【C语言】字符函数和字符串函数
函数介绍
strlen
![]()
- 字符串已经 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前面出现的字符个数(不包含 ‘\0’ )。
- 参数指向的字符串必须要以 ‘\0’ 结束。
- 注意函数的返回值为size_t,是无符号的( 易错 )
代码一:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
代码二:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
代码三:
#define _CRT_SECURE_NO_WARNINGS
#include 这里如果按数学中的计算来看,3-6原本为-3,小于0输出<=,但是大家一定要注意,strlen函数的返回值类型是size_t(无符号整型),同时无符号数减去无符号数得到的是无符号数,因此判断结果为>0;
![]()
![]()
strcpy
![]()
- 源字符串必须以 ‘\0’ 结束。
- 会将源字符串中的 ‘\0’ 拷贝到目标空间。
- 目标空间必须足够大,以确保能存放源字符串。
- 目标空间必须可变。
strcpy的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include 
代码一:
#define _CRT_SECURE_NO_WARNINGS
#include 代码二:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
代码三:
#define _CRT_SECURE_NO_WARNINGS
#include 
代码四:
#define _CRT_SECURE_NO_WARNINGS
#include strcat
![]()
- 源字符串必须以 ‘\0’ 结束。
- 目标空间必须有足够的大,能容纳下源字符串的内容。
- 目标空间必须可修改。
- strcat字符串不能自己给自己追加,会陷入无限追加。
strcat的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
strcat函数的原理:从目的地字符串的 ‘\0’ 的位置开始追加,把 ‘\0’ 覆盖掉一直追加,直到将源头的字符串内容全部拷贝到目的地,包括 ’\0‘ 。
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
strcmp
下面演示一种错误的字符串比较方式:
if ("abcdef" == "bcdefg") //这里比较的是两个字符串首字符的地址,而不是字符串的内容
这种比法语法上是没有任何问题的,但是这个代码比的不是两个字符串的内容。原因是这两个字符串在作为表达式的时候,它们两的值是第一个字符的地址,因此在用==号比的时候比的其实是这两个字符串的首个字符的地址是否相等,并没有比较两个字符串的内容。
![]()
- 第一个字符串大于第二个字符串,则返回大于0的数字。
- 第一个字符串等于第二个字符串,则返回0。
- 第一个字符串小于第二个字符串,则返回小于0的数字。
- 温馨提示:VS系统下默认三个返回值分别为:-1,0,1。
strncpy
大家可能发现了 strcpy,strcat,strcmp 这三个函数在使用时对源字符串没有长度限制,几乎是将源字符串的内容全部进行操作。在VS编译器中的这些函数显得不安全了,因此VS会提醒你在其后加上 _s ,或者在首行加上 #define _CRT_SECURE_NO_WARNINGS。
由于这些原因,C语言又引入了 strncpy,strncat,strncmp 等长度受限制的一组相对来说比较安全的函数。
![]()
- 拷贝num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加\0,直到num个。
strncpy的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
strncat
![]()
- strncat 函数再追加完后自动会在其后补上一个 \0。
- 如果输入的追加长度大于源字符串中的字符个数,那么在追加完源字符串(包括 \0 )后不会再凑剩下的字符了。
- strncat 可以自己给自己追加。
#define _CRT_SECURE_NO_WARNINGS
#include 
strncmp
![]()
- 比较到出现另个字符不一样或者一个字符串结束或者num个字符全部比较完。
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
当然在VS中 strcpy_s,strcat_s,strcmp_s 也可以用来作为长度受限的函数。
strstr
![]()
strstr的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include 若目标字符串中出现多次源字符串的内容,返回第一次源字符串出现的位置。
![]()
strchr
和 strstr 函数比较类似的函数,用于找出一个字符在字符串中第一次出现的位置。
strchr 基本用法:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
strrchr
strrchr 函数用于找出一个字符在字符串中最后一次出现的位置。
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
strtok
![]()
- sep参数是个字符串,定义了用作分隔符的字符集合。
- 第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回 NULL 指针。
strtok函数的基本用法:
#define _CRT_SECURE_NO_WARNINGS
#include 
strerror
![]()
- 返回错误码,所对应的错误信息。
strerror函数的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include 
通过以上的例子,我们可以将 strerror 函数看作将错误码(0,1,2)翻译为错误信息。
上例的代码只是为了方便演示功能才举出的例子,事实上C语言的库函数在调用失败的时候,会将一个错误码存放在一个叫 errno 的变量中,当我们想知道在调用库函数是发生了什么错误信息,就可以将 errno 中的错误码翻译成错误信息。
演示打开读取关闭文件的过程,代码示例如下:
#define _CRT_SECURE_NO_WARNINGS
#include 由于我的电脑中不存在这个文件,因此运行结果如下:
![]()
perror
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
memcpy
![]()
- 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
- 这个函数在遇到 ‘\0’ 的时候并不会停下来。
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
- num的单位是字节。
- void*:通用类型的指针,可以接受任意类型的地址 。但是这类指针不能直接进行解引用和±运算。由于 memcpy 函数的设计者不知道未来程序员使用memcpy拷贝什么类型的数据,因此使用void* 来设计这个函数。
memcpy函数的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include 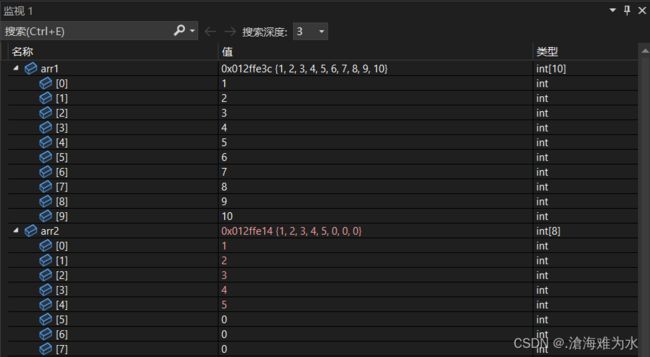
不光是 int 类型的数据可以,float 类型的数据同样也行。
memmove
![]()
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理。
memmove函数的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
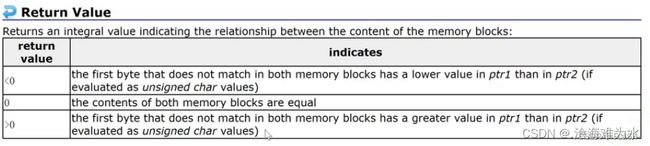
memcmp

