// main.cpp
// 2.使用whisper初始化上下文,并根据给定的模型文件和参数进行配置
struct whisper_context * ctx = whisper_init_from_file_with_params(params.model.c_str(), cparams);
if (ctx == nullptr) {
fprintf(stderr, "error: failed to initialize whisper context\n");
return 3;
}
whisper_init_from_file_with_params_no_state
struct whisper_context * whisper_init_from_file_with_params_no_state(const char * path_model, struct whisper_context_params params) {
WHISPER_LOG_INFO("%s: loading model from '%s'\n", __func__, path_model);
auto fin = std::ifstream(path_model, std::ios::binary);
whisper_model_loader loader = {};
loader.context = &fin;
loader.read = [](void * ctx, void * output, size_t read_size) {
std::ifstream * fin = (std::ifstream*)ctx;
fin->read((char *)output, read_size);
return read_size;
};
loader.eof = [](void * ctx) {
std::ifstream * fin = (std::ifstream*)ctx;
return fin->eof();
};
loader.close = [](void * ctx) {
std::ifstream * fin = (std::ifstream*)ctx;
fin->close();
};
auto ctx = whisper_init_with_params_no_state(&loader, params);
if (ctx) {
ctx->path_model = path_model;
}
return ctx;
}
whisper_model_loader
// whisper.cpp-v1.5.0/whisper.h
// 定义模型加载器结构体
typedef struct whisper_model_loader {
void * context; // 上下文信息,可以是文件流、网络连接等,具体取决于模型加载器的实现
size_t (*read)(void * ctx, void * output, size_t read_size); // 函数指针,用于从上下文中读取数据
bool (*eof)(void * ctx); // 函数指针,用于检查上下文是否已到达末尾
void (*close)(void * ctx); // 函数指针,用于关闭上下文
} whisper_model_loader;
whisper_init_with_params_no_state
// whisper.cpp-v1.5.0/whisper.h
// Various functions for loading a ggml whisper model.
// Allocate (almost) all memory needed for the model.
// Return NULL on failure
WHISPER_API struct whisper_context * whisper_init_from_file_with_params (const char * path_model, struct whisper_context_params params);
WHISPER_API struct whisper_context * whisper_init_from_buffer_with_params(void * buffer, size_t buffer_size, struct whisper_context_params params);
WHISPER_API struct whisper_context * whisper_init_with_params (struct whisper_model_loader * loader, struct whisper_context_params params);
// These are the same as the above, but the internal state of the context is not allocated automatically
// It is the responsibility of the caller to allocate the state using whisper_init_state() (#523)
WHISPER_API struct whisper_context * whisper_init_from_file_with_params_no_state (const char * path_model, struct whisper_context_params params);
WHISPER_API struct whisper_context * whisper_init_from_buffer_with_params_no_state(void * buffer, size_t buffer_size, struct whisper_context_params params);
WHISPER_API struct whisper_context * whisper_init_with_params_no_state (struct whisper_model_loader * loader, struct whisper_context_params params);
struct whisper_context * whisper_init_with_params_no_state(struct whisper_model_loader * loader, struct whisper_context_params params) {
ggml_time_init();
whisper_context * ctx = new whisper_context;
ctx->params = params;
if (!whisper_model_load(loader, *ctx)) { ## !!!!!!
loader->close(loader->context);
WHISPER_LOG_ERROR("%s: failed to load model\n", __func__);
delete ctx;
return nullptr;
}
loader->close(loader->context);
return ctx;
}
重要数据结构 whisper_context
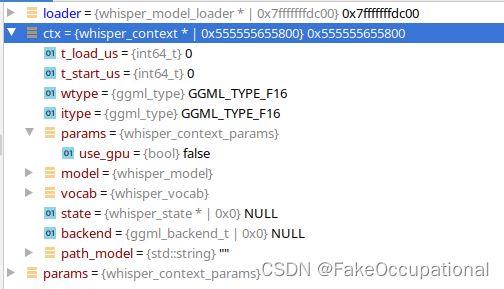
whisper_model
struct whisper_model {
e_model type = MODEL_UNKNOWN;
whisper_hparams hparams;
whisper_filters filters;
// encoder.positional_embedding
struct ggml_tensor * e_pe;
// encoder.conv1
struct ggml_tensor * e_conv_1_w;
struct ggml_tensor * e_conv_1_b;
// encoder.conv2
struct ggml_tensor * e_conv_2_w;
struct ggml_tensor * e_conv_2_b;
// encoder.ln_post
struct ggml_tensor * e_ln_w;
struct ggml_tensor * e_ln_b;
// decoder.positional_embedding
struct ggml_tensor * d_pe;
// decoder.token_embedding
struct ggml_tensor * d_te;
// decoder.ln
struct ggml_tensor * d_ln_w;
struct ggml_tensor * d_ln_b;
std::vector layers_encoder;
std::vector layers_decoder;
// ggml context that contains all the meta information about the model tensors
struct ggml_context * ctx;
// the model backend data is read-only and can be shared between processors
struct ggml_backend_buffer * buffer;
// tensors
int n_loaded;
std::map tensors;
};
whisper_layer_encoder : whisper_model的编码器
// audio encoding layer
struct whisper_layer_encoder {
// encoder.blocks.*.attn_ln
struct ggml_tensor * attn_ln_0_w;
struct ggml_tensor * attn_ln_0_b;
// encoder.blocks.*.attn.out
struct ggml_tensor * attn_ln_1_w;
struct ggml_tensor * attn_ln_1_b;
// encoder.blocks.*.attn.query
struct ggml_tensor * attn_q_w;
