让AI帮你说话--GPT-SoVITS教程
有时候我们在录制视频的时候,由于周边环境嘈杂或者录音设备问题需要后期配音,这样就比较麻烦。一个比较直观的想法就是能不能将写好的视频脚本直接转换成我们的声音,让AI帮我们完成配音呢?在语音合成领域已经有很多这类工作了,最近网上了解到一个效果比较好的项目GPT-SoVITS,尝试了一下,趟了一些坑,记录一下操作过程。
首先附上大佬的仓库和教程:
- GitHub链接
- 视频教程
下载代码和创建环境
电脑配置
Windows11
CUDA 12.1
显卡RTX 4070
Anaconda
下载代码
git clone https://github.com/RVC-Boss/GPT-SoVITS.git
创建环境
conda create -n gpt-sovits python=3.9
conda activate gpt-sovits
Windows
pip install -r requirements.txt
conda install ffmpeg
#下载以下两个文件到GPT-SoVITS项目根目录
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffmpeg.exe
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/ffprobe.exe
下载模型
1、在GPT_SoVITS\pretrained_models打开终端输入:
git clone https://huggingface.co/lj1995/GPT-SoVITS
如果不成功,先尝试下面语句,然后再次clone代码:
git lfs install
如果还不成功,需要确认网络是否能连外网。
下载完模型后,将模型文件拷到GPT_SoVITS\pretrained_models目录下:
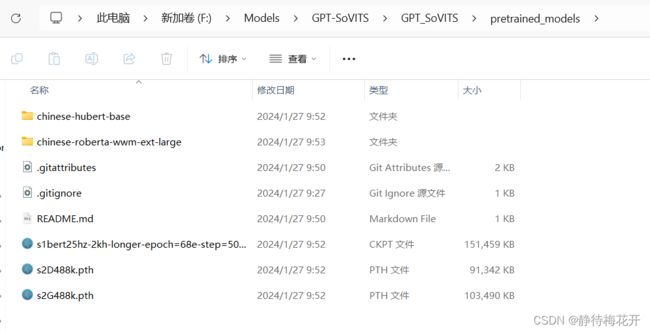
2、到modelscope下载以下模型:
git clone https://www.modelscope.cn/iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch.git
git clone https://www.modelscope.cn/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch.git
git clone https://www.modelscope.cn/iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch.git
将以上模型文件放到tools/damo_asr/models目录下:

如果训练的音频数据有杂音的话,还需要下载UVR5模型对音频先进行去噪处理,放到tools/uvr5/uvr5_weights目录下:
git clone https://huggingface.co/lj1995/VoiceConversionWebUI
运行demo
配置好环境和模型后,在终端输入:
python webui.py
如果报以下错误,说明装的Torch不是CUDA版本的,需要重装对应的CUDA版本的pytorch。
AssertionError: Torch not compiled with CUDA enabled
运行起来后界面如下:
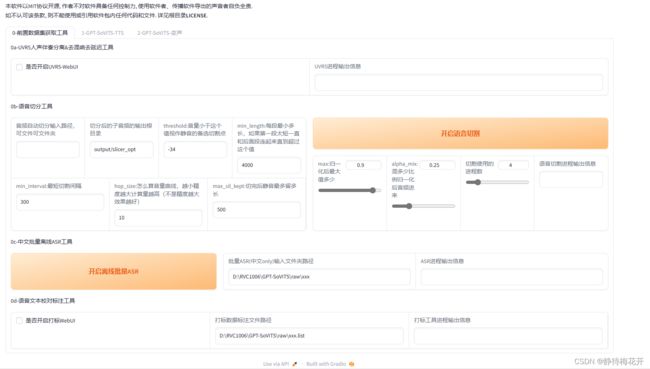
微调和推理模型
处理数据
下载的原始模型一般就可以用来推理转换声音了,但是如果想要转换的声音更真实,本地又有GPU的话,可以进一步尝试微调模型,进一步提升转换声音的真实性。
-
首先我们要收集一段我们自己的录音作为微调数据集,最好将格式保存为wav格式。
-
然后将音频进行切分和标注,这里就用webUI工具进行处理,在音频自动切分输入路径中填入我们保存得wav格式音频文件路径,其余参数根据需要调整,点击开始语音切割,切割完成后的文件保存在output/slicer_opt文件夹中。