- 比较从ptr1和ptr2指针开始的num个字节。
- 返回值如下:
memcmp函数的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include 
memset

- memset是以字节为单位来进行设置,使用时要注意。
memset函数的基本使用:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
库函数的模拟实现
模拟实现strlen
方法一:计数器
int my_strlen(const char* str) //const 放在*的左边保护的是指针所指向的内容
{
int count = 0;
while (*str)
{
count++;
str++;
}
return count;
}
int main()
{
char arr[] = "hello world";
int len = my_strlen(arr);
printf("%d", len);
return 0;
}
方法二:递归(不创建临时变量,求字符串长度)
#define _CRT_SECURE_NO_WARNINGS
#include 方法三:指针-指针
#define _CRT_SECURE_NO_WARNINGS
#include 模拟实现strcpy
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
模拟实现strcat
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
模拟实现strstr
strstr 函数的模拟实现也是数据结构中串的匹配实现的暴力算法:BF算法。
为了使匹配字符串的过程中,如果发生匹配失败,能够让str1指向目标字符串中字符的下一个字符,str2能够重新回到要找的字符串开始位置,我们需要使用双指针,一个用来记住当前位置,一个来方便匹配过程中指针的移动。

#define _CRT_SECURE_NO_WARNINGS
#include ![]()
模拟实现strcmp
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
模拟实现memcpy
#define _CRT_SECURE_NO_WARNINGS
#include 
模拟实现memmove
在我们模拟之前我们不妨想想这个问题,在重叠部分进行拷贝时,应该考虑dest指向的字符串与src指向的字符串的位置关系来确定如何使得拷贝src字符在未被拷贝之前不被修改,因此我们需要进行讨论:

经过分析,我们可以得出情况一将采用(后->前),情况二和三采用(前->后)来进行拷贝是合理的,因此代码示例如下:
#define _CRT_SECURE_NO_WARNINGS
#include ![]()
在这里需要注意的是:在C语言中,memcpy 用来拷贝不重叠的部分,重叠的部分交给 memove来做,如果 memove可以完成100%,那么memcpy可以完成60%。但在VS中比较特殊的是,memcpy可以进行重叠部分的拷贝,memove和memcpy都可以完成100%。
字符分类函数

以上函数在使用时应引用头文件
举几个函数使用的例子:
#define _CRT_SECURE_NO_WARNINGS
#include 
字符转换函数

- 经过实验貌似这两个函数只能对单个字符进行大小写转换。
函数使用示例如下:
#define _CRT_SECURE_NO_WARNINGS
#include 
写出一个代码将一句话转换为全小写输出:
#define _CRT_SECURE_NO_WARNINGS
#include 
