解密人工智能:探索机器学习奥秘
个人主页:聆风吟
系列专栏:网络奇遇记、数据结构
少年有梦不应止于心动,更要付诸行动。
文章目录
- 前言
- 一. 机器学习的定义
- 二. 机器学习的发展历程
- 三. 机器学习的原理
- 四. 机器学习的分类
-
- 3.1 监督学习
- 3.2 无监督学习
- 3.3 半监督学习
- 3.4 强化学习
- 3.5 四种分类对比
- 五. 机器学习的应用场景
- 六. 机器学习的未来发展趋势
- 全文总结
前言
机器学习(Machine Learning)是一种让计算机通过数据自动学习的技术。它可以让计算机从数据中自动学习规律和模式,并根据这些规律和模式进行预测和决策。
一. 机器学习的定义
机器学习是一种让计算机能够通过经验和数据自我改进的技术。在机器学习中,计算机通过对训练数据的分析和学习,可以自动地发现数据中的规律和模式,并根据这些规律和模式进行预测和决策。机器学习的目标是让计算机具有类似人类的智能能力,能够自主地学习和适应新的任务和环境。
它可以让计算机从数据中自动学习规律和模式,并根据这些规律和模式进行预测和决策。机器学习技术已经成为人工智能领域的核心技术之一,被广泛应用于图像识别、语音识别、自然语言处理、推荐系统、金融风控、医疗诊断等领域。
二. 机器学习的发展历程
机器学习的发展历程可以分为以下几个阶段:
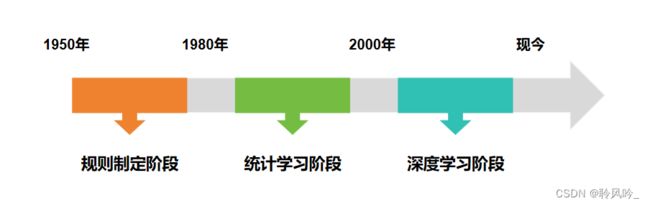
规则制定阶段(1950年代-1980年代): 在这个阶段,机器学习主要依靠人工设计和制定规则来进行预测和决策。这种方法的优点是简单可靠,但是缺点是需要大量的人工工作和专业知识。
统计学习阶段(1980年代-2000年代): 在这个阶段,机器学习开始引入统计学的概念和技术,例如线性回归、逻辑回归等。这种方法的优点是可以自动发现数据的规律和模式,但是缺点是需要大量的数据和计算资源。
深度学习阶段(2000年代-现在): 在这个阶段,机器学习开始引入深度学习的概念和技术,例如卷积神经网络(CNN)、循环神经网络(RNN)等。这种方法的优点是可以自动地从数据中学习和提取高层次的特征表示,但是缺点是需要大量的数据和计算资源,并且容易出现过拟合等问题。
三. 机器学习的原理
机器学习是一种通过训练数据来让机器自动学习和改进性能的方法。它的原理可以概括为以下几个步骤:
-
数据收集和准备:机器学习的基石是数据。系统需要大量的数据来学习和进行模型训练。这包括收集、清洗和处理数据,确保数据质量和适用性。
-
特征提取和选择:从收集的原始数据中抽取和表示有意义的特征是机器学习的关键。特征提取的目标是将原始数据转化为对算法更有用的形式,以便更好地进行模型训练和预测。
-
模型选择和训练:选择适当的机器学习模型来拟合数据。常见的机器学习模型包括线性回归、逻辑回归、决策树、支持向量机、神经网络等。然后使用训练数据对模型进行训练,通过调整模型的参数来最小化预测误差。
-
模型评估和调优:使用测试数据对训练好的模型进行评估。常用的评估指标包括准确率、精确度、召回率、F1值等。如果模型的性能不满意,可以通过调整模型的超参数或使用更复杂的模型来改进性能。
-
模型应用和预测:对新的未见过的数据进行预测。通过将输入数据输入到训练好的模型中,模型将输出相应的预测结果。
总的来说,机器学习的原理是通过训练数据来构建一个数学模型,然后利用该模型对新的未知数据进行预测或分类。通过不断的训练和调优,模型可以逐渐提高性能,并应用于实际问题中。
四. 机器学习的分类
机器学习可分为多个主要类别,每种类别都在不同应用领域展现出独特的优势。以下是机器学习主要的分类方式:
3.1 监督学习
定义:监督学习是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。监督学习主要用于回归和分类:

-
常见的监督学习的回归算法有:线性回归、回归树、K邻近、Adaboost、神经网络等。
-
