AI图像生成开发教程之认识AI大语言模型
AI图像生成开发教程

教程简介
经过几个月的实践与酝酿,AI图像生成开发系列教程,它来了。【AI图像生成开发教程】致力于用最通俗易懂的语言,为大家带来最好的教程,介绍AI图像的前世今生,结合图像生成模型、多模态模型、大语言模型以及各类便捷的语音合成等API,完成AI图像生成,并通过设计游戏类、应用类、AI艺术类实际案例,起到抛砖引玉的作用。打通AI生成模型与大语言模型共同创作的障碍,助力大家实现不同AI场景、AI应用的实现。
After several months of practice and preparation, a series of tutorials on AI image generation development have arrived. AI Image Generation Development Tutorial is committed to providing the best tutorials in the most user-friendly language, introducing the past and present of AI images. By combining image generation models, multimodal models, large language models, and various convenient speech synthesis APIs, we aim to complete AI image generation and design practical cases for gaming, application, and AI art, playing a role in attracting valuable insights. To overcome the obstacles of co creation between AI generation models and big language models, and help everyone achieve different AI scenarios and applications.
教程目录
第1课 AI图像生成开发教程之认识AI图像生成模型
第2课 AI图像生成开发教程之认识AI大语言模型
第3课 AI图像生成开发教程之文心一言遇见Stable Diffusion
第4课 AI图像生成开发教程之文心一言遇见SDXL
第5课 AI图像生成开发教程之文心一言遇见Clip+SD
第6课 AI图像生成开发教程之AI艺术类案例实操
第7课 AI图像生成开发教程之AI游戏类案例实操
第8课 AI图像生成开发教程之AI应用类案例实操
大家如对教程感兴趣或者有任何问题,可以在评论区留言,或者扫码加入我的社区专属频道。
| 社区频道 | 课程详情 |
|---|---|
第2课 AI图像生成开发教程之认识AI大语言模型
欢迎来到我们的AI图像生成开发教程系列第2课 AI图像生成开发教程之认识AI大语言模型。在本节课中,我们将深入了解如何使用AI大语言模型来生成高质量的图像。在本教程中,我们将重点介绍AI大语言模型的基础知识,包括其定义、架构、工作原理以及应用场景。

1 大语言模型的前世今生
1.1 什么是AI大语言模型?
AI大语言模型是一种基于深度学习的自然语言处理(NLP)技术,它能够理解和处理自然语言文本,并根据训练数据和模型架构来生成新的文本或图像。这些模型通常使用Transformer架构,这是一种非串行的神经网络架构,最初被用于执行基于上下文的机器翻译任务。
1.2 AI大语言模型的架构和工作原理
1.2.1 Transformer架构
Transformer模型是一种非串行的神经网络架构,它以Encoder-Decoder架构为基础,能够并行处理整个文本序列。在Encoder阶段,模型将输入序列转换为一系列向量,这些向量在Decoder阶段被用来生成输出序列。此外,Transformer模型还引入了“注意机制”(Attention),使其能够在文本序列中正向和反向地跟踪单词之间的关系,适合在大规模分布式集群中进行训练。
1.2.2 工作原理
AI大语言模型的工作原理可以简单地描述为:接收一段自然语言文本作为输入,通过模型内部的复杂计算,生成与输入相关的新文本或图像作为输出。这个过程是基于深度学习的,需要大量的训练数据和计算资源来训练和优化模型。
1.3 AI大语言模型的应用场景
AI大语言模型已经被广泛应用于各种自然语言处理任务中,如机器翻译、文本摘要、情感分析、问答系统等。此外,它们还可以被用于图像生成任务中,如根据文字描述生成图像、图像风格转换等。这些应用都展示了AI大语言模型的强大功能和广泛应用前景。
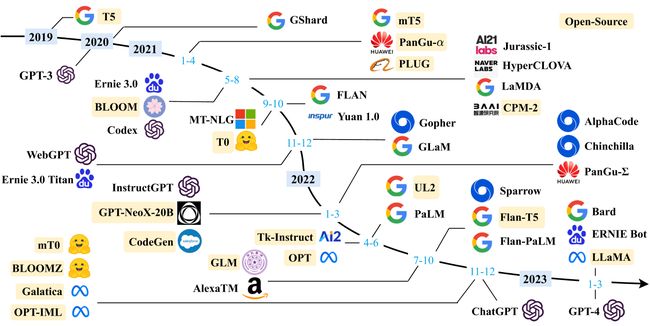