struct ggml_tensor * attn_q_b;
// encoder.blocks.*.attn.key
struct ggml_tensor * attn_k_w;
// encoder.blocks.*.attn.value
struct ggml_tensor * attn_v_w;
struct ggml_tensor * attn_v_b;
// encoder.blocks.*.mlp_ln
struct ggml_tensor * mlp_ln_w;
struct ggml_tensor * mlp_ln_b;
// encoder.blocks.*.mlp.0
struct ggml_tensor * mlp_0_w;
struct ggml_tensor * mlp_0_b;
// encoder.blocks.*.mlp.2
struct ggml_tensor * mlp_1_w;
struct ggml_tensor * mlp_1_b;
};
whisper_layer_encoder : whisper_model的解码器
// token decoding layer
struct whisper_layer_decoder {
// decoder.blocks.*.attn_ln
struct ggml_tensor * attn_ln_0_w;
struct ggml_tensor * attn_ln_0_b;
// decoder.blocks.*.attn.out
struct ggml_tensor * attn_ln_1_w;
struct ggml_tensor * attn_ln_1_b;
// decoder.blocks.*.attn.query
struct ggml_tensor * attn_q_w;
struct ggml_tensor * attn_q_b;
// decoder.blocks.*.attn.key
struct ggml_tensor * attn_k_w;
// decoder.blocks.*.attn.value
struct ggml_tensor * attn_v_w;
struct ggml_tensor * attn_v_b;
// decoder.blocks.*.cross_attn_ln
struct ggml_tensor * cross_attn_ln_0_w;
struct ggml_tensor * cross_attn_ln_0_b;
// decoder.blocks.*.cross_attn.out
struct ggml_tensor * cross_attn_ln_1_w;
struct ggml_tensor * cross_attn_ln_1_b;
// decoder.blocks.*.cross_attn.query
struct ggml_tensor * cross_attn_q_w;
struct ggml_tensor * cross_attn_q_b;
// decoder.blocks.*.cross_attn.key
struct ggml_tensor * cross_attn_k_w;
// decoder.blocks.*.cross_attn.value
struct ggml_tensor * cross_attn_v_w;
struct ggml_tensor * cross_attn_v_b;
// decoder.blocks.*.mlp_ln
struct ggml_tensor * mlp_ln_w;
struct ggml_tensor * mlp_ln_b;
// decoder.blocks.*.mlp.0
struct ggml_tensor * mlp_0_w;
struct ggml_tensor * mlp_0_b;
// decoder.blocks.*.mlp.2
struct ggml_tensor * mlp_1_w;
struct ggml_tensor * mlp_1_b;
};
whisper_model_load函数
begin
static bool whisper_model_load(struct whisper_model_loader * loader, whisper_context & wctx) {
WHISPER_LOG_INFO("%s: loading model\n", __func__);
const int64_t t_start_us = ggml_time_us();
wctx.t_start_us = t_start_us;
auto & model = wctx.model;
auto & vocab = wctx.vocab;
{
uint32_t magic;
read_safe(loader, magic);
if (magic != GGML_FILE_MAGIC) {
WHISPER_LOG_ERROR("%s: invalid model data (bad magic)\n", __func__);
return false;
}
}
{
auto & hparams = model.hparams;
read_safe(loader, hparams.n_vocab);
read_safe(loader, hparams.n_audio_ctx);
read_safe(loader, hparams.n_audio_state);
read_safe(loader, hparams.n_audio_head);
read_safe(loader, hparams.n_audio_layer);
read_safe(loader, hparams.n_text_ctx);
read_safe(loader, hparams.n_text_state);
read_safe(loader, hparams.n_text_head);
read_safe(loader, hparams.n_text_layer);
read_safe(loader, hparams.n_mels);
read_safe(loader, hparams.ftype);
assert(hparams.n_text_state == hparams.n_audio_state);
std::string mver = "";
if (hparams.n_audio_layer == 4) {
model.type = e_model::MODEL_TINY;
}
if (hparams.n_audio_layer == 6) {
model.type = e_model::MODEL_BASE;
}
if (hparams.n_audio_layer == 12) {
model.type = e_model::MODEL_SMALL;
}
if (hparams.n_audio_layer == 24) {
model.type = e_model::MODEL_MEDIUM;
}
if (hparams.n_audio_layer == 32) {
model.type = e_model::MODEL_LARGE;
if (hparams.n_vocab == 51866) {
mver = " v3";
}
}
const int32_t qntvr = hparams.ftype / GGML_QNT_VERSION_FACTOR;
hparams.ftype %= GGML_QNT_VERSION_FACTOR;
wctx.wtype = ggml_ftype_to_ggml_type((ggml_ftype) (model.hparams.ftype));
if (wctx.wtype == GGML_TYPE_COUNT) {
WHISPER_LOG_ERROR("%s: invalid model (bad ftype value %d)\n", __func__, model.hparams.ftype);
return false;
}
WHISPER_LOG_INFO("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
WHISPER_LOG_INFO("%s: n_audio_ctx = %d\n", __func__, hparams.n_audio_ctx);
WHISPER_LOG_INFO("%s: n_audio_state = %d\n", __func__, hparams.n_audio_state);
WHISPER_LOG_INFO("%s: n_audio_head = %d\n", __func__, hparams.n_audio_head);
WHISPER_LOG_INFO("%s: n_audio_layer = %d\n", __func__, hparams.n_audio_layer);
WHISPER_LOG_INFO("%s: n_text_ctx = %d\n", __func__, hparams.n_text_ctx);
WHISPER_LOG_INFO("%s: n_text_state = %d\n", __func__, hparams.n_text_state);
WHISPER_LOG_INFO("%s: n_text_head = %d\n", __func__, hparams.n_text_head);
WHISPER_LOG_INFO("%s: n_text_layer = %d\n", __func__, hparams.n_text_layer);
WHISPER_LOG_INFO("%s: n_mels = %d\n", __func__, hparams.n_mels);
WHISPER_LOG_INFO("%s: ftype = %d\n", __func__, model.hparams.ftype);
WHISPER_LOG_INFO("%s: qntvr = %d\n", __func__, qntvr);
WHISPER_LOG_INFO("%s: type = %d (%s%s)\n", __func__, model.type, g_model_name.at(model.type).c_str(), mver.c_str());
}
{
