RocketMQ-DLedger架构-实践-小米
简介: DLedger架构作为RocketMQ 4.5 推出的全新架构,稳定性有保障。小米的在线核心业务规模巨大,需要很高的可靠性保证,因此选择了DLedger架构。小米希望用数据说话,积极地拥抱社区发展并认为大规模落地DLedger既是挑战,也是机会。那么,我们一起看看RocketMQ DLedger架构在小米的大规模实践。

本文作者:邓志文,小米研发工程师,Apache RocketMQ Committer
小米消息中间件选型
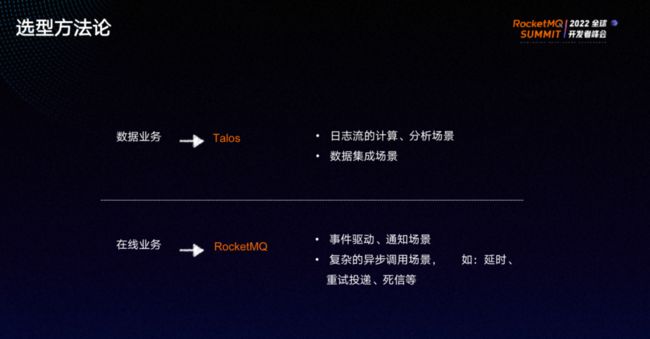
小米内部的业务场景可分为两类,分别是数据业务和在线业务。
其中数据业务包括日志流的计算、分析场景以及数据集成场景,一般使用内部自研的消息队列Talos。在线业务包括事件通知、订单以及复杂的异步调用场景,比如延时消息、重试投递、死信等,一般使用RocketMQ。

DLedger架构是RocketMQ 4.5 推出的全新架构,稳定性有保障。小米的在线核心业务规模巨大,需要很高的可靠性保证,因此我们最终选择了DLedger架构。小米希望用数据说话,积极地拥抱社区发展,并且我们认为大规模落地DLedger既是挑战,也是机会。
Dledger内核与优化
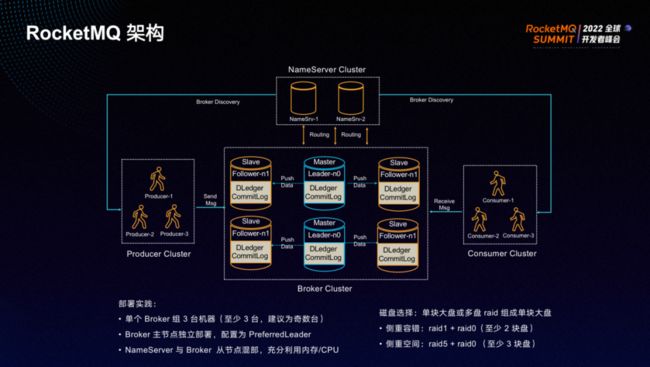
DLedger架构与主从架构的主要区别在于 broker。我们的实际部署中,单个Broker组部署3台机器(建议部署奇数台),主节点单独部署,从节点与 NameServer 混合部署,通过 raid 方式将多块磁盘组成单块大盘。