1.4 大语言模型发展时间线
1.4.1 大语言模型的发展时间线
-
2020年底:GPT-3问世,展示了强大的自然语言处理能力。
-
2021年:各大公司开始研发自己的大语言模型,如百度的ERNIE、阿里的ALBERT等。
-
2022年:OpenAI发布GPT-4,进一步提高了性能和效率。同时,Google发布了BERT的升级版T5。
-
2023年:ChatGPT和文心一言等大语言模型开始广泛应用,成为自然语言处理领域的主流技术。
1.4.2 国内外比较优秀的AI大语言模型网站和插件包括:
-
OpenAI官方网站:提供GPT系列模型的API接口和文档。
-
百度ERNIE:提供ERNIE系列模型的API接口和文档,支持中文处理。
-
阿里ALBERT:提供ALBERT系列模型的API接口和文档,支持中文处理。
-
Hugging Face模型库:收录了大量的大语言模型,包括GPT、BERT等,并提供API接口和文档。
-
ChatGPT插件:可以在各种应用中使用ChatGPT模型进行自然语言处理。
-
文心一言插件:可以在各种应用中使用文心一言模型进行自然语言处理。
2 飞桨大语言模型工具链
飞桨大语言模型工具链基于飞桨4D分布式并行技术开发,旨在提供高性能、灵活易用大语言模型全流程开发能力,覆盖开发、预训练、精调、压缩、推理、部署的全流程。
| Model | Pretrain | SFT | LoRA | Prefix Tuning | Generation | Quantization |
|---|---|---|---|---|---|---|
| LLaMA v1/v2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM-6B | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| ChatGLM2-6B | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bloom | ❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPT-3 | ✅ | ✅ | ✅ | ✅ | ||
| OPT | ✅ | ✅ | ✅ | |||
| GLM | ❌ | ✅ | ✅ | ✅ | ||
| Qwen | ✅ | ✅ | ✅ | ✅ | ✅ |
- ✅: Supported
- : In Progress
- ❌: Not Supported
LLM全流程工具介绍
PaddleNLP中的llm提供了模型预训练、精调(SFT、LoRA、Prefix Tuning)、量化、推理、部署全流程脚本,开发者可以根据自己的需求定制化自己的大语言模型。

2.1 环境准备
- paddlepaddle-gpu >= 2.5.1
- paddlenlp >= 2.6.1
- tiktoken (仅 Qwen 需要)
# 环境安装
# !git clone https://gitee.com/PaddlePaddle/PaddleNLP.git
%cd ~/PaddleNLP
!pip install -e . --user
2.2 预训练与微调
2.2.1 预训练
LLaMA v1/v2、GPT-3 目录中提供了模型预训练的数据准备和训练细节,可以自行查看。
# 千问模型预训练
python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" run_pretrain.py ./qwen/pretrain_argument_stage2.json
2.2.2 微调
目前精调统一脚本只支持LLaMA v1/v2、ChatGLM-6B、ChatGLM2-6B、Bloom、OPT、Qwen,其他模型精调使用详见对应模型目录。接下来我们将以Llama 2为例介绍如何使用统一脚本进行SFT、LoRA、Prefix Tuning。更多LoRA、Prefix Tuning请参见PEFT文档。
- 精调训练数据格式
为了方便用户测试,我们也提供示例数据集广告生成数据集,用户也可以仿照数据集的格式制作自己的数据集进行精调。我们支持的数据格式是每行包含一个字典,每个字典包含以下字段:
src:str, List(str), 模型的输入指令(instruction)、提示(prompt),模型应该执行的任务。tgt:str, List(str), 模型的输出。
样例数据:
{"src": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "tgt": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
...