auto & filters = wctx.model.filters;
read_safe(loader, filters.n_mel);
read_safe(loader, filters.n_fft);
filters.data.resize(filters.n_mel * filters.n_fft);
loader->read(loader->context, filters.data.data(), filters.data.size() * sizeof(float));
BYTESWAP_FILTERS(filters);
}
{
int32_t n_vocab = 0;
read_safe(loader, n_vocab);
std::string word;
std::vector<char> tmp;
tmp.reserve(128);
for (int i = 0; i < n_vocab; i++) {
uint32_t len;
read_safe(loader, len);
if (len > 0) {
tmp.resize(len);
loader->read(loader->context, &tmp[0], tmp.size());
word.assign(&tmp[0], tmp.size());
} else {
word = "";
}
vocab.token_to_id[word] = i;
vocab.id_to_token[i] = word;
}
vocab.n_vocab = model.hparams.n_vocab;
if (vocab.is_multilingual()) {
vocab.token_eot++;
vocab.token_sot++;
const int dt = vocab.num_languages() - 98;
vocab.token_translate += dt;
vocab.token_transcribe += dt;
vocab.token_solm += dt;
vocab.token_prev += dt;
vocab.token_nosp += dt;
vocab.token_not += dt;
vocab.token_beg += dt;
}
if (n_vocab < model.hparams.n_vocab) {
WHISPER_LOG_INFO("%s: adding %d extra tokens\n", __func__, model.hparams.n_vocab - n_vocab);
for (int i = n_vocab; i < model.hparams.n_vocab; i++) {
if (i > vocab.token_beg) {
word = "[_TT_" + std::to_string(i - vocab.token_beg) + "]";
} else if (i == vocab.token_eot) {
word = "[_EOT_]";
} else if (i == vocab.token_sot) {
word = "[_SOT_]";
} else if (i == vocab.token_translate) {
word = "[_TRANSLATE_]";
} else if (i == vocab.token_transcribe) {
word = "[_TRANSCRIBE_]";
} else if (i == vocab.token_solm) {
word = "[_SOLM_]";
} else if (i == vocab.token_prev) {
word = "[_PREV_]";
} else if (i == vocab.token_nosp) {
word = "[_NOSP_]";
} else if (i == vocab.token_not) {
word = "[_NOT_]";
} else if (i == vocab.token_beg) {
word = "[_BEG_]";
} else if (i > vocab.token_sot && i <= vocab.token_sot + vocab.num_languages()) {
word = "[_LANG_" + std::string(whisper_lang_str(i - vocab.token_sot - 1)) + "]";
} else {
word = "[_extra_token_" + std::to_string(i) + "]";
}
vocab.token_to_id[word] = i;
vocab.id_to_token[i] = word;
}
}
WHISPER_LOG_INFO("%s: n_langs = %d\n", __func__, vocab.num_languages());
}
const ggml_type wtype = wctx.wtype;
const ggml_type vtype = wctx.wtype == GGML_TYPE_F32 ? GGML_TYPE_F32 : GGML_TYPE_F16;
{
const auto & hparams = model.hparams;
const int n_audio_layer = hparams.n_audio_layer;
const int n_text_layer = hparams.n_text_layer;
const size_t n_tensors = 10 + 15 + 15*n_audio_layer + 24*n_text_layer;
struct ggml_init_params params = {
n_tensors*ggml_tensor_overhead(),
nullptr,
true,
};
model.ctx = ggml_init(params);
if (!model.ctx) {
WHISPER_LOG_ERROR("%s: ggml_init() failed\n", __func__);
return false;
}
}
{
auto & ctx = model.ctx;
const auto & hparams = model.hparams;
const int n_vocab = hparams.n_vocab;
const int n_audio_ctx = hparams.n_audio_ctx;
const int n_audio_state = hparams.n_audio_state;
const int n_audio_layer = hparams.n_audio_layer;
const int n_text_ctx = hparams.n_text_ctx;
const int n_text_state = hparams.n_text_state;
const int n_text_layer = hparams.n_text_layer;
const int n_mels = hparams.n_mels;
model.layers_encoder.resize(n_audio_layer);
model.layers_decoder.resize(n_text_layer);
{
model.e_pe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_audio_state, n_audio_ctx);
model.e_conv_1_w = ggml_new_tensor_3d(ctx, vtype, 3, n_mels, n_audio_state);
model.e_conv_1_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, 2*n_audio_ctx, n_audio_state);
model.e_conv_2_w = ggml_new_tensor_3d(ctx, vtype, 3, n_audio_state, n_audio_state);
model.e_conv_2_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_audio_ctx, n_audio_state);
model.e_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
model.e_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
model.tensors["encoder.positional_embedding"] = model.e_pe;
model.tensors["encoder.conv1.weight"] = model.e_conv_1_w;
model.tensors["encoder.conv1.bias"] = model.e_conv_1_b;
model.tensors["encoder.conv2.weight"] = model.e_conv_2_w;
model.tensors["encoder.conv2.bias"] = model.e_conv_2_b;
model.tensors["encoder.ln_post.weight"] = model.e_ln_w;
model.tensors["encoder.ln_post.bias"] = model.e_ln_b;
for (int i = 0; i < n_audio_layer; ++i) {
auto & layer = model.layers_encoder[i];
layer.mlp_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.mlp_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.mlp_0_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, 4*n_audio_state);
layer.mlp_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_audio_state);