DLedger架构有两个核心模块:
①副本同步:主节点向从节点通过异步发送 push 请求。
②自动选主:主节点定时向从节点发送心跳,若从节点在指定时间内没有收到心跳则触发重新选主。
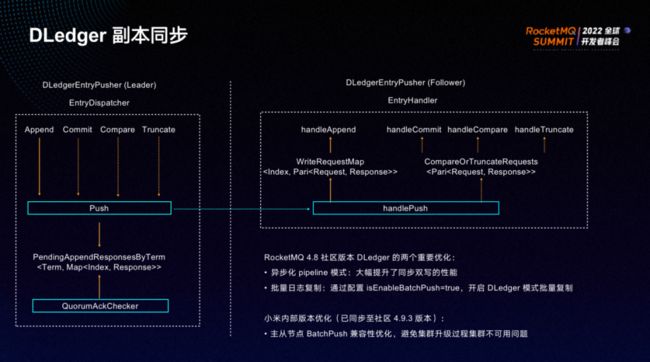
副本同步的过程如上图所示:同步时 leader 节点会向从节点发送 push 请求,要求同步数据。
RocketMQ4.8 社区版本对DLedger做了以下两个重要优化:
- 异步化 pipeline 模式:大幅提升了同步双写的性能。
- 批量日志复制:支持批量同步。但是批量同步会存在兼容性问题,从单条升级到批量的情况下会出现不兼容。
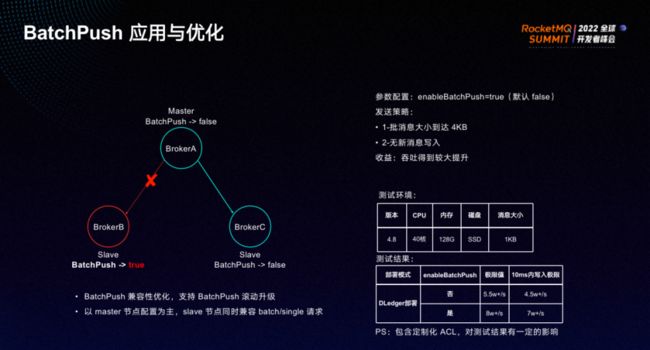
小米内部针对批量同步进行了优化,做了兼容性改造:主从节点BatchPush兼容性优化,避免集群升级过程中集群不可用。具体优化内容为:BatchPush兼容性优化,支持了BatchPush滚动升级;以master节点配置为主,slave节点同时兼容batch/single请求。
我们对 batch 同步做了性能测试,测试环境如上图右侧所示。测试结果为,开启Batch同步前后,极限值从5.5w/s提高至8w/s,10ms内写入极限从4.5w/s提升至7w/s。
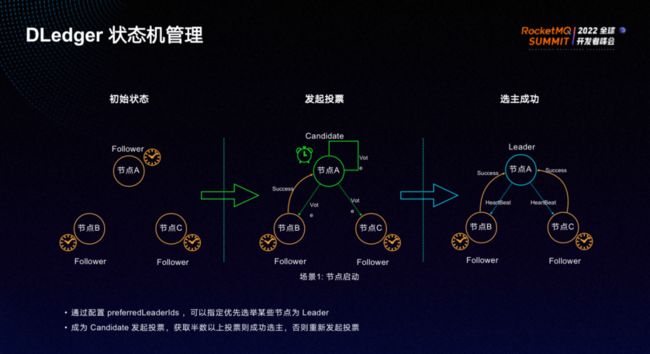
DLedger选举流程如上图所示。通过配置preferredLeaderlds可以指定优先选举某些节点为leader。由Candidate发起投票,获取半数以上投票则成为主节点,否则重新发起投票。
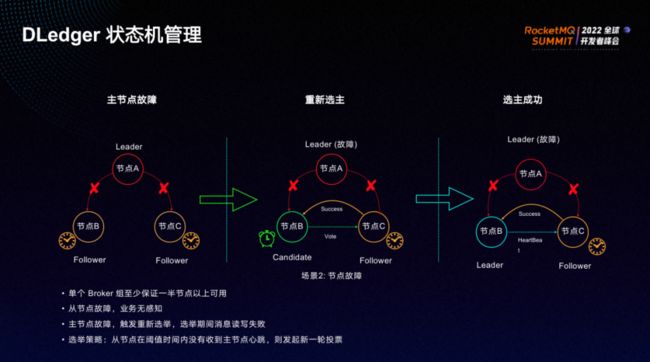
故障情况下,故障恢复过程如上图所示。
集群必须保证一半以上节点可用。如果从节点出现故障,则业务无感知;如果主节点故障,则重新触发选举。主节点一旦发生故障,则会立即停止与从节点的心跳, 从节点会变为Candidate状态,发起新一轮投票选举,从剩余存活的节点中选出新的 master 节点。