常见的监督学习的分类算法有:朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
应用:常见于分类和回归问题,如图像识别、语音识别、房价预测等。
3.2 无监督学习
定义:无监督学习中,模型在没有标签的情况下从数据中学习模式和结构。目标是发现数据的内在结构或关系。无监督学习主要用于关联分析、聚类和降维。 常见的无监督学习算法有聚类算法(如k-means、DBSCAN)、主成分分析(PCA)等。
应用:常见于聚类、降维、关联规则挖掘等,如客户分群、主题模型等。
3.3 半监督学习
定义:监督学习是介于监督学习和无监督学习之间的一种学习方式。半它使用一部分带有标签的训练样本和一部分没有标签的训练样本进行学习。半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
应用:在标注数据有限的情况下,通过更充分利用未标注数据提升模型性能。
3.4 强化学习
定义: 强化学习中,模型通过与环境的交互学习,根据行为的反馈来调整策略,以最大化累积奖励。在强化学习中,智能体与环境交互,通过采取不同的动作来观察环境的反馈,然后根据反馈来更新策略。常见的强化学习算法包括Q学习、策略梯度等。
应用:应用: 适用于决策场景,如游戏策略、自动驾驶、机器人控制等。
3.5 四种分类对比
为了便于读者理解,用灰色圆点代表没有标签的数据,其他颜色的圆点代表不同的类别有标签数据。监督学习、半监督学习、无监督学习、强化学习的示意图如下所示:

五. 机器学习的应用场景
机器学习在各个领域都有广泛的应用。以下是其中一些常见的应用场景:
金融服务:机器学习可以用于信用评估、欺诈检测、风险管理和投资组合优化等金融领域的任务。
医疗保健:机器学习可以用于疾病诊断、药物发现、基因组学研究和临床决策支持等医疗保健领域的任务。
交通和物流:机器学习可以用于交通流量预测、路线优化、配送优化和异常检测等交通和物流管理任务。
社交媒体:机器学习可以用于社交媒体内容分析、用户兴趣预测、社交网络分析和广告定向等社交媒体应用中的任务。
自然语言处理:机器学习可以用于机器翻译、语音识别、情感分析、文本分类和自动问答等自然语言处理任务。
图像和视频分析:机器学习可以用于图像识别、目标检测、人脸识别、图像生成和视频内容分析等图像和视频处理任务。
这些只是机器学习应用的一小部分,随着技术的发展,机器学习将在更多领域得到应用。
六. 机器学习的未来发展趋势
机器学习的未来发展趋势包括以下几个方面:
自适应学习:自适应学习是指机器学习系统能够自动地调整自己的参数和模型,以适应不同的任务和环境。这种方法的优点是可以提高系统的鲁棒性和泛化能力,但是需要大量的数据和计算资源。
强化学习:强化学习是机器学习中的一种方法,通过与环境进行交互,通过试错来学习并改进自己的行为。强化学习在自动驾驶、智能游戏等领域有着广泛的应用前景。
多模态学习:多模态学习是指机器学习系统可以同时处理多种类型的数据,例如图像、文本、音频等。多模态学习可以更全面地理解和处理信息,提高模型的性能和效果。
联邦学习:联邦学习是指多个参与方在不共享数据的情况下进行模型训练,可以保护数据隐私,同时又能够享受联合训练的好处。联邦学习在分布式环境下具有广泛的应用前景,特别是在医疗、金融等领域。
解释性机器学习:可解释性机器学习是指机器学习系统能够提供对自身决策过程的解释和理解。这种方法的优点是可以帮助用户更好地理解和信任机器学习系统,但是需要解决模型复杂度、解释难度等问题。
全文总结
总之,机器学习技术将会在未来继续发挥重要作用,为人类社会带来更多的便利和发展机遇。同时,也需要不断地探索和完善机器学习的基本原理和技术方法,以应对日益复杂的应用场景和挑战。
今天的干货分享到这里就结束啦!如果觉得文章还可以的话,希望能给个三连支持一下,聆风吟的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是作者前进的最大动力!