短视频界的变革者:上海 AI lab 发布 Vlogger,几句话生成分钟级视频
现如今,vlog 已经成为我们日常生活的重要组成部分。无论是看视频学习休闲、记录珍贵瞬间还是分享生活见闻,视频已经成为人们表达创意和观点的独特媒介。
然而,与几秒钟的短视频不同,要创作出引人入胜、生动有趣的长视频,通常需要构思复杂的故事情节和多样化的场景,这一般要专业的摄影团队和繁琐的后期制作。
近期,上海 AI lab 团队发布 Vlogger,用几句话就能生成分钟级视频。
“开局一段话,视频全靠编”,无需专业的摄影团队,由 LLM 当导演,给它一个引入入胜的故事,或许成为专业 vlog 博主指日可待。

论文题目:
Vlogger: Make Your Dream A Vlog
论文链接:
https://arxiv.org/abs/2401.09414
Github 地址:
https://github.com/zhuangshaobin/Vlogger
博客地址:
https://zhuangshaobin.github.io/Vlogger.github.io/
由 LLM 担任导演,作者通过 Vlogger 的剧本创建、演员设计、ShowMaker 拍摄和 Voicer 配音这四个步骤生成高质量的 vlog,而且 Vlogger 克服了以前在长视频生成任务中遇到的挑战:
-
将用户故事巧妙地分解为许多拍摄场景,并设计了能够在 vlog 中不同场景中出现的演员图像。通过对场景文本和演员图像的明确指令,Vlogger 能够降低由于突然的拍摄变化而引起的时空不一致性。
-
为每个场景生成独立的视频片段,并将它们无缝整合成一个连贯的 vlog。由此避免了使用大规模的长视频数据集进行繁琐的训练。
Vlogger 是什么?
如图 1 所示,Vlogger 让 LLM 担任导演,先在规划阶段创建剧本(Script)并设计演员(Actor),基于此,ShowMaker 在拍摄阶段为每个场景生成视频片段,而 Voicer 为此片段配音。

▲图1 Vlogger 框架
通过规划和拍摄阶段内的四个重要角色,这一过程可以分解为自上而下的规划和自上而下的拍摄两部分:
自上而下的规划
vlog 包含了丰富的镜头切换和多样化的内容,直接将复杂的用户故事输入到视频生成模型中,生成分钟级的 vlog 是具有挑战性的,因此,通过图 2 中自上而下的规划分解用户故事。

▲图2 自上而下的规划
1 剧本创建
逐步将用户故事转换为剧本,这是生成 vlog 的第一步。与 LLM 导演进行由粗到细的对话,解析用户故事,这个渐进的剧本创建范式(paradigm)大致可以分为四个阶段:
-
粗略阶段(Rough):首先,LLM 导演首先从用户提供的故事中生成了基本的剧本草稿。
-
细节阶段(Detailed):随后,LLM 导演通过添加故事细节逐渐完善初步生成的剧本。
-
完成阶段(Completed):接下来,LLM 导演检查详细剧本,确保没有遗漏故事的重要部分。
-
安排阶段(Scheduled):最后,LLM 导演为剧本中的每个场景分配了拍摄时长和场景内容。得到的最终剧本包含了 个拍摄场景的描述 , 以及它们各自分配的时长 ,。
这个剧本创建过程通过逐步细化的对话,将用户故事逐渐转化为最终剧本。由于 LLM 在语言理解方面展现出强大的能力,能够有效地处理复杂的用户故事,为后续的 vlog 生成提供了清晰的指导。LLM 导演能够有效地将用户故事拆解为多个拍摄场景,并为每个场景分配相应的拍摄时长,从而充分描述整个故事,确保生成的剧本在视觉和情节上保持协调性。
2 演员设计
在剧本创建完成后,是时候在 vlog 中安排演员了。LLM 导演将会再次审查剧本,汇总演员列表。然后,通过调用角色设计师(例如 SD-XL),作者生成了这些演员在 vlog 中的参考图像,使演员在各个场景中能够贴合剧本,为后续拍摄做好准备。
-
演员总结(Actor Summarization): 首先,从生成的剧本中,通过与 LLM 导演的对话,提取出演员的相关信息,形成演员总结。
-
演员图像生成(Actor Image Generation): 接下来,基于上述信息,LLM 导演调用一个 LLM 设计师生成演员的参考图像。
-
主角选择(Protagonist Selection): 最后,LLM 导演根据演员的总结和剧本,决定了在剧本每个拍摄场景中的主角。这个过程通过特定的指令来实现,确保所选的主角与剧本中的场景相匹配。
自下而上的拍摄
如图 3 所示,这是通过 ShowMaker 进行底层拍摄(Bottom-Up Shooting)的过程。通过 ShowMaker 模型进行实际的视频生成,并用 Voicer 对其配音。

▲图3 自下而上的拍摄
3 ShowMaker 拍摄
在剧本文本和演员图像的指导下,作者提出了一种新颖的 ShowMaker 模型作为摄影师,如图 4 所示。ShowMaker 是专为生成每个拍摄场景的视频片段而设计的视频扩散模型,用于生成每个拍摄场景的视频片段。它能够为每个拍摄场景生成规定时长的视频片段,同时保持剧本和演员之间的时空一致性,以确保整体的视频流畅和自然。

