2023年1月20日-2024年1月26日(阅读SeisInvNet加强版、调整参数)
一、前言
上周阅读了SeisInvNet论文,本周阅读它的加强版,并尝试对InversionNet的网络框架进行一些小的修改,调整参数、添加组件等。
二、SeisInvNet
标题:Deep-learning seismic full-waveform inversion for realistic structural
models(用于真实结构模型的深度学习地震全波形反演)
作者:Bin Liu1, Senlin Yang2, Yuxiao Ren2, Xinji Xu3, Peng Jiang2, and Yangkang Chen4(和SeisInvNet有共同作者,应该是同一个实验团队)
编辑于2019年7月1日收到手稿;于2020年8月27日收到修订稿;于2020年10月4日提前出版;于2021年1月4日在线出版。
论文主要贡献:
- 设计了一种创建致密层/断层/盐体模型的压缩波速度建模方法,可以自动构建大量的模型;
- 在SeisInvNet的基础上,不仅使用共炮点道集,还从共接收点道集中提取特征;
在本文中,基于时域中的声波方程对合成数据进行建模:
![]() (1)
(1)
其中a表示波速,u表示压力,即,声波场字母x和y表示空间坐标,t是时间,f(x,y,t)是源的函数。
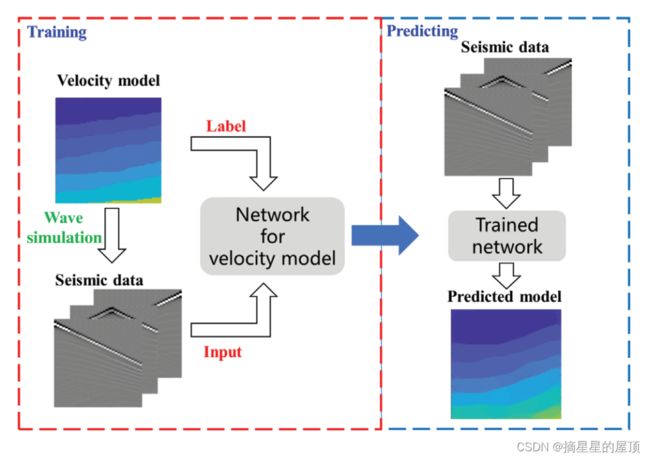
图1 基于DL的速度模型反演算法的工作流程
- 地震数据D:数据的大小为[S × R × T]式中,S、R和T分别表示记录的激发次数、接收器数量和时间步长;
- 速度模型V:大小为[H,W],分别表示速度模型的高度和宽度,大小为[100,100];
2.1 构造致密层、断层和盐体模型
在构造致密层模型时,首先生成致密层构造模型,然后在其上随机添加断裂构造,从而设计出含一个或两个断层或盐体的致密层模型。对于密层模型,难点在于如何在有限的深度和勘探分辨率下,保证各层的连续性和变异性,增加地下介质的数量。按照以下步骤生成致密层模型:
- 1)随机生成一条曲线作为模型的第一个界面。
- 2)通过根据上界面进行一些调整来迭代生成曲线,以确保两个相邻界面之间没有剧烈变化并保持真实感。
- 3)将P波速度值填入相邻两界面之间的介质中,以介质越深对应的速度值越大为准则。
本文的目标反演模型尺寸设定为100 × 100。在模型周围,在左侧、右侧和底部有一个额外的20网格吸收边界。文章定义了一个由多个三角和线性方程组成的函数,以生成连续的,波动的和复杂的曲线。函数和单独的方程如下所示:
![]()
![]()
![]()
![]() (2)
(2)
其中, 、
、 和
和 、
、![]() 是不同三角方程的参数,
是不同三角方程的参数, 和
和 分别是控制界面倾斜和深度的常数。让
分别是控制界面倾斜和深度的常数。让![]() ,
,![]() ,而
,而![]() 是随机给定的,
是随机给定的, 是曲线的主要部分。为了使两个相邻层之间的趋势相似,与前一个界面相比,每个界面的都应进行调整。
是曲线的主要部分。为了使两个相邻层之间的趋势相似,与前一个界面相比,每个界面的都应进行调整。 项的周期和幅值在每个界面上分别指定。最后,对于
项的周期和幅值在每个界面上分别指定。最后,对于 ,和被分配以分别控制当前界面的深度和倾斜。通过以上定义,可以得到多个具有相同趋势的接口,如下图所示。
,和被分配以分别控制当前界面的深度和倾斜。通过以上定义,可以得到多个具有相同趋势的接口,如下图所示。

