openai gpt的新的开源项目,支持gpt聊天,识图(gpt4v),文字转语音(tts)和stt(语音转文字),并且易于扩展,使用angular和python
项目地址: GitHub - Basicconstruction/turboUI: 使用angular编写的流式gpt代码,可以使用gpt-4-vision,tts,whisper模型
百度网盘链接
链接:https://pan.baidu.com/s/17D2Q5H43JVboxr8yDIzlgQ?pwd=7mah
提取码:7mah
Turbo
为什么用turbo命名?
因为项目确实需要一个名字,常规的名字是gpt,chat什么的,往往和gpt,gpt的聊天有关,我确实也不太好想到一个合适的名字,turbo可以说是取自gpt-3.5-turbo中的turbo,而且之前国内的一些大模型也总是加个turbo。所以干脆就用这个名字了。
下面对该项目的使用和设计进行简单的介绍。
设计目的
openai的gpt-3.5 可以满足我的大部分需求,我也作为一个gpt的老玩家,国内gpt开源项目的生态发展了10个月,依旧很少有开源项目支持 绘画,tts和语音转文字。而我之前使用c# wpf开发过一个聊天的程序,优点是 编译的可执行文件较小,但是效果较差,ui较差,且不易于扩展,逻辑复杂且耦合度太高。我是在我的本来准备的毕业设计遇到了瓶颈才继续开始学习angular的,不过我有css,html,以及flutter的基础,而ts的语法和flutter几乎一样,所以学习angular也是很快,从学习入门教程到学完一本600多页的书,也只用了两周,但是学习完和会用是一个很大的 门槛。所以我打算开发一个项目来加深对angular的理解和使用。所以就打算开始这个项目。
设计资料
设计的时候,首要的设计目的也就是面向人群是 使用电脑的用户,并且尽量避免让客户安装nodejs,python等环境,安装环境对于开发者来说比较简单,但是对于用户来说就不那么简单了。现在的设计的软件,客户只需要打开软件,并且使用ui界面中的按钮,就可以打开前端服务器和后端服务器,然后ui中也引导用户打开浏览器在浏览器中使用。
api请求逻辑
本来设计的时候是使用nodejs的openai的包,这样就不需要额外套一层服务软件了,但是调用的时候会出现对象为空的情况。参考其他项目,我估计是nodejs的openai包只能在后端js服务中使用,而angular如果不配置是客户端代码,也就是逻辑全在客户端执行。于是,我就使用python架构了一个代理层。
目前主要架构是
本地客户端 openai/转发 服务器
web (turboUI) turbo-proxy
apiservice <---- api handler <------ openai-proxy
------> -------->
前端(turboUI)比如想要进行dall绘画,首先构建请求包,发送到本地(或者远程)服务器软件(turbo-proxy) ,然后turbo-proxy 解析前面的请求包,然后构建 openai api标准的请求包,接收到openai标准的响应包之后,按照设定的逻辑返回给turboUI显示。
这种设计也有好处,就是可以处理文件,可以更好地扩展新的功能,甚至还可以添加多个代理层,比如添加一个 c#的代理,如果c#能处理就利用openai的api响应前端,否则继续向后转发,收到响应直接返回给前端。
这样就可以利用各种包,比如julia的计算包,python的绘图包,等等。
查看代理软件的逻辑和代码
结合前端,你也可以设计或者直接使用该代理软件,以及添加新的处理能力
https://github.com/Basicconstruction/turbo-proxy
效果图
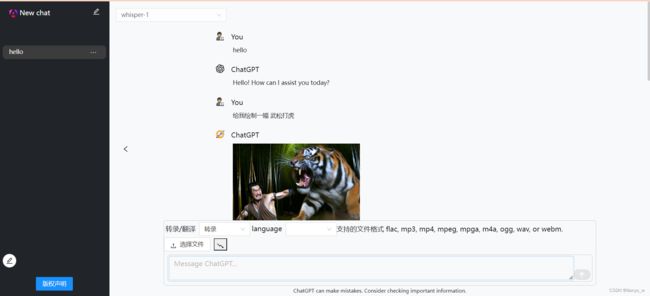
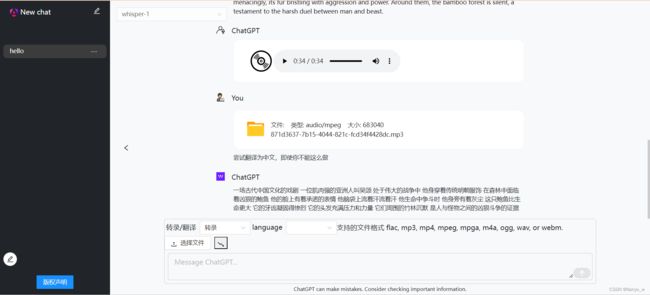
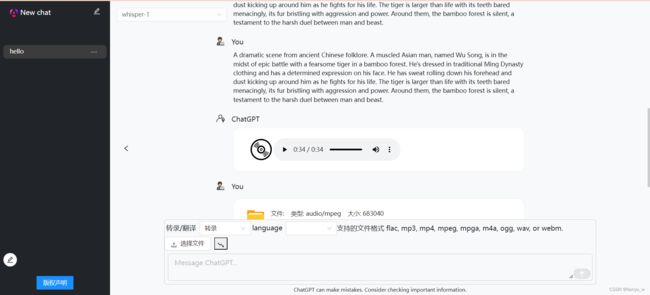
如何使用
到开源代码地址
GitHub - Basicconstruction/turboUI: 使用angular编写的流式gpt代码,可以使用gpt-4-vision,tts,whisper模型
下载
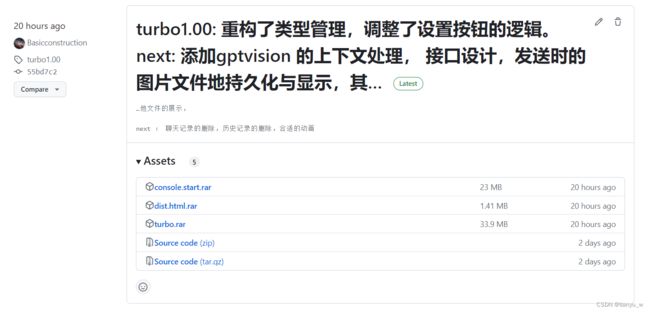
到releases中下载最新版的编译包
https://github.com/Basicconstruction/turboUI/releases
比如图中的turbo.rar 包,就是包含所以编译文件的文件。
解压
turbo 启动!
双加turbo打开
主界面如此
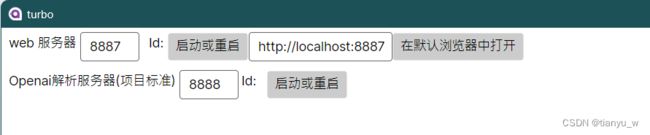
然后分别启动两个服务器软件,会打开两个命令行窗口。
如果启动成功,id后面会出现响应的进程id,就可以在浏览器中打开。
打开就像下面一样,不过你的可能没有聊天信息