- SFT
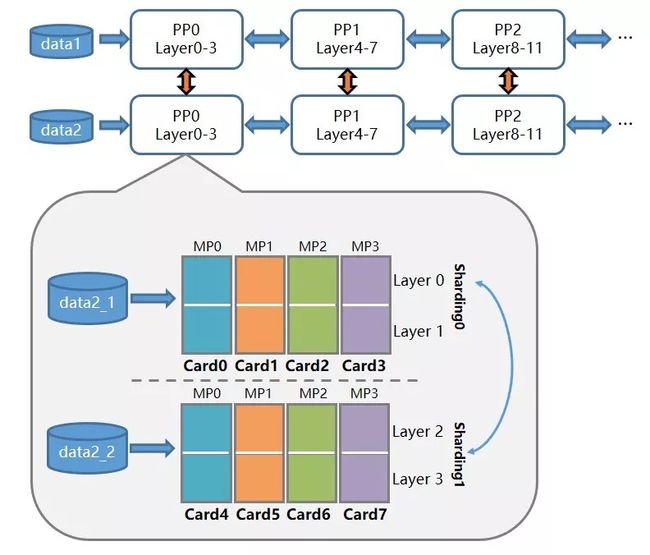
SFT(Supervised Fine-Tuning)依托飞桨提出的4D混合分布式并行能力,支持使用Trainer API轻松切换数据并行(DP)、张量并行(TP, Tensor Parallelism)、流水线并行(PP, Pipeline Parallelism)(目前仅支持Llama)等多种分布式训练策略。
4D 混合并行策略的最佳配置实践如图下所示,在单机内使用通信量较大,适合使用机器内卡间通信的张量并行(张量并行又称模型并行,MP)和分组参数切片(Sharding)的2D组合策略;训练千亿规模模型时,叠加流水线并行策略使用多台机器共同分担;同时叠加数据并行来增加并发数量,提升训练速度。
- LoRA
Transformer模型中包含许多Linear层需要进行密集的矩阵乘法计算,而这些通常具有全秩(full rank)特性。LoRA提出冻结预训练的权重矩阵, 通过引入两个低 rank 矩阵 A B AB AB(图中橙色的两个矩阵) 来近似权重的更新过程 W 0 + Δ W = W 0 + B A W_0+\Delta W=W_0+B A W0+ΔW=W0+BA , 其中 B ∈ R d × r , A ∈ R r × k B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k} B∈Rd×r,A∈Rr×k,实验表明将输入表达随机投影到较小的子空间模型仍然可以有效地学习下游任务,并大幅降低计算的显存需求。

PaddleNLP LoRA API支持数据并行、张量并行等多种分布式训练策略,可以通过控制tensor_parallel_degree 调整并行训练策略。LoRA策略默认应用在所有Linear层,可拓展至单机LoRA微调千亿模型。
- Prefix Tuning
Prefix Tuning受提示学习(Prompt learning)的影响,加入的一部分 Prefix Embedding 作为连续型提示进行训练。Prefix Embedding是由专门的 Prefix Encoder 网络生成的数个张量,会以 past_key_value 的方式被插入到语言模型每一层的 hidden_state 之前。

PaddleNLP Prefix Tuning API支持数据并行(DP)、张量并行(TP)等多种分布式训练策略,可以通过控制tensor_parallel_degree 调整并行训练策略。
2.3 模型推理
此外 PaddleNLP 还提供了高性能推理模型,从而加速 LLM 模型的部署落地,详细文档请看:Inference Model
2.3.1 动态图推理
# 预训练&SFT动态图模型推理
python predictor.py \
--model_name_or_path meta-llama/Llama-2-7b-chat \
--data_file ./data/dev.json \
--dtype float16
# LoRA动态图模型推理
python predictor.py \
--model_name_or_path meta-llama/Llama-2-7b-chat \
--lora_path ./checkpoints/llama_lora_ckpts
# Prefix Tuning动态图模型推理
python predictor.py \
--model_name_or_path meta-llama/Llama-2-7b-chat \
--data_file ./data/dev.json \
--prefix_path ./checkpoints/llama_pt_ckpts
2.3.2 静态图推理
# 首先需要运行一下命令将动态图导出为静态图
# LoRA需要先合并参数,详见3.7LoRA参数合并
# Prefix Tuning暂不支持
python export_model.py \
--model_name_or_path meta-llama/Llama-2-7b-chat \
--output_path ./inference \
--dtype float16
# 静态图模型推理
python predictor.py \
--model_name_or_path inference \
--data_file ./data/dev.json \
--dtype float16 \
--mode static
2.3.3 Inference Model 推理
此外 PaddleNLP 还提供了高性能推理模型,从而加速 LLM 模型的部署落地,详细文档请看:Inference Model
支持的模型列表如下所示:
| Model | Inference Model | PTuning | Wint8 | PTQ |
|---|---|---|---|---|
| LLaMA1/2 | ✅ | ✅ | ✅ | ✅ |
| ChatGLM | ✅ | ✅ | ✅ | ❌ |
| ChatGLM2 | ✅ | ❌ | ❌ | ❌ |
| BaiChuan1 | ✅ | ✅ | ✅ | ✅ |
| BaiChuan2-7B | ❌ | ❌ | ❌ | ❌ |
| BaiChuan2-13B | ✅ | ✅ | ✅ | ✅ |
| Bloom | ✅ | ✅ | ✅ | ❌ |