图2 由y组成的多个接口图
为了进一步削弱函数2中三角项对曲线的光滑性的影响,使模型更加真实,从每条曲线中选取一些离散点,通过重新连接这些点来形成新的曲线。这样,界面的随机性也增加了。该过程如下图3所示:

图3 曲线和相应的模型以不同的构造方式
所有界面确定后,自上而下设置各层的纵波速度值,取值范围为[1500, 4000] m/s。 同时,根据真实的土介质的固结效应,将各层的速度值设定为随层深增加而增加。在我们的实现中,我们将相邻层之间的速度差设置为大于200 m/s。根据所需的最大波速 、前一层介质的波速
、前一层介质的波速![]() 、下一层介质的数量
、下一层介质的数量![]() 和随机项,选择各层介质的波速范围。速度范围如下:
和随机项,选择各层介质的波速范围。速度范围如下:
![]() (3)
(3)
在图4中,对不同类型的层模型(5到9层)的速度值变化进行了统计分析。两种模型的速度值随深度的增加而增加,这一趋势是一致的。通过以上曲线设计、界面设置、速度分配等过程,可以构建出真实的结构模型。最终生成五到九层的密集层模型,每层有1000个模型。

图4 训练集中稠密层模型各深度处的平均波速。
在密层模型设计的基础上,进一步研究了故障设置问题。使用密集层模型和故障线![]() 作为输入,并且生成在随机位置的故障模型。项
作为输入,并且生成在随机位置的故障模型。项![]() 可以定义为对角线,也可以设置为曲线,例如抛物线。其步骤如下:
可以定义为对角线,也可以设置为曲线,例如抛物线。其步骤如下:
- 1)随机生成断层起始位置P和垂直方向移动量
 。
。 - 2)随机选择运动部分,即,上层或下层以及移动距离。
对于移动部分的每个点[![]() ],更新后的位置[
],更新后的位置[![]() ]可以通过以下公式计算:
]可以通过以下公式计算:
![]() (4)
(4)

图5 (a)前面使用的分层模型;(b)模型按照断层线平移;(c)获得了故障模型
在密层模型的基础上设计了盐体模型。盐体可以看作是一个从底部向上上升的致密地层,而盐体在流入上部地层时会发生波动,使用高斯函数来模拟渐进波动:
![]() (5)
(5)
其中 、
、 和分别是幅度、中心和标准偏差。为了模拟盐体对致密层的影响,其中较深的层将具有较大的变形,随机生成一组高斯曲线,如图6所示。原始的层状模型按照这组高斯曲线起伏,模拟盐体的侵入影响。最后,通过具有随机参数的抛物线设计一个新的岩体,并给出范围为[4400, 4500]m/s的波速。盐体的建造过程如图6所示。
和分别是幅度、中心和标准偏差。为了模拟盐体对致密层的影响,其中较深的层将具有较大的变形,随机生成一组高斯曲线,如图6所示。原始的层状模型按照这组高斯曲线起伏,模拟盐体的侵入影响。最后,通过具有随机参数的抛物线设计一个新的岩体,并给出范围为[4400, 4500]m/s的波速。盐体的建造过程如图6所示。

图6 (a)高斯曲线的集合,模拟盐体的侵入影响。(b)盐体曲线。(c-e)分别建立了层状介质速度模型、考虑上隆作用的速度模型和盐体速度模型。
根据提出的密层、断层和盐体模型的设计方法,批量生成了18,000组模型(每种类型包含6000个模型),用于下一步的网络训练。其中一些如图7所示。