-
切分完后需要对语音进行识别成中文文本,执行下面的中文批量离线ASR工具,填写批量ASR输入文件夹路径为上一步的子音频输出目录。

若出现以下报错:
KeyError: 'funasr-pipeline is not in the pipelines registry group auto-speech-recognition. Please make sure the correct version of ModelScope library is used.'
说明funasr版本有问题,需要修改一下tools\damo_asr\cmd-asr.py为:
path_asr='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch'
path_vad='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch'
path_punc='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch'
path_asr=path_asr if os.path.exists(path_asr)else "damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
path_vad=path_vad if os.path.exists(path_vad)else "damo/speech_fsmn_vad_zh-cn-16k-common-pytorch"
path_punc=path_punc if os.path.exists(path_punc)else "damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
# 注释掉这块代码
# inference_pipeline = pipeline(
# task=Tasks.auto_speech_recognition,
# model=path_asr,
# vad_model=path_vad,
# punc_model=path_punc,
# )
model = AutoModel(model=path_asr,
vad_model=path_vad,
punc_model=path_punc,
#spk_model="damo/speech_campplus_sv_zh-cn_16k-common",
#spk_model_revision="v2.0.0"
)
opt=[]
for name in os.listdir(dir):
try:
# 这里也注释
# text = inference_pipeline(audio_in="%s/%s"%(dir,name))["text"]
text = model.generate(input="%s/%s"%(dir,name),
batch_size_s=300,
hotword='魔搭')
print(f"asr text:{text}")
opt.append("%s/%s|%s|ZH|%s"%(dir,name,opt_name,text))
except:
print(traceback.format_exc())
...
在转换完成后,会在目录 \GPT-SoVITS\output\asr_opt下生成slicer_opt.list文件,里面就是每段音频对应的文本。
4. 得到文本后,需要对文本进行打标矫正,将**\GPT-SoVITS\output\asr_opt\slicer_opt.list**路径填到 打标数据标注文件路径中,然后勾选开启打标webUI。
![]()
然后在打标界面进行标注矫正
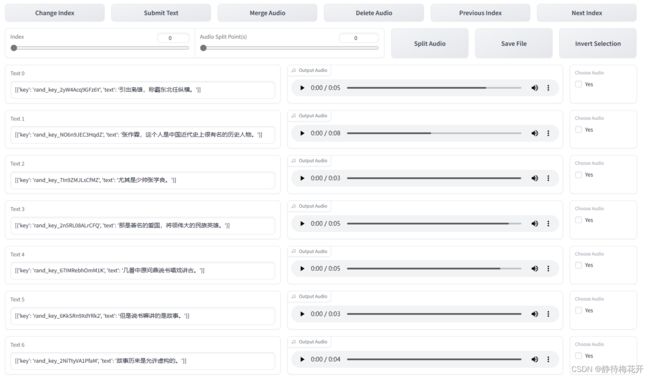
在这个界面可以进一步拆分合并音频和修改文本,修改后需要点击Submit Text保存。
5. 接下来对得到的音频文件和文本标注文件进行格式化转换,切换到1-GPT-SoVITS-TTS页面,填写相应的实验名,文本标注文件和训练集音频文件,然后点击下面的一键三连等待转换完成即可。

等到输出信息显示一键三连进程结束说明格式化数据集成功。
若中途报错 Resource cmudict not found.Please use the NLTK Downloader to obtain the resource,在命令行中尝试下面语句,下载弹出界面的东西即可
import nltk
nltk.download('cmudict')
微调模型
然后切换到1B-微调训练界面,设置相应的训练参数即可开始训练SoVITS和GPT。需要注意根据显卡显存调整batch size大小避免OOM。

训练成功后,SoVITS权重和GPT权重会分别保存到SoVITS_weights和GPT_weights文件夹下,然后我们就可以选择我们微调好的模型进行推理了。
推理模型
选择1C-推理界面,点击刷新模型路径,在GPT模型列表和SoVITS模型列表中选择我们微调好的模型,然后勾选下面的 开启TTS推理WebUI,等待推理页面打开。

打开后选择上传参考音频,这里我们可以选择我们之前分割的音频和其对应的标注文本。然后在输入要合成的文本,选择相应的合成语种,点击合成语音,几秒后即可合成对应的语音。若输入的文本过长,需要使用下方的切分工具先对文本进行切分。

合成完成后,点击输出的语音即可试听和下载生成的语音。如果生成的效果不满意,可以重复多试几次。如果生成的效果实在不行,需要重新收集质量更好的自己的录音进行重新微调。
得到满意的模型之后,以后就可以将准备好的文字脚本直接转换成自己的声音,不用再专门录音去噪了,懒人福音~
最后,本文章仅为学习目的使用,请不要将方法应用于任何可能的非法用途。
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
注:本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.