假设新的主节点并不是PreferredLeader,则会检测Leader与PreferredLeader之间的水位差距。如果两者之间副本写入差距小于1000条,则会发起LeaderShipTransfer,将leader的位置转移给PreferredLeader,此时Leader节点不再接收数据写入。
Follower节点接收到LeaderShipTransfer请求后,将节点状态设置为Candidate,不再接收副本同步。
当PreferredLeader被设置为Candidate时,节点副本同步进度将落后于Leader节点,会导致Candidate发起投票失败。原因为副本同步落后,同时该节点term值大于leader节点,无法重新置为Follower,节点始终处于Candidate状态。
我们对此进行了优化,在PreferredLeader节点接收到LeaderShipTransfer请求后,会跟上 leader 节点副本同步的进度,否则超时失败,避免了被配置为 PreferredLeader的从节点数据不同步的问题。
DLedger架构实践经验
1.业务影响力
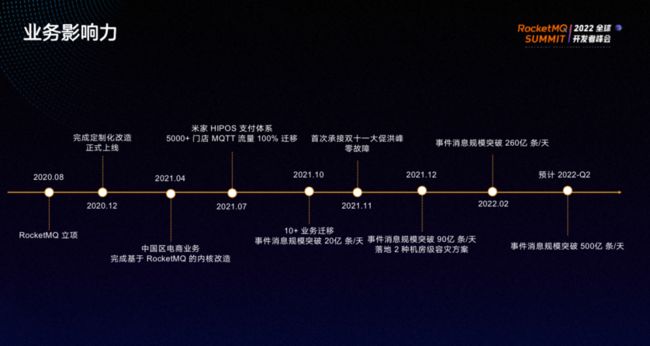
从2020年8月RocketMQ正式立项到现在,消息规模已突破到 260 亿条/天,预计2022-Q2可达 500 亿/天。

截至目前,小米内部已将多种业务自维护中间件比如Notify、RabbitMQ等进行了替换。
2.性能优化

小米内部的很多业务场景都需要延时消息,然而,RocketMQ的延时消息与消息重试绑定,一旦客户端出现大量消费失败,会导致延时功能受到影响。
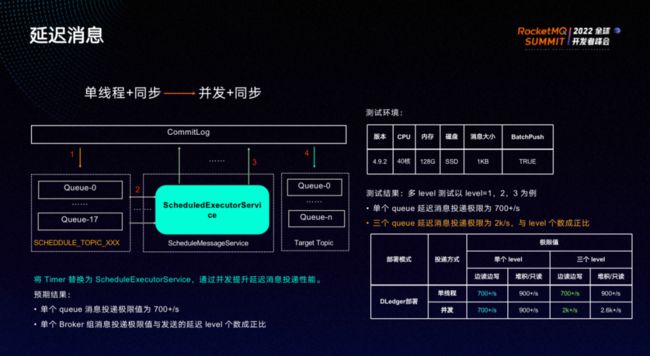
小米针对上述痛点进行了优化。
此前为一个线程处理18个level,level之间互相影响。因此,我们将Timer替换为ScheduledExecutorService,每一个线程负责一个level,使得level 之间不会互相影响。上图右下角表格显示,改造后的TPS依然较差,远不能满足业务团队的需求。

于是我们继续进行改造,通过异步方式投递消息,由多个线程处理一个 level ,大幅提升了延时消息的性能,比如边读边写的性能可达3.2w/s,相比于原先的700/s有了质的飞跃。
但是开启异步投递后将无法保证延时消息的顺序性。
3.功能拓展

开源RocketMQ只有固定级别的延时消息,无法满足业务场景灵活延时消息的需求。最终,我们通过插件的方式实现了任意延迟消息,方便兼容社区后续的延时消息,也可以轻松将其进行替换。
具体实现流程如下:所有延时消息都发送到统一的延时 topic 里,插件将 topic 里的消息拉到自己的 CommitLog 中,再通过异步线程将延迟消息写入 RocksDB。然后将延迟消息从RocksDB加载到时间轮,由时间轮将到期的消息投递给业务 topic 。
Pull Service基于Push消费拉取消息,可轻松对插件进行水平扩展,consumer实例数增加时,能够依赖 rebalance 特性实现自动负载均衡。另外,使用RocksDB做存储,依赖kv特性无需对延时消息做排序,降低了复杂度。延时消息也是RocketMQ里的一环,因此也需要很高的可靠性,所以我们基于DLedger实现了 3 副本,可靠性得到了很高的保证。
任意延迟消息已经在内部所有集群上线,业务规模庞大,性能和可靠性也得到了验证。