图7 设计了密层、断层、盐体速度模型样本
2.2 深度学习网络框架
网络架构和修改如下:
1)编码器:对于地震数据,考虑到地震数据与速度模型之间的弱对应关系,使用CNN或全连接网络时存在一些麻烦。SeisInvNet的主要优点之一是分析和提取地震数据的特征,特别是在编码器方面。该方法采用卷积方法从共炮点道集中提取全局信息和邻域信息,并采用One-Hot编码(单位为1,其余为0)标记道,增加了单道信息,为引入全连通网络提供了可能。对于尺寸为[S × R × T]的地震数据,通过两组S共炮剖面的卷积[R × T],得到全局信息和邻域信息,其大小分别为[ R × C]和[ R × T]分别表示。此外,源和接收器的位置信息也被编码的一个One-hot编码的长度为R + S。通过这种方式,每个轨迹可以被编码以获得大小为T+R+S+C的数据,其包含比先前单个轨迹更多的信息。
改进:为了尽可能多地提取数据的有效特征,本文进一步考虑了R共接收道集的[S × T]。也就是说,从两个方面获得数据信息,公共炮点和公共接收点。相应地,全局信息将具有来自两个配置文件的源。具体地,对两种地震数据道集(即,共炮点道集和共接收器道集),并且获得长度为C的两个向量。同样,相邻信息也来自两个轮廓的相邻道,然后线性加权作为最终的长度为R的相邻信息。
通过编码器,每条地震道的大小增加到T+S+R+C+C,比原始SeisInvNet中的地震道稍大。这样,每条轨迹都包含了更多的有效信息,为全连接网络提供了更多的优势。图8a和8b分别显示了SeisInvNet和本文提出的编码器部分方法之间的差异。

图8 在编码器部分比较了以前的SeisInvNet和本文提出的方法。(a)SeisInvNet,它只对来自共炮点道集的信息进行编码。(b)本文的方法,它编码的信息,从共炮集和共接收器收集。
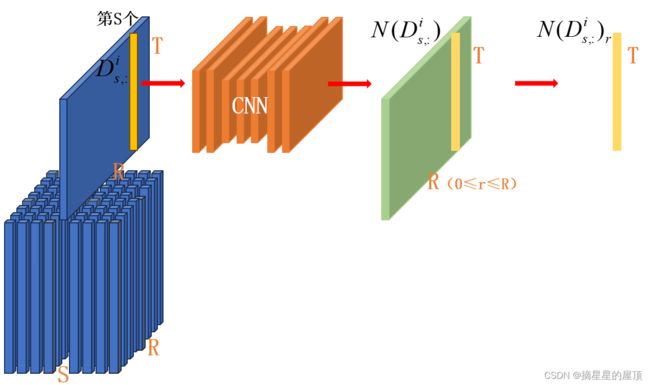
2)生成器:给定编码的S × R轨迹,这部分的主要目的是通过一个全连接网络获得S × R特征图。对于时间序列到空间序列的映射问题,全连通网络被认为是最直接、最有效的方法。我们提取每个编码轨迹的特征,其大小为[w × d]用于模型构建。
3)解码器:在这一部分中,生成的S × R特征被解码以获得速度模型V。The drop-out用于确保网络不依赖于特定功能。通过从某个通道随机丢弃一些特征,结果将不会严重依赖于某些特征。通过这种方式,即使在丢失某些数据之后,也可以实现良好的反演结果,这将在稍后讨论。
4)损失函数:损失函数决定向速度模型逼近的方向。均方误差在速度反演文献中被广泛使用。在网络中,计算预测模型和实际模型之间的失配以导出梯度并更新网络参数。MSE损失函数定义如下:
![]() (6)
(6)
其中,![]() 和
和 是第
是第![]() 个模型的预测和相应的地面实况。
个模型的预测和相应的地面实况。
MSSIM:SSIM和MSSIM比MSE能更好地表示两个图形之间的结构相似性,已被广泛应用于许多计算机视觉任务中。为了更好地优化预测模型的结构特性,本文还采用了MSSIM作为损失函数。在以前的工作中(Li等人,2020年),这种损失函数的优势得到了证明。SSIM的方程表示如下:
![]() (7)
(7)
其中x和y分别表示两个图像中的两个对应窗口。项μx和μy是x和y的平均值,σx和σy是x和y的方差,而σxy是x和y的协方差。该度量两个图像窗口的相似性。该值的范围从0到1,值越接近零,相似度越低。利用SSIM,本文中的损耗项![]() 定义为:
定义为:
![]() (8)
(8)
其中 是模型(图像),
是模型(图像),![]() 是的窗口,以k为中心,宽度为r;定义与
是的窗口,以k为中心,宽度为r;定义与![]() 相似。因此,该等式通过对所有位置和宽度的窗口上的SSIM求和来计算相似性。项
相似。因此,该等式通过对所有位置和宽度的窗口上的SSIM求和来计算相似性。项![]() 是宽度为r的窗口的SSIM的权重。图9显示了网络的架构。
是宽度为r的窗口的SSIM的权重。图9显示了网络的架构。