| GPT-3 | ✅ | ❌ | ❌ | ❌ |
| Qwen | ❌ | ❌ | ❌ | ❌ |
2.4 服务部署
Gradio UI服务化部署
这儿提供了几个案例,可以自行查看学习:
-
【大模型专区】文案生成贴心小助手:基于chatglm-6B实现文案生成小助手,满足您的各种需要。
-
【大模型专区】大语言模型Bloom初体验:本项目基于【PaddleNLP-develop】中llm(大语言模型)——【Bloom】大语言模型和通过调用【文心千帆 WENXINWORKSHOP】中的BLOOMZ-7B模型的api完成。
3 Ernie Bot SDK
本教程使用Ernie Bot SDK封装的文心一言能力,文心一言是百度基于文心大模型技术推出的知识增强型大语言模型。
3.1 环境安装
运行下面代码,进行项目环境的安装和配置:
# 安装环境
!pip install erniebot
3.2 如何使用
使用ERNIE Bot SDK之前,请首先申请并设置鉴权参数。具体请参考认证鉴权。
3.2.1 Python接口
import erniebot
# List supported models
models = erniebot.Model.list()
print(models)
# ernie-bot 文心一言模型(ernie-bot)
# ernie-bot-turbo 文心一言模型(ernie-bot-turbo)
# ernie-bot-4 文心一言模型(ernie-bot-4)
# ernie-bot-8k 文心一言模型(ernie-bot-8k)
# ernie-text-embedding 文心百中语义模型
# ernie-vilg-v2 文心一格模型
# Set authentication params
erniebot.api_type = "aistudio"
erniebot.access_token = ""
# Create a chat completion
response = erniebot.ChatCompletion.create(model="ernie-bot", messages=[{"role": "user", "content": "你好,请介绍下你自己"}])
print(response.get_result())
3.2.2 命令行接口(CLI)
# List supported models
erniebot api model.list
# Set authentication params for chat_completion.create
export EB_API_TYPE="aistudio"
export EB_ACCESS_TOKEN=""
# Create a chat completion (using ernie-bot, ernie-bot-turbo, etc.)
erniebot api chat_completion.create --model ernie-bot --message user "请介绍下你自己"
# Set authentication params for image.create
export EB_API_TYPE="yinian"
export EB_ACCESS_TOKEN=""
# Generate images via ERNIE-ViLG
erniebot api image.create --model ernie-vilg-v2 --prompt "画一只驴肉火烧" --height 1024 --width 1024 --image-num 1
3.3 对话补全(Chat Completion)
ERNIE Bot SDK提供具备对话补全能力的ernie-bot、ernie-bot-turbo、ernie-bot-4、ernie-bot-8k等文心一言系列模型。
不同模型在效果、速度等方面各有千秋,大家可以根据实际场景的需求选择合适的模型。
以下是调用ernie-bot模型进行单轮对话的示例:
import erniebot as eb
# 创建单轮对话
eb.api_type = 'aistudio'
# 可以使用自己的access_token
eb.access_token = "#############################"
prompt = f"""你好呀,请为我描述一下龙行dada的含义。"""
def generate(prompt):
chat_completion = eb.ChatCompletion.create(
model='ernie-bot-4',
messages=[{'role': 'user', 'content':prompt}],
)
return chat_completion.result
generate(prompt)
'龙行达达是一种非正式的表达,形容一个人的行为或举止显得特别威风凛凛、有力量感和豪迈。在这个词语中,“龙行”象征着威严和力量,“达达”则是一种口语化的表达,类似于“大步走”或“阔步前行”的意思。总的来说,“龙行达达”可以用来形容一个人的行走或举止特别引人注目的场景。这个词语的使用通常是带有赞美或欣赏的意味,强调个体的豪迈、自信和有力量感的形象。然而,它也可以在幽默或戏谑的语境中使用,带有一定的夸张或调侃意味。'
3.4 典型示例-文生图(Image Generation)