layer.mlp_1_w = ggml_new_tensor_2d(ctx, wtype, 4*n_audio_state, n_audio_state);
layer.mlp_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp_ln.weight"] = layer.mlp_ln_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp_ln.bias"] = layer.mlp_ln_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.0.weight"] = layer.mlp_0_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.0.bias"] = layer.mlp_0_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.2.weight"] = layer.mlp_1_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.2.bias"] = layer.mlp_1_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn_ln.weight"] = layer.attn_ln_0_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn_ln.bias"] = layer.attn_ln_0_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.query.weight"] = layer.attn_q_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.query.bias"] = layer.attn_q_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.key.weight"] = layer.attn_k_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.value.weight"] = layer.attn_v_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.value.bias"] = layer.attn_v_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.out.weight"] = layer.attn_ln_1_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.out.bias"] = layer.attn_ln_1_b;
}
}
{
model.d_pe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_text_state, n_text_ctx);
model.d_te = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_vocab);
model.d_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
model.d_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
model.tensors["decoder.positional_embedding"] = model.d_pe;
model.tensors["decoder.token_embedding.weight"] = model.d_te;
model.tensors["decoder.ln.weight"] = model.d_ln_w;
model.tensors["decoder.ln.bias"] = model.d_ln_b;
for (int i = 0; i < n_text_layer; ++i) {
auto & layer = model.layers_decoder[i];
layer.mlp_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.mlp_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.mlp_0_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, 4*n_text_state);
layer.mlp_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_text_state);
layer.mlp_1_w = ggml_new_tensor_2d(ctx, wtype, 4*n_text_state, n_text_state);
layer.mlp_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp_ln.weight"] = layer.mlp_ln_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp_ln.bias"] = layer.mlp_ln_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.0.weight"] = layer.mlp_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.0.bias"] = layer.mlp_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.2.weight"] = layer.mlp_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.2.bias"] = layer.mlp_1_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn_ln.weight"] = layer.attn_ln_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn_ln.bias"] = layer.attn_ln_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.query.weight"] = layer.attn_q_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.query.bias"] = layer.attn_q_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.key.weight"] = layer.attn_k_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.value.weight"] = layer.attn_v_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.value.bias"] = layer.attn_v_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.out.weight"] = layer.attn_ln_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.out.bias"] = layer.attn_ln_1_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn_ln.weight"] = layer.cross_attn_ln_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn_ln.bias"] = layer.cross_attn_ln_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.query.weight"] = layer.cross_attn_q_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.query.bias"] = layer.cross_attn_q_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.key.weight"] = layer.cross_attn_k_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.value.weight"] = layer.cross_attn_v_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.value.bias"] = layer.cross_attn_v_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.out.weight"] = layer.cross_attn_ln_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.out.bias"] = layer.cross_attn_ln_1_b;
}
}
}
wctx.backend = whisper_backend_init(wctx.params);
{
size_t size_main = 0;
for (const auto & t : model.tensors) {
size_main += ggml_nbytes(t.second) + ggml_tensor_overhead();
}