图9 本文提出的方法用于模型预测。
通过对上述两个损失函数的计算,将它们相加,得到最终的损失函数:
![]() (9)
(9)
三、简单创意收集
3.1 Dropout机制
Dropout是一种在深度学习领域中常用的正则化技术,用于防止过拟合和提高模型的泛化能力。通过随机关闭网络中的一部分神经元,Dropout使得模型在训练过程中更加关注特征的组合,而非单一特征的重要性。其核心思想是在训练过程中随机地丢弃神经网络的某些单元,可以使得模型在训练时不会过于依赖任何一个特定的神经元。当丢弃某些神经元时,其他神经元的权重会相应地调整,以弥补被丢弃的神经元所负责的特征表示。这样,模型能够在训练过程中更加关注于重要的特征组合,而非单一特征的重要性。
在使用Dropout时,通常会有一个概率p,表示在每次训练迭代中随机丢弃网络中神经元的比例。一般来说,p的取值范围在0.2到0.5之间。通过调整Dropout的概率p,可以在一定程度上控制模型的复杂度和泛化能力。
需要注意的是,在使用Dropout时,通常会将Dropout层放置在全连接层之间。这是因为全连接层之间的连接权重通常是共享的,所以Dropout可以更加有效地避免过拟合问题。此外,为了使得模型在测试时能够正常工作,通常会在训练结束后将所有神经元重新启用(即不丢弃任何神经元),并进行一次前向传播操作,以获得未丢弃的神经元的输出结果。
在这里说明一下,最初看到这个Dropout机制的时候,很多文章说在训练的时候使用(每次训练的网络都不一样),在测试的时候不使用(测试使用一个大网络)。当时,我在思考应该如何区分训练和测试呢,然后我想到可以写成两个类:InversionNetTrain和InversionNetTest。在查找资料的过程中,看到有博主提示,不需要将网络区分开,可以采取这种方式:
测试阶段随机采样时需要使用model.train(),而测试阶段直接组装成一个整体大网络时需要使用model.eval()。
关于模式设置:
- 训练模式 (
model.train()):在训练模式下,某些层(如 Dropout 和 BatchNorm)的行为与评估模式不同。例如,Dropout 层在训练模式下会随机将输入张量中的一部分元素设置为零,以防止过拟合。BatchNorm 层会使用 mini-batch 的统计数据进行内部计算。 - 评估模式 (
model.eval()):在评估模式下,这些层的行为与训练模式不同。例如,Dropout 层不会更改输入,BatchNorm 层使用在训练阶段计算得到的统计数据(通常是在训练的最后阶段计算得到的)。
高斯dropout:每个节点可以看做乘以了p(1-p) ,所有节点都参与训练。
class GaussianDropout(nn.Module):
def __init__(self, p=0.5):
super(GaussianDropout, self).__init__()
if p <= 0 or p >= 1:
raise Exception("p value should accomplish 0 < p < 1")
self.p = p
def forward(self, x):
if self.training:
# 式子算起来有些许区别。
stddev = (self.p / (1.0 - self.p))**0.5
epsilon = torch.randn_like(x) * stddev
return x * epsilon
else:
return x
学习参考:Dropout的深入理解(基础介绍、模型描述、原理深入、代码实现以及变种)_dropout模型-CSDN博客
3.2 双线性插值
插值在图像处理上是指利用已知邻近像素点的灰度值或RGB中的三色值产生未知像素点的灰度值或RGB三色值,目的是由原始图像再生出具有更高分辨率的图像。通俗一点理解就是已知推导未知,利用已知的点来“猜”未知的点,图像领域插值常用在修改图像尺寸的过程,从而强化图像,有最近邻插值(计算速度最快,但是效果最差),双线性插值(用原图像中4(2*2)个点计算新图像中1个点,效果略逊于双三次插值,速度比双三次插值快,属于一种平衡美,在很多框架中属于默认算法),双三次插值(用原图像中16(4*4)个点计算新图像中1个点,效果比较好,但是计算代价过大)等等。双线性插值由于折中的插值效果和运算速度,运用比较广泛。

