双非本科准备秋招(2)——力扣基础sql与二分搜索
LeetCode高频SQL50题(基础版)
链接:高频 SQL 50 题(基础版) - 学习计划 - 力扣(LeetCode)全球极客挚爱的技术成长平台
虽然题目基础,但是发现自己好多sql知识点没掌握,现在学一道题就顺便把不会的部分都补上。
第一题、第二题:简单的左连接、内连接,没啥可复盘的。
第三题:1581. 进店却未进行过交易的顾客
我一般都先写个select * 巴拉巴拉的,看看能产生什么结果,左连接一下就发现答案了。

为null的代表没交易过,只需要根据customer_id分组,然后找出transaction_id为null的,然后count一下数量即可。
一开始写的transaction_id=null,后来才知道null不能参与运算,也不能参与聚合函数运算,要用is,is可以测试一个布尔值(true/false/null),一般情况下和 null 连用,比较该字段的值是否为空(is null / is not null)
代码如下:
select customer_id, count(*) as count_no_trans from Visits v
left join Transactions t on v.visit_id = t.visit_id
where transaction_id is null
group by customer_id;第四题:上升的温度
自己连接自己,如图,答案呼之欲出,一开始以为一定是按顺序给出的(想当然了),虽然题目没说,果然错了
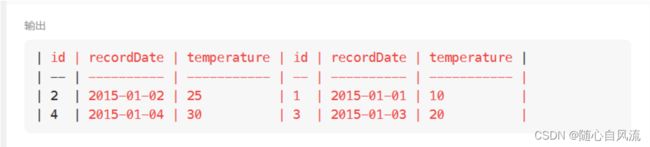
后来想到两个表连接到一起,连接条件是日期之间差一,where的条件就是找到日期大的温度高于日期小的温度,怎么对日期操作呢?搜了一下,学到了个函数:select date_add(日期, interval 1 day);
select w2.id as Id
from Weather w1
join Weather w2
on w2.recordDate = date_add(w1.recordDate, interval 1 day)
where w1.temperature < w2.temperature解释:w1和w2就是连接后表格中前半部分和后半部分的内容(连接条件如代码所示),要找的就是w2温度大于w1的
第五题、每台机器的进程平均运行时间
计算每个机器的平均运行时间,肯定根据机器分组,分组后怎么办呢?首先得求出总的时间吧,总时间是sum(end-start),可以看到end是+,start是-,所以这里可以用case语句判断一下activity_type的值,case when activity_type = 'end' then 1 else -1 end,这就得出了正负号,然后再用timestamp * (case when activity_type = 'end' then 1 else -1 end),这不就是每个进程的总时间了吗,然后用sum计算每个机器的总时间:sum(timestamp * (case when activity_type = 'end' then 1 else -1 end)),需要除以进程的数量的一半,即(count(process_id)/2),然后四舍五入的函数是round(number, cnt),cnt就是四舍五入保留几位小数。
代码如下:
select machine_id,
round(sum(timestamp * (case when activity_type = 'end' then 1 else -1 end)) / (count(process_id)/2), 3) as processing_time
from Activity
group by machine_id第六题、员工奖金
这题没啥新意,普通的连接,还是注意null不能参加运算就行。
第七题、学生们参加各科测试的次数
多表联查,有点难度。students表要与subjects表连接,然后左连接examinations表,因为所有的学生都必须出现
按照students的学生id加subjects学科名字进行分组,统计examinations里学科名字出现次数,null不会统计,所以没参加的为0。
select s.student_id, s.student_name, sb.subject_name, count(e.subject_name) attended_exams
from students s
join subjects sb
left join examinations e
on s.student_id = e.student_id
and sb.subject_name = e.subject_name
group by s.student_id, sb.subject_name
order by s.student_id, sb.subject_name第八题、至少有5名直接下属的经理
自己连接自己,连接条件是managerId和id相等。一开始按name分组错了,发现可能会有重名的经理,应该按id分组,分组后再判断是否大于5,用having。
select e2.name
from employee e1
join employee e2
on e1.managerId = e2.id
group by e2.id
having count(*) >= 5复习了一下常见的函数的用法:
字符串函数:
# concat(s1, s2) 字符串拼接
select concat('aaa', 'bbb');
# lower(s) 转小写
select lower('SSSsss');
# upper(s) 转大写
select upper('awfSSS');
# lpad(str, n, pad) 用pad左填充str,达到n个长度。同理rpad是右填充
select lpad('1293', 8, '0'); -- 常用于这种不足补0的
# trim(s) 去掉s头尾的空格
select trim(' ss ');
# substring(s, start, len) 截取从start开始,长度为len的字符
select substring('abcde', 1, 4); -- 结果abcd数值函数:
# ceil(x) 向上取整
# floor(x) 向下取整
# mod(x, y) x%y
# rand() 0-1的随机数
# round(x,y) x四舍五入,保留y位
select ceil(round(rand(), 2)); -- 结果必为1日期函数:
# curdate()当前日期
select curdate();
# curtime()当前时间
select curtime();
# now()当前日期和时间
select now();
# year(date) month(date) day(date) 获取指定date的年份,月份,日期
select year('2021-02-12'), day('2021-02-12'), month('2021-02-12');
# date_add(date, interval expr type) 日期加减运算
select date_add('2021-02-12', interval 1 year);
select date_sub('2021-02-12', interval 10 month);