model.buffer = ggml_backend_alloc_buffer(wctx.backend, size_main);
WHISPER_LOG_INFO("%s: %8s buffer size = %8.2f MB\n", __func__, ggml_backend_name(wctx.backend), size_main / 1e6);
}
ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer);
{
for (const auto & t : model.tensors) {
ggml_allocr_alloc(alloc, t.second);
}
}
{
size_t total_size = 0;
model.n_loaded = 0;
std::vector<char> read_buf;
while (true) {
int32_t n_dims;
int32_t length;
int32_t ttype;
read_safe(loader, n_dims);
read_safe(loader, length);
read_safe(loader, ttype);
if (loader->eof(loader->context)) {
break;
}
int32_t nelements = 1;
int32_t ne[4] = { 1, 1, 1, 1 };
for (int i = 0; i < n_dims; ++i) {
read_safe(loader, ne[i]);
nelements *= ne[i];
}
std::string name;
std::vector<char> tmp(length);
loader->read(loader->context, &tmp[0], tmp.size());
name.assign(&tmp[0], tmp.size());
if (model.tensors.find(name) == model.tensors.end()) {
WHISPER_LOG_ERROR("%s: unknown tensor '%s' in model file\n", __func__, name.data());
return false;
}
auto tensor = model.tensors[name.data()];
const bool is_conv_bias = (name == "encoder.conv1.bias" || name == "encoder.conv2.bias");
if (!is_conv_bias) {
if (ggml_nelements(tensor) != nelements) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
WHISPER_LOG_ERROR("%s: shape: [%d, %d, %d], expected: [%d, %d, %d]\n",
__func__, ne[0], ne[1], ne[2], (int) tensor->ne[0], (int) tensor->ne[1], (int) tensor->ne[2]);
return false;
}
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1] || tensor->ne[2] != ne[2]) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong shape in model file: got [%d, %d, %d], expected [%d, %d, %d]\n",
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], (int) tensor->ne[2], ne[0], ne[1], ne[2]);
return false;
}
const size_t bpe = ggml_type_size(ggml_type(ttype));
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
return false;
}
}
ggml_backend_t backend = wctx.backend;
if ((ggml_backend_is_cpu(backend)
#ifdef GGML_USE_METAL
|| ggml_backend_is_metal(backend)
#endif
) && !is_conv_bias) {
loader->read(loader->context, tensor->data, ggml_nbytes(tensor));
BYTESWAP_TENSOR(tensor);
} else {
read_buf.resize(ggml_nbytes(tensor));
if (is_conv_bias) {
loader->read(loader->context, read_buf.data(), read_buf.size() / tensor->ne[0]);
float * data_f32 = (float *) read_buf.data();
for (int64_t y = 0; y < tensor->ne[1]; ++y) {
const int64_t yy = tensor->ne[1] - y - 1;
const float val = data_f32[yy];
for (int64_t x = 0; x < tensor->ne[0]; ++x) {
data_f32[yy*tensor->ne[0] + x] = val;
}
}
} else {
loader->read(loader->context, read_buf.data(), read_buf.size());
}
ggml_backend_tensor_set(tensor, read_buf.data(), 0, ggml_nbytes(tensor));
}
total_size += ggml_nbytes(tensor);
model.n_loaded++;
}
WHISPER_LOG_INFO("%s: model size = %7.2f MB\n", __func__, total_size/1e6);
if (model.n_loaded == 0) {
WHISPER_LOG_WARN("%s: WARN no tensors loaded from model file - assuming empty model for testing\n", __func__);
} else if (model.n_loaded != (int) model.tensors.size()) {
WHISPER_LOG_ERROR("%s: ERROR not all tensors loaded from model file - expected %zu, got %d\n", __func__, model.tensors.size(), model.n_loaded);
return false;
}
}
ggml_allocr_free(alloc);
wctx.t_load_us = ggml_time_us() - t_start_us;
return true;
}
static bool whisper_model_load(struct whisper_model_loader * loader, whisper_context & wctx) {
const int64_t t_start_us = ggml_time_us();
wctx.t_start_us = t_start_us;
auto & model = wctx.model;
auto & vocab = wctx.vocab;
验证模型数据的魔术数
{
uint32_t magic;
read_safe(loader, magic);
if (magic != GGML_FILE_MAGIC) {
WHISPER_LOG_ERROR("%s: invalid model data (bad magic)\n", __func__);
return false;
}
}
加载超参数
{
auto & hparams = model.hparams;
read_safe(loader, hparams.n_vocab);
read_safe(loader, hparams.n_audio_ctx);
WHISPER_LOG_INFO("%s: n_vocab = %d\n", __func__, hparams.n_vocab);
}
加载滤波器
{
auto & filters = wctx.model.filters;
read_safe(loader, filters.n_mel);
read_safe(loader, filters.n_fft);
filters.data.resize(filters.n_mel * filters.n_fft);
loader->read(loader->context, filters.data.data(), filters.data.size() * sizeof(float));
BYTESWAP_FILTERS(filters);
}
加载词汇表
{
int32_t n_vocab = 0;
read_safe(loader, n_vocab);
std::string word;
std::vector<char> tmp;
tmp.reserve(128);
for (int i = 0; i < n_vocab; i++) {
uint32_t len;
read_safe(loader, len);
if (len > 0) {
tmp.resize(len);
loader->read(loader->context, &tmp[0], tmp.size());
word.assign(&tmp[0], tmp.size());
} else {
word = "";
}
vocab.token_to_id[word] = i;
vocab.id_to_token[i] = word;
}
if (vocab.is_multilingual()) {
