matplotlib 波士顿房价数据及可视化 Tensorflow 2.4.0
matplotlib 波士顿房价数据及可视化 Tensorflow 2.4.0
目录
matplotlib 波士顿房价数据及可视化 Tensorflow 2.4.0
1. 认识
1.1 kears
1.2 kears常用数据集
2. 波士顿房价数据及可视化
2.1 下载波士顿房价数据集
2.2 展示一个属性对房价的影响
2.3 将是三个属性全部展示
1. 认识
1.1 kears
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK 或者 Theano 作为后端运行。它提供了一套用户友好的API,用于快速构建和训练深度学习模型。
以下是Keras的一些关键特点:
- 模块化和可扩展性:Keras采用面向对象的方法编写,具有良好的模块化设计。这使得用户能够轻松地添加新模块,以扩展现有的功能。
- 跨平台运行:Keras支持在CPU和GPU上无缝切换运行,这为不同的计算需求提供了灵活性。
- 易于使用的API:Keras提供了一系列高层的神经网络模块,如全连接层(Dense)、卷积层(Conv2D)和长短时记忆模型(LSTM),使得开发者无需从头编写这些复杂模块的代码。
- 与TensorFlow的集成:在TensorFlow 2.0及以后的版本中,Keras被集成为tf.keras,成为TensorFlow的官方高级API。这意味着Keras的功能得到了TensorFlow的强大支持,同时保持了与原始Keras的高度兼容性。
总的来说,Keras因其简洁的接口和强大的功能,成为了深度学习研究人员和开发者广泛使用的框架之一。无论是进行学术研究还是商业应用开发,Keras都提供了一个高效且便捷的工具,以支持深度学习模型的实现和部署。
1.2 kears常用数据集
Keras提供了多种常用的数据集,以便于用户进行模型的训练和测试。
以下是一些Keras中常用的数据集及其简要介绍:
| CIFAR10 | 这是一个小型的图像分类数据集,包含了60,000张32x32的彩色图像,分为10个类别,每个类别有6,000张图像。其中50,000张用于训练,10,000张用于测试 |
| CIFAR100 | 与CIFAR10类似,但包含100个类别的小型图像分类数据集,总共有50,000张训练图像和10,000张测试图像。 |
| IMDB | 这是一个电影评论情感分类数据集,常用于文本分类任务,特别是情感分析。 |
| MNIST | 一个广泛使用的手写数字识别数据集,包含28x28灰度图像,共有10个类别,从0到9。 |
| Fashion-MNIST | 这是一个替代MNIST的数据集,包含了时尚相关的物品,同样有10个类别的28x28灰度图像。 |
| Boston Housing | 房价回归数据集,用于预测波士顿地区房屋的中位数价格。 |
| Pima Indians Diabetes Dataset |
|
此外,Keras还允许用户方便地加载其他公开数据集,如在官方文档中提到的其他7种数据集。同时,Keras也支持用户自定义数据集,以便进行更加个性化的模型训练和测试。
下面主要介绍波士顿房价数据集可视化
2. 波士顿房价数据及可视化
2.1 下载波士顿房价数据集
该数据集来自卡内基梅隆大学维护的 StatLib 库。样本包含 1970 年代的在波士顿郊区不同位置的房屋信息,总共有 13 种房屋属性。 目标值是一个位置的房屋的中值(单位:k$)。数据集很小,只有506个案例。数据集有以下14个属性:
| CRIM | 城镇人均犯罪率 |
| ZN | 占地面积超过25,000平方英尺的住宅用地比例。 |
| INDUS | 每个城镇非零售业务的比例。 |
| CHAS | Charles River虚拟变量(如果是河道,则为1;否则为0) |
| NOX | 一氧化氮浓度(每千万份) |
| RM | 每间住宅的平均房间数 |
| AGE | 1940年以前建造的自住单位比例 |
| DIS | 波士顿的五个就业中心加权距离 |
| RAD | 径向高速公路的可达性指数 |
| TAX | 每10,000美元的全额物业税率 |
| PTRATIO | 城镇的学生与教师比例 |
| B | 城镇中黑人比例 |
| LSTAT | 人口状况下降% |
| MEDV | 自有住房的中位数报价, 单位1000美元 |
import tensorflow as tf # 导入TensorFlow库
boston_housing = tf.keras.datasets.boston_housing # 加载波士顿房价数据集
(train_x, train_y), (test_x, test_y) = boston_housing.load_data(test_split=0.2) # 将数据集分为训练集和测试集,其中测试集占20%
print("Training set:", len(train_x)) # 打印训练集的大小
print("Testing set:", len(test_x)) # 打印测试集的大小
print(type(train_x)) # 打印训练集数据类型
print(type(train_y)) # 打印训练集标签数据类型
print("Dim of train_x:", train_x.ndim) # 打印训练集数据的维度
print("Shape of train_x:", train_x.shape) # 打印训练集数据的形状
print("Dim of train_y:", train_y.ndim) # 打印训练集标签的维度
print("Shape of train_y:", train_y.shape) # 打印训练集标签的形状
print(train_x[0:5]) # 打印训练集前5个样本的数据
print(train_x[:, 5]) # 打印训练集所有样本的第6列数据
注意: 缓存本地数据集的位置 (相对路径 ~/.keras/datasets)。例如我的放在C:\Users\ASUS\.keras\datasets文件夹下。如果不能下载可以自己在网上下载波士顿房价数据集将数据集放在.keras\datasets文件夹下。就可以正常运行。
2.2 展示一个属性对房价的影响
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
boston_housing = tf.keras.datasets.boston_housing
(train_x, train_y), (test_x, test_y) = boston_housing.load_data(test_split=0)
# 选择"RM"属性
rm = train_x[:,5]
prices = train_y
plt.scatter(rm, prices)
plt.xlabel('Average number of rooms per dwelling (RM)')
plt.ylabel('House prices')
plt.title('Relationship between RM and House Prices')
plt.show()
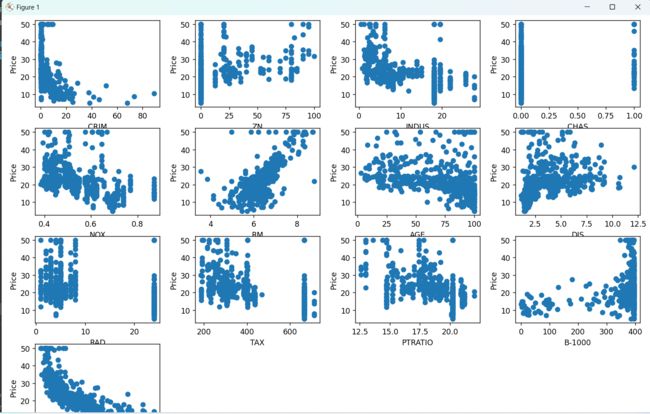
2.3 将是三个属性全部展示
# 将十三个属性全部展示出来
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
boston_housing = tf.keras.datasets.boston_housing
(train_x, train_y), (test_x, test_y) = boston_housing.load_data(test_split=0)
titles = ["CRIM","ZN","INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B-1000","LSTAT","MEDV"]
# 创建一个新的图形
plt.figure(figsize=(12, 12))
# 对于每一个属性,我们都画出一个散点图
for i in range(13):
plt.subplot(4, 4, i+1) # 创建一个4x4的子图,并选择第i+1个子图
plt.scatter(train_x[:, i], train_y) # 在子图中画出散点图
plt.xlabel(titles[i])
plt.ylabel("Price")
#plt.title(str(i+1)+"."+titles[i]) # 设置子图的标题
# 显示图形
plt.tight_layout()
plt.show()