▲图4 ShowMaker(a)总体架构(b)时空增强块(STEB)(c)模式选择
-
从结构上看:在该模型中引入了时空增强块(STEB)。该块可以自适应地利用场景描述和演员图像作为文本和视觉提示,通过时空-演员和时空-文本的交叉注意力,这些提示仔细指导 ShowMaker 增强剧本和演员的时空一致性。
-
从训练的角度来看:提出一种概率模式选择机制,通过混合训练 Text-toVideo(T2V)生成和预测来增强 ShowMaker 的能力。
在生成视频片段之前,模型将场景描述(Scene Description)作为文本提示,以及每个场景的演员图像(Actor Image)作为视觉提示。
ShowMaker 在生成视频片段的过程中采用两种学习模式,在推理阶段利用了生成模式和预测模式的组合:
-
生成模式用于开始生成一个视频片段。
-
预测模式中,使用之前生成的帧作为上下文,预测下一帧,以此类推,直到满足剧本中指定的场景时长。
4 Voicer 配音
最终,为了增强 vlog 的完整性,在 LLM 导演的指导下,调用 Text-To-Speech 模型作为 Voicer,为 vlog 进行配音,将场景描述转换为相应的音频,并将其与视频片段相结合。
实验结果
作者在当前流行的视频基准数据集 UCF-101 上进行 zero-shot 评估。表 1 显示 Vlogger 表现出色,不论输入文本是类别标签还是人工提示,Vlogger 都取得了最佳的 FVD 性能。

▲表1 在 UCF-101 数据集上的零样本比较
通过与其他先进的 T2V 生成模型进行比较,Vlogger 展示了其在视频生成任务上的优越性。
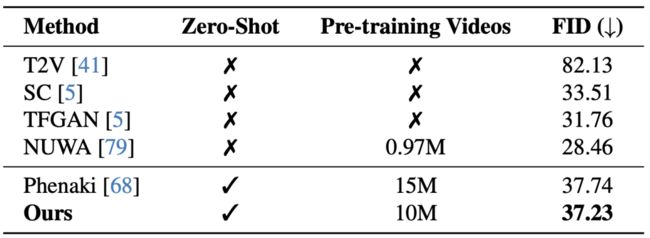
▲表2 在 Kinetics-400 上的比较

▲表3 在 MSR-VTT 上的比较
在 UCF-101 上,不需要对进行任何微调,Vlogger 实现了 zero-shot 长视频生成。与领域唯一的开源长视频生成模型 TATS 相比,Vlogger 在生成 1000 帧视频时性能显著更好,并且没有 TATS 存在的随着帧数增加而视频质量下降的问题。
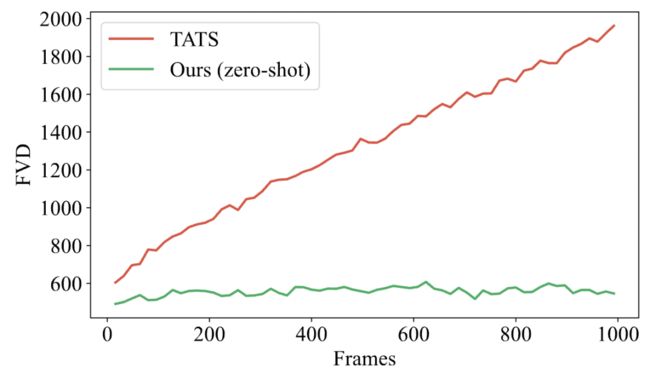
▲图5 长视频生成
三种 vlog 生成流程的比较
作者比较了三种不同的生成流程,分别是没有自回归(MovieFactory)、完全自回归一次生成(Phenaki)和 Vlogger 生成流程。通过相同的剧本和 ShowMaker 作为摄影师。结果显示,即便在相同的输入条件下,Vlogger 在生成 vlog 的质量上超过了其他框架,表现更为优越。
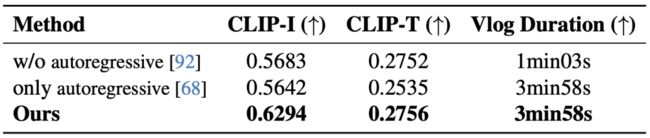
▲表4 生成过程消融研究
在 ShowMaker 引入时空增强块是否有效?
时空增强块(STEB)是 Vlogger 中的一个关键组成部分,包括空间图像交叉注意力和时间文本交叉注意力。在实验中,通过改变参数 进行了空间图像交叉注意力的消融研究。结果显示,CLIP-I 在 增加时显著改善,在 时达到最大值。
另外,通过引入时间文本交叉注意力(TTCA),在 Vimeo11k 数据集上的 T2V 生成和预测性能都显著提高。

▲图6 空间图像交叉注意力的消融
混合训练范式是否有用?
与之前的随机掩码训练方法进行比较,结果表明,混合训练范式在提高模型的 T2V 生成和预测都有效。

▲表5 时域文本交叉注意力和混合训练范式的消融
总结
Vlogger 为长视频生成带来了新的可能性,通过创新性的四个步骤和先进的 ShowMaker 模型,成功地克服了以往在这一领域所面临的挑战。实验证明,Vlogger 在多个方面都表现出色,展现了其在zero-shot 视频生成任务上的优越性能。
这个系统不仅仅是一个视频生成工具,更是一个富有创意的导演,从用户提供的故事中提取元素,将其转化为连贯而有创意的视觉叙事。相信 Vlogger 的成功能为开放领域中的长视频生成提供新的思路和工具,为未来的研究和设计奠定坚实的基础。