# datediff(date1, date2)返回date1之间date2的天数
select datediff('2021-02-12', '2022-02-11'); -- 结果为 -364流程函数:
# if(value, t, f) 为真返回t,否则返回f
select if(2=2, '啊对对对', '不对');
# ifnull(value1, value2) value1不为空返回value1,否则返回value2
select ifnull(null, '大意了');
# case有两种写法,区别就是第一种的条件可灵活编写,第二种是固定写一个值,然后每次when都判断是否等于这个值。
# case when (vall) then (res1) ``` else (default) end
select
case when(1=2) then '啊对对对'
when(1=3) then '行行行'
else '嗯嗯嗯'
end; -- 返回嗯嗯嗯
# case (v1) when (v) then (res1) else (default) end
select
case 1 when 2 then '啊对对对'
when 3 then '行行行'
else '嗯嗯嗯'
end; -- 返回嗯嗯嗯复习了一下sql语句编写顺序和执行顺序:
直接贴上黑马的PPT了,执行的时候先from哪个表,然后where条件,再分组,再执行分组后条件having,然后才select出字段列表,再排序,最后分页。之前一直模模糊糊的,这次搞懂了。
LeetCode二分查找
跟着黑马学了学算法,讲的真好,以前只会套板子,今天对二分搜索有了比较深刻的理解。想学学算法数据结构的,强烈推荐Java数据结构与算法课程导学哔哩哔哩bilibili
刷了刷leetcode简单的二分搜索,水题704、35,考察最基础的二分搜索。34考察二分搜索的边界问题,leftmost和rightmost。
二分搜索有很多种形式:
这样的
public static int binarySearchBasic(int[] a, int target){
int i = 0, j = a.length-1;
while (i <= j){
int m = (i + j) >>> 1;
if(a[m] < target){
i = m+1;
}
else if(target < a[m]){
j = m-1;
}
else{
return m;
}
}
return -1;
}这样的
public static int binarySearchAlternative(int[] a, int target){
int i = 0, j = a.length, m = 0;
while(i < j){
m = (i + j) >>> 1;
if(target < a[m]){
j = m;
}
else if(a[m] < target){
i = m+1;
}
else{
return m;
}
}
return -1;
}还有这样的
public static int binarySearchLeftMost(int[] a, int target){
int i = 0, j = a.length-1;
while(i <= j){
int m = (i + j) >>> 1;
if(target <= a[m]){
j = m-1;
}
else if(a[m] < target){
i = m+1;
}
}
return i;
}之前学的时候就很头疼,while判断一会有等号一会没等号,返回值一会是m一会是i的,看了很多资料也不是很理解。
其实while循环里是否有等号与i和j的取值有关,i为0,j为a.length-1时,i和j都有可能成为目标值,所以如果while里不写等号就可能漏判一次i==j的情况;而当j取值为a.length的时候,j一定不会是目标值,而是作为右边界,所以不需要判断i==j,如果加上=,当i等于m,可能j一直取m,于是i=j=m,就死循环了。
那考虑重复元素的情况,就衍生出了搜索最左侧和最右侧元素的代码,下面是leftmost
public static int binarySearchLeftMost(int[] a, int target){
int i = 0, j = a.length-1;
int candidator = -1;
while(i <= j){
int m = (i + j) >>> 1;
if(target < a[m]){
j = m-1;
}
else if(a[m] < target){
i = m+1;
}
else{
candidator = m;
j = m-1;
}
}
return candidator;
}candidator为候选键,else代码里说明了target==a[m],改造一下,当target等于a[m]的时候,记录当前m的值,然后继续向左侧缩小。
我们可以发现,退出循环的时候,i一定比j大1,而j不断向左缩小边界,最后的取值一定是找到的元素的左边,所以i就代表找到的元素的下标。所以,我们可以省略candidate,然后合并if判断,得到如下代码:
public static int binarySearchLeftMost(int[] a, int target){
int i = 0, j = a.length-1;
int candidator = -1;
while(i <= j){
int m = (i + j) >>> 1;
if(target <= a[m]){
j = m-1;
}
else if(a[m] < target){
i = m+1;
}
}
return i;
}找rightmost的代码也类似:
/**
* 找最右边的,就是a[m] <= target的时候继续增加i,最后i会到了目标值的右侧,需要减1,为什么找leftmost不用减1?
* 因为退出条件是i<=j,则最终一定是i在j的右边,找左侧最大的值时,j一直找到不是为止,则i正好在j右侧,代表最左侧元素
* 而找右侧最大值时,i一直找到不是为止,j代表最右侧元素,所以返回i-1和j才代表目标下标
*/
public static int binarySearchRightMost(int[] a, int target){
int i = 0, j = a.length-1;
while(i <= j){
int m = (i + j) >>> 1;
if(target < a[m]){
j = m-1;
}
else {
i = m+1;
}
}
return i-1;
}理解了这个之后,leetcode的34题:在排序数组中查找元素的第一个和最后一个位置 就很简单了。
leetcode374:猜数字大小。这题倒也不难,就是得转转脑子。其实还是普通的二分查找,区别是,i和j不再是下标了,而是目标值的可能值,所以val就是目标值的可能值,m的取值是guess函数的返回值,代表目标值与val值谁大谁小。理清楚这个关系,这个题也不难。
public int guessNumber(int n) {
int i = 1, j = n;
// 1 10 11 m = guess(5) 5>> 1;
int m = guess(val);
if (m == 1) {
i = val + 1;
} else if (m == -1) {
j = val - 1;
} else {
return val;
}
}
return i;
}