ERNIE Bot SDK提供具备文生图能力的ernie-vilg-v2大模型。
该模型具备丰富的风格与强大的中文理解能力,支持生成多种尺寸的图片。
AI 作画,基于文心大模型,根据用户输入的文本,自动创作图片。AI 作画-高级版涉及2个接口,分别为:提交请求、查询结果。
-
提交请求:支持传入文本、分辨率、数量、参考图等参数,创建 AI 作画任务,获得任务ID。
-
查询结果:用于在任务创建后,查看图片生成状态。待图片生成完毕,通过查询接口即可查看生成图片的地址链接。
-
并发概念:并发数指 AI 作画高级版服务同时能处理的请求数量。上一个任务执行完,拿到结果后,并发才结束。
-
若您对于 prompt 输入有疑问,请参考 “AI作画-高级版使用指南” 。
-
并发数:付费使用后AI作画-高级版图片生成处理过程并发提升为2
- 获取Access Token
通过API Key和Secret Key获取的access_token,参考“Access Token获取”
- POST 方式调用
| 参数 | 是否必选 | 类型 | 描述 |
|---|---|---|---|
| prompt | 是 | string | 生图的文本描述。仅支持中文、日常标点符号。不支持英文,特殊符号,限制 200 字 |
| width | 是 | integer | 图片宽度,支持:512x512、640x360、360x640、1024x1024、1280x720、720x1280、2048x2048、2560x1440、1440x2560 |
| height | 是 | integer | 图片高度,支持:512x512、640x360、360x640、1024x1024、1280x720、720x1280、2048x2048、2560x1440、1440x2560 |
| image_num | 否 | number | 生成图片数量,默认一张,支持生成 1-8 张 |
| image | 否 | string | 参考图,需 base64 编码,大小不超过 10M,最短边至少 15px,最长边最大 8192px,支持jpg/jpeg/png/bmp 格式。优先级:image > url > pdf_file,当image 字段存在时,url、pdf_file 字段失效 |
| url | 否 | string | 参考图完整 url,url 长度不超过 1024 字节,url 对应的图片需 base64 编码,大小不超过 10M,最短边至少 15px,最长边最大8192px,支持 jpg/jpeg/png/bmp 格式。优先级:image > url > pdf_file,当image 字段存在时,url 字段失效请注意关闭 URL 防盗链 |
| pdf_file | 否 | string | 参考图 PDF 文件,base64 编码,大小不超过10M,最短边至少 15px,最长边最大 8192px 。优先级:image > url > pdf_file,当image 字段存在时,url、pdf_file 字段失效 |
| pdf_file_num | 否 | string | 需要识别的 PDF 文件的对应页码,当pdf_file 参数有效时,识别传入页码的对应页面内容,若不传入,则默认识别第 1 页 |
| change_degree | 否 | integer | 参考图影响因子,支持 1-10 内;数值越大参考图影响越大 |
# 获取Access Token
import requests
import json
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=xxxx&client_secret=xxxx"
payload = ""
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()
# POST 方式调用
import erniebot
erniebot.api_type = "yinian"
erniebot.access_token = "24.d311c558615a181ebd75090adccd5969.2592000.1704099017.282335-44171052"
response = erniebot.Image.create(
model="ernie-vilg-v2",
prompt="雨后的桃花,8k,辛烷值渲染",
width=512,
height=512
)
="雨后的桃花,8k,辛烷值渲染",
width=512,
height=512
)
print(response)
输出示例:
| 夜晚的星空下的古老城堡,8k,辛烷值渲染 | 雨后的桃花,8k,辛烷值渲染 |
|---|---|
 |
 |
第2课 AI图像生成开发教程之认识AI大语言模型就为大家讲解到这儿,如果对AI图像生成感兴趣或想了解AI图像生成技术,希望通过此教程能对大家有所帮助。有任何问题可以扫码加入我的社区频道,咱们一起探索AI图像生成的奇妙。从初始-遇见-相知过程很美好,希望课程的内容也是如何,你与我思维的碰撞亦是如此。敬请期待第3课 AI图像生成开发教程之文心一言遇见Stable Diffusion。

请点击此处查看本环境基本用法.
Please click here for more detailed instructions.