设置
然后点击左下角的设置按钮,可以添加自己的openai api的地址 / 转发地址 和字节的apikey
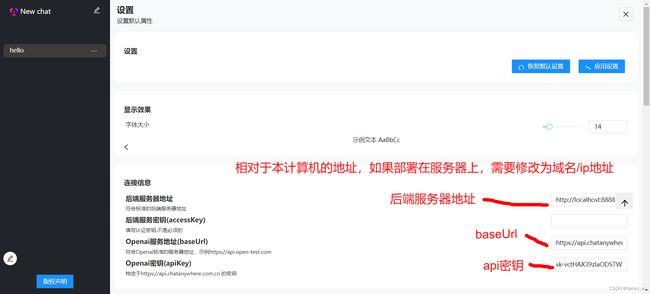
同时还可以对基本的聊天,绘图,tts,stt等进行设置。注意: 设置后应用设置。
如果有的项没有值,也不用添加值,这些是可选值,将不会发送到后端服务器。
点击设置偶尔也会出现没有跳转设置页,只需要刷新一下页面,再次点击即可。
畅享
切换模型在 /chat 正面的上方,向下方滑动就可以切换其他模型,该模型设置为 较新的模型,因为有的模型会被逐渐替代和舍弃。添加很多模型作用也不是很大。


使用tts模型时可以发送文件,后端会自动把文件的内容读取附加到输入文本中。
使用stt模型时,文件限制为25mb,后端没有额外处理,是官方的限制。
上下文,gpt-3.5,gpt-4,gpt-4-vision的上下文是共享的,tts-1,dall-e,whisper不会使用上下文。
gpt-3.5 ,gpt-4使用gpt-4-vision的上下文时,不会添加gpt-4-vision发送的图片。
关闭
关闭,两个命令行窗口和turbo即可。
服务端部署
前端
其中 dist.html.rar 包含所有前端代码,直接托管到nginx,iis上即可。
不过你需要配置深链接,参考
https://angular.cn/guide/deployment

后端
后端部署,只需要一个python环境,安装相关依赖,使用入口main.py即可。
也可以使用, console.start.rar 进行前端和后端的部署(windows server),不过他们只会监听127.0.0.1,你需要配置 反向代理使得可以被任何计算机访问。
注意,源代码使用一个文件路径作为临时文件路径,如果使用的是linux或者macos,可能会出现问题,


中使用的是一个我电脑上的地址,如果是windows计算机或者服务器,该地址将被创建,而不会出现问题。
你要保证后端地址始终可用,因为angular会完全在客户机上执行。