vocab.token_eot++;
vocab.token_sot++;
}
if (n_vocab < model.hparams.n_vocab) {
WHISPER_LOG_INFO("%s: adding %d extra tokens\n", __func__, model.hparams.n_vocab - n_vocab);
for (int i = n_vocab; i < model.hparams.n_vocab; i++) {
}
}
WHISPER_LOG_INFO("%s: n_langs = %d\n", __func__, vocab.num_languages());
}
创建GGML上下文
const ggml_type wtype = wctx.wtype;
const ggml_type vtype = wctx.wtype == GGML_TYPE_F32 ? GGML_TYPE_F32 : GGML_TYPE_F16;
{
const auto & hparams = model.hparams;
const int n_audio_layer = hparams.n_audio_layer;
const int n_text_layer = hparams.n_text_layer;
const size_t n_tensors = 10 + 15 + 15*n_audio_layer + 24*n_text_layer;
struct ggml_init_params params = {
n_tensors*ggml_tensor_overhead(),
nullptr,
true,
};
model.ctx = ggml_init(params);
if (!model.ctx) {
WHISPER_LOG_ERROR("%s: ggml_init() failed\n", __func__);
return false;
}
}
使用ggml_new_tensor_*d创建权重张量
// prepare tensors for the weights
{
auto & ctx = model.ctx;
const auto & hparams = model.hparams;
const int n_vocab = hparams.n_vocab;
const int n_audio_ctx = hparams.n_audio_ctx;
const int n_audio_state = hparams.n_audio_state;
const int n_audio_layer = hparams.n_audio_layer;
const int n_text_ctx = hparams.n_text_ctx;
const int n_text_state = hparams.n_text_state;
const int n_text_layer = hparams.n_text_layer;
const int n_mels = hparams.n_mels;
model.layers_encoder.resize(n_audio_layer);
model.layers_decoder.resize(n_text_layer);
// encoder
{
model.e_pe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_audio_state, n_audio_ctx);
model.e_conv_1_w = ggml_new_tensor_3d(ctx, vtype, 3, n_mels, n_audio_state);
model.e_conv_1_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, 2*n_audio_ctx, n_audio_state);
model.e_conv_2_w = ggml_new_tensor_3d(ctx, vtype, 3, n_audio_state, n_audio_state);
model.e_conv_2_b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_audio_ctx, n_audio_state);
model.e_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
model.e_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
// map by name
model.tensors["encoder.positional_embedding"] = model.e_pe;
model.tensors["encoder.conv1.weight"] = model.e_conv_1_w;
model.tensors["encoder.conv1.bias"] = model.e_conv_1_b;
model.tensors["encoder.conv2.weight"] = model.e_conv_2_w;
model.tensors["encoder.conv2.bias"] = model.e_conv_2_b;
model.tensors["encoder.ln_post.weight"] = model.e_ln_w;
model.tensors["encoder.ln_post.bias"] = model.e_ln_b;
for (int i = 0; i < n_audio_layer; ++i) {
auto & layer = model.layers_encoder[i];
layer.mlp_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.mlp_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.mlp_0_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, 4*n_audio_state);
layer.mlp_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_audio_state);
layer.mlp_1_w = ggml_new_tensor_2d(ctx, wtype, 4*n_audio_state, n_audio_state);
layer.mlp_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
layer.attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_audio_state, n_audio_state);
layer.attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_audio_state);
// map by name
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp_ln.weight"] = layer.mlp_ln_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp_ln.bias"] = layer.mlp_ln_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.0.weight"] = layer.mlp_0_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.0.bias"] = layer.mlp_0_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.2.weight"] = layer.mlp_1_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".mlp.2.bias"] = layer.mlp_1_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn_ln.weight"] = layer.attn_ln_0_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn_ln.bias"] = layer.attn_ln_0_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.query.weight"] = layer.attn_q_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.query.bias"] = layer.attn_q_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.key.weight"] = layer.attn_k_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.value.weight"] = layer.attn_v_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.value.bias"] = layer.attn_v_b;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.out.weight"] = layer.attn_ln_1_w;
model.tensors["encoder.blocks." + std::to_string(i) + ".attn.out.bias"] = layer.attn_ln_1_b;
}
}
// decoder
{
model.d_pe = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, n_text_state, n_text_ctx);