RocketMQ5.0 以前,主要的消费模式为Pull和Push。而它们本质上都是 pull 的模式,客户端需要与队列数做绑定,一个分区最多只能被一个客户端消费,一旦消费者数量大于分区数量,则会导致空转,有客户端无法消费到消息。同时,消费能力不同也会导致消息堆积。此外,如果机器特别多比如有1000台,则队列的分区也必须为1000个。一旦有业务进行升级,则1000 台机器都需要进行升级,耗时久,且升级时频繁上下线会对消费造成很大影响。
RocketMQ5.0推出的POP消费模式能在一定程度上解决上述痛点。该模式下,队列可被多个客户端消费,客户端无需进行 rebalance ,上下线也不会相互影响,消费更均衡。即使有1000 台机器,可能只需要几个分区、几个队列。
但RocketMQ5.0的POP模式依赖了内置的 level 延时,由于level不够精确,因此在客户端消费特别慢的场景下会出现消费重复的问题。此外,POP模式只能在PushConsumer里使用。
因此,我们对RocketMQ5.0的PoP模式进行了优化,使用秒级延时消息,并支持了PullConsumer场景。优化后的POP模式已在小米内部全集群上线,POP消费数量超10亿/日。

我们还基于Static Topic 实现了动态负载均衡。
集群负载变高以后需要进行扩容,但是需要人工进行运维,手动地将流量高的 topic 从旧节点上迁移至新节点。而基于Static Topic实现了动态负载均衡后,新的节点加入后能够自动将不同broker组上的流量进行均衡。
它包含两个级别的均衡策略:
- 磁盘均衡:按天级别统计 TPS和检测负载。RocketMQ中无法删除 topic,因此只要按TPS 统计,即可大概统计出不同节点磁盘的比例。
- TPS均衡:按小时统计TPS和检测负载。

如上图,有四个 broker组,不同 broker组之间的流量阈值设置为 5k/s,一旦超过 5k/s则需要做rebalance。新建两个 topic,其中topicA有3个队列,topicB有5个队列。
新建 topic 的分配策略为:先按TPS对Broker进行排序,再将Topic所有queue按照Broker顺序循环分配。
最终结果如上图:topicA的三个队列分别分配在BrokerA、BrokerB、BrokerC,topicB的五个队列分别分配在BrokerA(2个)、BrokerB(1个)、BrokerC(1个)、BrokerD(1个)。
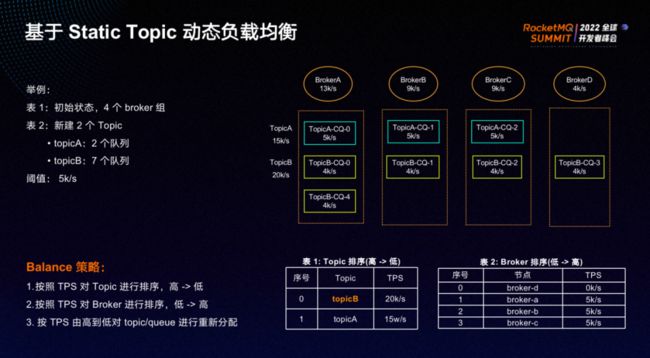
随着流量进入 topic ,势必会造成broker组之间出现流量差距。如上图,四个Broker的流量分别为13k、9k、9k、4k,已达 rebalance 阈值,因此需要进行 rebalance。
Balance 策略如下:
① 按照TPS对Topic进行由高到低的排序——排序结果为TopicB、TopicA。
② 按照TPS对Broker进行由低到高的排序——排序结果为BrokerD、BrokerA、BrokerB、BrokerC。
③ 按TPS由高到低对Topic/queue进行重新分配——首先分配TopicB,再分配TopicA。
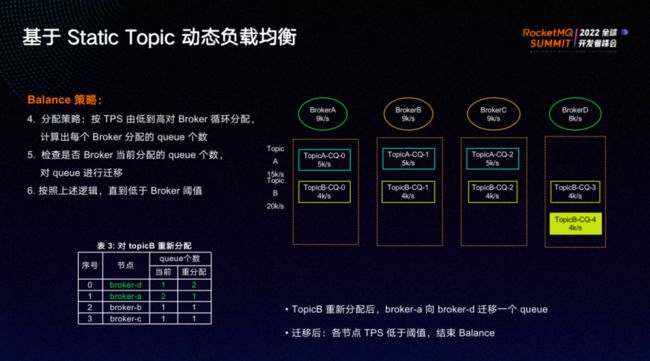
④ 分配策略:按 TPS 由低到高对 Broker 循环分配,计算出每个 Broker 分配的 queue 个数——结果为BrokerA上的一个队列移动至BrokerD。
⑤ 检查 Broker 当前分配的 queue 个数,对 queue 进行迁移。
⑥ 按照上述逻辑循环,直到流量低于 Broker 阈值。

