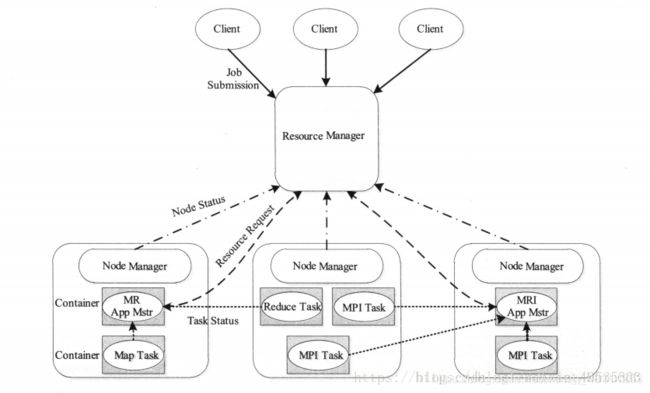
6.MapReduce2.x的架构
YARN将MapReduce1.x中的JobTracker拆分为两部分:ResourceManager和Applicationaster。大大减轻了ResourceManager上的资源消耗与负担,下面三MR2.x的架构图。
本文转载至:https://blog.csdn.net/weixin_40535323/article/details/82025442