线性插值法是认为现象的变化发展是线性的、均匀的,所以可利用两点式的直线方程式进行线性插值。 单个维度的线性插值只利用两点的对应值推算,两点本身的偶然性会造成结果的误差较大,因而在图像处理中多采用双线性插值。
在计算机视觉及图像处理领域,双线性插值是一种基本的重采样技术。图像的双线性插值放大算法中,目标图像中新创造的象素值,是由源图像位置在它附近的2*2区域4个邻近象素的值通过加权平均计算得出的。双线性内插值算法放大后的图像质量较高,不会出现像素值不连续的的情况。然而此算法具有低通滤波器的性质,使高频分量受损,所以可能会使图像轮廓在一定程度上变得模糊。
在Unet网络的解码器部分,可以使用双线性插值对上采样后的特征图进行进一步的空间恢复。双线性插值可以通过torch.nn.functional.interpolate函数实现。在该函数中,可以将mode参数设置为bilinear,以指定使用双线性插值。

学习参考:
① 双线性插值(Bilinear Interpol)原理及应用-CSDN博客。
②东北石油大学—孙英杰(基于Unet的地震信号降噪及重构方法研究)
3.3 注意力机制
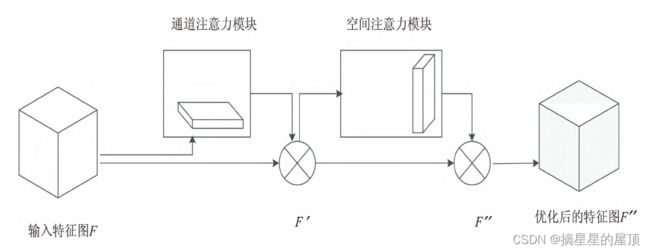
3.3.1 CBAM注意力模块
2018年,WOO等人提出了CBAM(Convolutional Block Attention Module),同时结合了通道注意力和空间注意力,是一种简单且有效的卷积神经网络注意力模块。CBAM模块如下图所示,它的运算分为两个部分,首先将通道注意力![]() 与输入特征图
与输入特征图 相乘,得到特征图
相乘,得到特征图![]() ,然后将空间注意力
,然后将空间注意力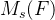 与按照元素相乘,得到特征图
与按照元素相乘,得到特征图![]() 。
。
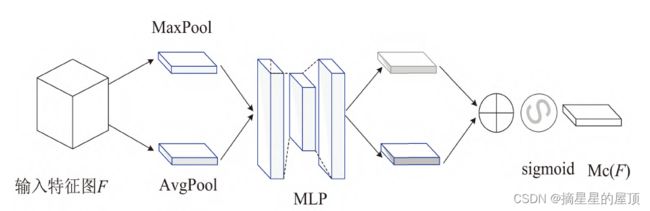
(1)通道注意力模块:主要关注哪些特征为有意义的特征,其计算过程为:
![]()
其中,为输入特征图,![]() 为通道注意力模块,
为通道注意力模块, 为sigmoid激活函数,
为sigmoid激活函数,![]() 为多层感知器,
为多层感知器,![]() 为平均池化,
为平均池化,![]() 为最大池化。
为最大池化。
它将输入分别通过最大值池化和平均池化得到两个特征图,然后将这两个特征图输入到多层感知器中做降维、升维处理,之后将从多层感知器中得到两个特征图进行加和,同时经过sigmoid激活函数处理后,得到通道注意力,如下图所示。
(2)空间注意力模块:主要关注哪些地方特征为有意义的特征,是对通道注意力的补充,其计算过程描述如下:
![]()
其中,![]() 为空间注意力模块,
为空间注意力模块, 为卷积层运算,为sigmoid激活函数,
为卷积层运算,为sigmoid激活函数,![]() 为平均池化,
为平均池化,![]() 为最大池化。首先将输入
为最大池化。首先将输入![]() 分别通过最大值池化和平均池化,并将它们连接起来,然后,利用卷积网络将其降维一通道,之后,经过sigmoid激活函数得到空间注意力模块,如下图所示。
分别通过最大值池化和平均池化,并将它们连接起来,然后,利用卷积网络将其降维一通道,之后,经过sigmoid激活函数得到空间注意力模块,如下图所示。