我们对监控、日志、限流方面也分别进行了完善。
最开始我们使用小米内部的监控平台进行监控和报警。如今,小米已将Prometheus+Grafana链路打通,有了更丰富的图表组件,能够提供更丰富的查询和报警。
以往小米内部并没有对日志进行收集和监控,如果服务出现抖动,会在机器上查看日志。但是随着机器的增加,查看日志的成本也逐渐变大。此外,日志能够提早暴露某些问题,因此我们将ElasticSearch+Grafana打通,既统一了日志搜索的入口,又增加了日志的监控能力。
Broker虽然有自我保护,但仅针对集群级别。很多业务会使用相同的集群,为了保证不同集群、不同业务之间互不干扰,我们增加了 topic 级别的限流能力,不会影响 topic 正常的业务逻辑,只会在异常情况下触发限流,既保护了 broker也保护了其他业务。
4.灾备
小米的很多业务对可靠性要求特别高,因此需要多机房做灾备。

我们目前有三个灾备方案:
- 多机房多活。
- 跨机房互备。
- 双机房热备。
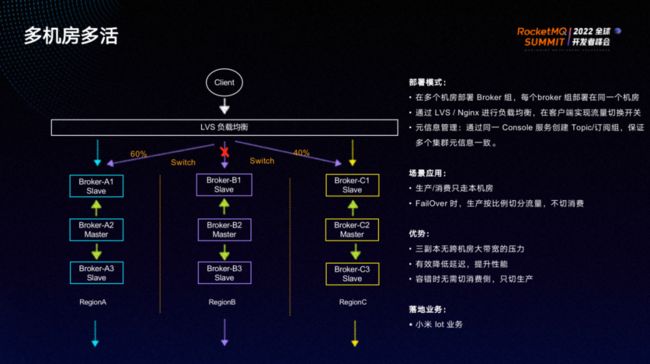
多机房多活:在多个机房部署Broker组,每个broker组部署在同一个机房。业务发送流量时,三个 broker组都正常工作。其中一个 broker组出现问题后,通过负载均衡自动将流量导到另外两个 broker组上。
该模式的缺陷为 broker 需要保留一定的 buffer 的,否则切流之后可能导致宕机。

跨机房互备:在多个机房部署broker组,每个broker组部署跨多个机房。有机房出现问题时,其他两个节点依旧可用的,集群也可用。客户端无需进行任何改造,不需要自己实现流量均衡,且易于维护。
双机房热备属于备选方案,单集群三机房部署,双机房使用Replicator同步。
未来规划

小米对RocketMQ的未来规划主要分为新特性落地和运维能力。
新特性方面,期望实现分级存储、DLedger模式读写分离、以及批存储&Client auto batch的落地应用。
运维能力方面,期望实现扩缩容自动化以提高运维能力,落地OpenTracing以实现对RocketMQ的全方位监控。
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。