model.d_te = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_vocab);
model.d_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
model.d_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
// map by name
model.tensors["decoder.positional_embedding"] = model.d_pe;
model.tensors["decoder.token_embedding.weight"] = model.d_te;
model.tensors["decoder.ln.weight"] = model.d_ln_w;
model.tensors["decoder.ln.bias"] = model.d_ln_b;
for (int i = 0; i < n_text_layer; ++i) {
auto & layer = model.layers_decoder[i];
layer.mlp_ln_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.mlp_ln_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.mlp_0_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, 4*n_text_state);
layer.mlp_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, 4*n_text_state);
layer.mlp_1_w = ggml_new_tensor_2d(ctx, wtype, 4*n_text_state, n_text_state);
layer.mlp_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_0_w = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_0_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_q_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_q_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_k_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_v_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_v_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
layer.cross_attn_ln_1_w = ggml_new_tensor_2d(ctx, wtype, n_text_state, n_text_state);
layer.cross_attn_ln_1_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_text_state);
// map by name
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp_ln.weight"] = layer.mlp_ln_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp_ln.bias"] = layer.mlp_ln_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.0.weight"] = layer.mlp_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.0.bias"] = layer.mlp_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.2.weight"] = layer.mlp_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".mlp.2.bias"] = layer.mlp_1_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn_ln.weight"] = layer.attn_ln_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn_ln.bias"] = layer.attn_ln_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.query.weight"] = layer.attn_q_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.query.bias"] = layer.attn_q_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.key.weight"] = layer.attn_k_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.value.weight"] = layer.attn_v_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.value.bias"] = layer.attn_v_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.out.weight"] = layer.attn_ln_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".attn.out.bias"] = layer.attn_ln_1_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn_ln.weight"] = layer.cross_attn_ln_0_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn_ln.bias"] = layer.cross_attn_ln_0_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.query.weight"] = layer.cross_attn_q_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.query.bias"] = layer.cross_attn_q_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.key.weight"] = layer.cross_attn_k_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.value.weight"] = layer.cross_attn_v_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.value.bias"] = layer.cross_attn_v_b;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.out.weight"] = layer.cross_attn_ln_1_w;
model.tensors["decoder.blocks." + std::to_string(i) + ".cross_attn.out.bias"] = layer.cross_attn_ln_1_b;
}
}
}
wctx.backend = whisper_backend_init(wctx.params);
{
size_t size_main = 0;
for (const auto & t : model.tensors) {
size_main += ggml_nbytes(t.second) + ggml_tensor_overhead();
}
model.buffer = ggml_backend_alloc_buffer(wctx.backend, size_main);
WHISPER_LOG_INFO("%s: %8s buffer size = %8.2f MB\n", __func__, ggml_backend_name(wctx.backend), size_main / 1e6);
}
ggml_allocr * alloc = ggml_allocr_new_from_buffer(model.buffer);
// allocate tensors in the backend buffers
{
for (const auto & t : model.tensors) {
ggml_allocr_alloc(alloc, t.second);
}
}
使用read_safe和loader->read加载weights
- 一个重要的函数,为什么叫read_safe,可能和大小端有关,模板函数的参数类型在编译时进行推断,编译器通过模板参数的使用上下文来确定模板参数的具体类型。
// #define BYTESWAP_VALUE(d) do {} while (0)
// 这个模板函数的目的是提供一种通用的、类型安全的方式来从 whisper_model_loader 中读取数据,并在需要时进行字节交换。
template
static void read_safe(whisper_model_loader * loader, T & dest) {
loader->read(loader->context, &dest, sizeof(T));
BYTESWAP_VALUE(dest);
}
// 其他:
// 如果需要转换的话,#define BYTESWAP_VALUE(d) do {} while (0),中的{}可能会有一个类似以下的逻辑:
#include
#include
// 函数用于交换字节顺序
template
T swapEndianness(T value) {
static_assert(std::is_pod::value, "Type must be a POD type");
union {
T value;
uint8_t bytes[sizeof(T)];
} source, dest;
source.value = value;
for (size_t i = 0; i < sizeof(T); ++i) {
dest.bytes[i] = source.bytes[sizeof(T) - i - 1];
}
return dest.value;
}
int main() {
// 示例:32位整数的大小端转换
uint32_t originalValue = 0x12345678;
uint32_t convertedValue = swapEndianness(originalValue);
std::cout << "Original Value: 0x" << std::hex << originalValue << std::endl;
std::cout << "Converted Value: 0x" << std::hex << convertedValue << std::endl;
return 0;
}
// load weights
{
size_t total_size = 0;
model.n_loaded = 0;
std::vector read_buf;
while (true) {
int32_t n_dims;
int32_t length;
int32_t ttype;
read_safe(loader, n_dims);
read_safe(loader, length);
read_safe(loader, ttype);
if (loader->eof(loader->context)) {
break;
}
int32_t nelements = 1;
int32_t ne[4] = { 1, 1, 1, 1 };
for (int i = 0; i < n_dims; ++i) {
read_safe(loader, ne[i]);
nelements *= ne[i];
}
std::string name;
std::vector tmp(length); // create a buffer
loader->read(loader->context, &tmp[0], tmp.size()); // read to buffer
name.assign(&tmp[0], tmp.size());// 使用 name.assign 将缓冲区中的数据赋值给字符串name。这种做法是因为在C++11之前,std::string 并没有提供直接从指定位置和长度构造的构造函数,而通过 assign 函数可以方便地将指定范围的数据赋值给字符串。
if (model.tensors.find(name) == model.tensors.end()) {
WHISPER_LOG_ERROR("%s: unknown tensor '%s' in model file\n", __func__, name.data());
return false;
}
auto tensor = model.tensors[name.data()];
const bool is_conv_bias = (name == "encoder.conv1.bias" || name == "encoder.conv2.bias");
if (!is_conv_bias) {
if (ggml_nelements(tensor) != nelements) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong size in model file\n", __func__, name.data());
WHISPER_LOG_ERROR("%s: shape: [%d, %d, %d], expected: [%d, %d, %d]\n",
__func__, ne[0], ne[1], ne[2], (int) tensor->ne[0], (int) tensor->ne[1], (int) tensor->ne[2]);
return false;
}
if (tensor->ne[0] != ne[0] || tensor->ne[1] != ne[1] || tensor->ne[2] != ne[2]) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong shape in model file: got [%d, %d, %d], expected [%d, %d, %d]\n",
__func__, name.data(), (int) tensor->ne[0], (int) tensor->ne[1], (int) tensor->ne[2], ne[0], ne[1], ne[2]);
return false;
}
const size_t bpe = ggml_type_size(ggml_type(ttype));
if ((nelements*bpe)/ggml_blck_size(tensor->type) != ggml_nbytes(tensor)) {
WHISPER_LOG_ERROR("%s: tensor '%s' has wrong size in model file: got %zu, expected %zu\n",
__func__, name.data(), ggml_nbytes(tensor), nelements*bpe);
return false;
}
}
ggml_backend_t backend = wctx.backend;
//printf("%s: [%5.5s] %s\n", __func__, ggml_backend_name(backend), name.c_str());
if ((ggml_backend_is_cpu(backend)
#ifdef GGML_USE_METAL
|| ggml_backend_is_metal(backend)
#endif
) && !is_conv_bias) {
// for the CPU and Metal backend, we can read directly into the tensor
loader->read(loader->context, tensor->data, ggml_nbytes(tensor));
BYTESWAP_TENSOR(tensor);
} else {
// read into a temporary buffer first, then copy to device memory
read_buf.resize(ggml_nbytes(tensor));
// we repeat the 2 bias tensors along dim 0:
// [1, 512] -> [3000, 512] (conv1.bias)
// [1, 512] -> [1500, 512] (conv2.bias)
if (is_conv_bias) {
loader->read(loader->context, read_buf.data(), read_buf.size() / tensor->ne[0]);
float * data_f32 = (float *) read_buf.data();
for (int64_t y = 0; y < tensor->ne[1]; ++y) {
const int64_t yy = tensor->ne[1] - y - 1;
const float val = data_f32[yy];
for (int64_t x = 0; x < tensor->ne[0]; ++x) {
data_f32[yy*tensor->ne[0] + x] = val;
}
}
} else {
loader->read(loader->context, read_buf.data(), read_buf.size());
}
ggml_backend_tensor_set(tensor, read_buf.data(), 0, ggml_nbytes(tensor));
}
//printf("%48s - [%5d, %5d, %5d], type = %6s, %6.2f MB\n", name.data(), ne[0], ne[1], ne[2], ggml_type_name((ggml_type) ttype), ggml_nbytes(tensor)/1e6);
total_size += ggml_nbytes(tensor);
model.n_loaded++;
}
WHISPER_LOG_INFO("%s: model size = %7.2f MB\n", __func__, total_size/1e6);
if (model.n_loaded == 0) {
WHISPER_LOG_WARN("%s: WARN no tensors loaded from model file - assuming empty model for testing\n", __func__);
} else if (model.n_loaded != (int) model.tensors.size()) {
WHISPER_LOG_ERROR("%s: ERROR not all tensors loaded from model file - expected %zu, got %d\n", __func__, model.tensors.size(), model.n_loaded);
return false;
}
}
end
ggml_allocr_free(alloc);
wctx.t_load_us = ggml_time_us() - t_start_us;
return true;
}