CBAM_Unet++结构示例如下图所示:
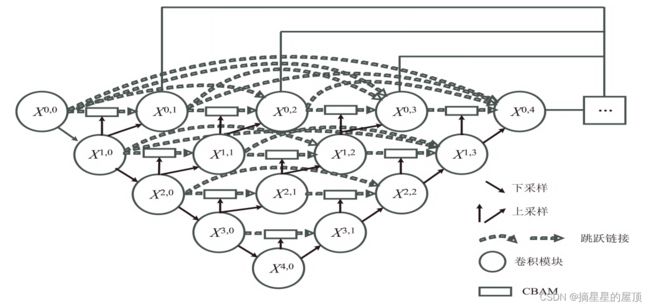
学习参考:《基于改进Unet++的地震断层识别方法研究》 —张利霞(东北石油大学)

学习参考:刘霞《基于融合残差注意力机制的卷积神经网络地震信号去噪》
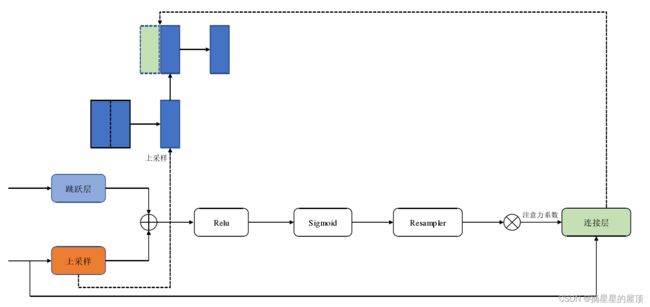
3.3.2 Attention Gate注意力门控模块
注意力门控最重要的作用是通过简单地找到增加目标区域价值的方法,将网络的注意力引向目标区域。Attention Gate具有结构简单、相对轻量、容易融入U-Net网络模型等其他形式网络等特点。经过注意力机制训练的模型能够对输入图像不相关区域进行抑制,使网络集中于显著特征。在兼顾模块轻量化性质的前提下,网络的总体性能和灵敏度可以在几乎没有额外成本的情况下得到改善。
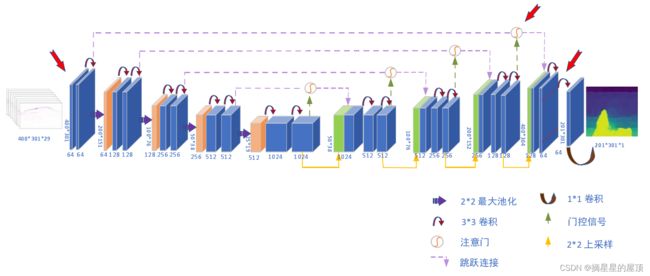
为了建立初始速度模型神经网络架构(IVMB), 将U-Net 和FCN网络架构相结合对AttentionU-Net进行了改进,使其成为一个能适应地震速度模型需要的神经网络架构。如上图所示,网络主体类似于原U-Net网络,总共使用了22 个卷积层、4个池化层、4个上采样层和1个裁剪层。网络层下面数字表示输出特征通道数,左面数字表示特征图大小。卷积核尺寸为3x3, 每个卷积后有一个Relu 函数,最大池化层下采样因子与采样层上采样因子尺寸均为2x2。 深度神经网络具有4个下采样过程,4个上采样过程,也就是要确保网络具有充分深度来提取速度特征,也不至于使得网络模型变得太过复杂。Attention U-Net网络架构可以分为两部分:左半部分是收缩路径,用于捕获地质特征,提高网络的特征提取能力。右半部分是上采样,在特征图上使用反卷积来实现像素级密集预测。
学习参考:东北石油大学—孙德辉《基于深度学习的全波形反演初始模型构建方法研究》
3.4 dropblock
DropBlock是一种正则化技术,用于防止深度神经网络的过拟合。它通过在训练过程中随机丢弃网络中的一部分特征区域(block)来增加模型的泛化能力,使得模型在训练过程中不能过度依赖这些神经元。
DropBlock的具体实现方法是在训练过程中,根据预设的概率,随机地将网络中的某些神经元设为0,从而屏蔽掉它们的输出。这个过程可以在卷积层或全连接层中实现。由于DropBlock是随机地屏蔽神经元的输出,因此可以看作是对数据的一种有噪声的增强,有助于提高模型的鲁棒性。
然而,DropBlock也存在一些缺点。首先,由于在训练过程中需要随机地屏蔽神经元的输出,因此每次前向传播时网络的结构都会发生变化,这可能会导致训练不稳定。其次,DropBlock需要预设一个丢弃概率和丢弃块的大小,这些超参数的选择会对模型的性能产生影响。
DropBlock模块的参数包括block_size和γ,其中block_size代表想drop掉的block的尺寸大小,正常可以取3、5、7;γ代表drop过程中的概率。因此,DropBlock概率(γ)设置范围应该是0到1之间的小数,表示drop的概率。具体设置范围需要根据实际任务和数据集进行调整和优化。
总结:DropBlock是从一个层的特征图中丢弃连续的区域,是dropoutout的一种结构化形式。
添加DropBlock后的卷积单元如下图所示:

四、遇到的问题及解决
4.1 残差连接与跳跃连接
残差连接和跳跃连接在神经网络中都引入了直接的连接,以帮助信息的传递和梯度的流动,进而提高模型的性能和训练效果。但两者存在一些不同之处:
- 连接方式:跳跃连接是指在神经网络的某些层中,将输入与差部分进行简单相加,从而创建一个绕过某些层的捷径。而残差连接则是通过添加恒等映射,将上一个残差块的信息没有阻碍的流入到下一个残差块,提高了信息流通。残差连接(Residual Connections)是跳跃连接(skip-connection)的一种,缓解了在深度神经网络中增加深度带来的梯度消失问题。
- 直观理解:从直观上看,残差学习需要学习的内容少,因为残差一般会比较小,学习难度会减小。
- 作用:跳跃连接通常通过在卷积层之间添加恒等映射来实现。而残差连接则是在某些层入直接与输出相加,从而创建一个绕过某些层的捷径。
总的来说,残差连接和跳跃连接在神经网络中都起到了提高模型性能和训练效果的作用,但两者在连接方式和作用上存在一些不同。
4.2 代码运行部分报错
allocated; 297.00 MiB free; 4.71 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF


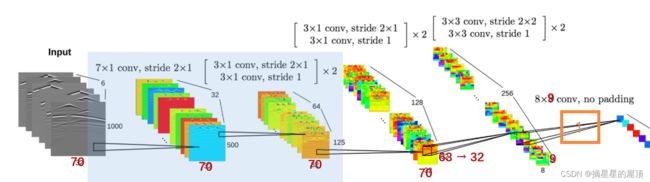
五、InversionNet简单实验
在本周借用闵老师的笔记本电脑完成了个简单的对比实验。
本次实验的共同设置如下:epoch=240,数据集大小=500,batch_size=64,step=1679。
| 实验改动 | loss值 | MAE | MSE | SSIM | ||
| Smoothed | Value | Relative | ||||
| ①架构无修改 | 0.0282 | 0.0263 | 57.1min | 0.2774 | 0.1233 | 0.6044 |
| ②位置1添加dropout=0.5 | 0.0387 | 0.033 | 57.04min | 0.2935 | 0.1383 | 0.5796 |
| ③位置2添加dropout=0.5 | 0.0428 | 0.0411 | 1.005hr | 0.2832 | 0.1272 | 0.6080 |
| ④位置1和2同时添加dropout=0.5 | 0.0493 | 0.033 | 57.98min | 0.2895 | 0.1322 | 0.5945 |

loss值展示:
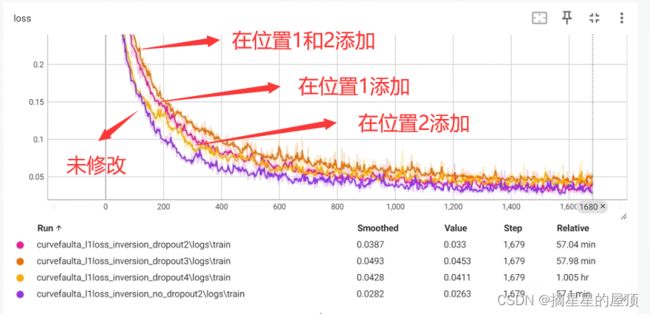

在InversionNet实验中的dropout均设置为0.5,如果设置低一点会不会效果会更好一些?另外,数据集设置太小了,效果不是很明显,计划下周重新进行尝试。