深入到 TLP:PCI Express 设备如何通信(第一部分)
前言
当我为PCI express编写Xillybus IP核时,我很快发现很难开始:在线资源和官方规格用关于螺母和螺栓的血腥细节轰炸你,但对机器应该做什么却很少说。因此,一旦我努力自己弄清楚这一点,我就决定写这个小指南,希望能帮助其他人获得一个更温和的开始。这基于官方的 PCI Express 规范 1.1,但非常适用于更高版本。不过,阅读原始规范是无可替代的。游戏的名称,如果获得正确的细节,以便设备在手头没有测试的环境中正常工作。
不要因为我没有描述全貌或使用不准确的定义而挑剔我。准确是规范的目的。我在这里要做的就是让它更人性化。我还发布了一个会话的 TLP 嗅探转储示例,这可能有助于了解该机制的工作原理。
PCI Express 不是总线
关于PCI express(以下简称PCIe),首先要意识到它不是PCI-X或任何其他PCI版本。以前的PCI版本(包括PCI-X)是真正的总线:有并行的铜轨物理到达外围卡的多个插槽。PCIe更像是一个网络,每个卡都通过一组专用的电线连接到网络交换机。与本地以太网网络完全一样,每个卡都有自己的与交换机结构的物理连接。相似之处更进一步:通信采用通过这些专用线路传输的数据包的形式,具有流量控制、错误检测和重传功能。没有 MAC 地址,但我们有卡的物理(“地理”)位置来定义它,然后再分配高级寻址方法(I/O 和地址空间中的块)。
事实上,最小的(1x)PCIe连接仅由四根用于数据传输的电线(每个方向两根差分对)和另一对电线组成,用于为卡提供参考时钟。就是这样。
另一方面,PCIe标准被故意设计为与经典PCI非常相似。尽管它是一个基于数据包的网络,但它都是关于地址、读取、写入中断的。
仍然完成了即插即用配置,并且像以前一样,在读取和写入地址和 I/O 空间方面访问卡。仍然有供应商/产品 ID,以及一些模仿旧行为的机制。长话短说,PCIe标准对于一个不了解PCIe的操作系统来说,看起来像是老式的PCI。
因此,PCIe是伪造传统PCI总线的分组网络。它的整个设计使得在不对软件进行任何更改的情况下将PCI设备迁移到PCIe和/或在PCI和PCIe之间透明地桥接而不会丢失任何功能。
简单的总线事务
为了了解整个事情,让我们看看当 PC 的 CPU 想要将 32 位字写入 PCIe 外围设备时会发生什么。为了简单起见,在下面的描述中故意省略了一些细节和可能性。
由于它是一台 PC,因此 CPU 本身很可能在自己的总线上执行简单的写入操作,并且连接到 CPU 总线的内存控制器芯片组直接连接到 PCIe 总线。因此,芯片组(在PCIe术语中充当根复合体)会生成一个内存写入数据包,用于通过总线传输。此数据包由一个标头组成,该标头的长度为 3 或 4 个 32 位字(取决于使用的是 32 位还是 64 位寻址)和一个包含要写入的字的 32 位字。这个数据包只是说“将此数据写入此地址”。
然后,该数据包在芯片组的PCIe端口上传输(如果有多个端口,则为其中一个端口)。目标外设可以直接连接到芯片组,或者它们之间可能存在交换网络。以这种方式或另一种方式,数据包被路由到外围设备,解码,并通过执行所需的写入操作来执行。
细究
这种简单化的观点忽略了几个细节。例如,底层通信机制,它由三层组成:事务层、数据链路层和物理层。上面对数据包的描述被定义为事务层数据包 (TLP),它与 PCIe 的最上层有关。
数据链路层负责确保每个 TLP 正确到达其目的地。它使用自己的标头和链路 CRC 包装 TLP,从而确保 TLP 的完整性。确认-重传机制可确保在传输过程中不会丢失任何 TLP。流量控制机制确保仅在链路伙伴准备好接收数据包时才发送数据包。总而言之,每当TLP移交给数据链路层进行传输时,即使到达时间略有不确定性,我们也可以依靠它的到来。未能提供 TLP 是总线的主要故障。
在讨论积分和数据包重新排序时,我们将回到数据链路层。但为此,只要意识到经典的总线操作被通过PCIe结构传输的TLP所取代就足够了。
我还想提一下,内存写入 TLP 的数据有效载荷可能比单个 32 位字长得多,从而形成 PCIe 写入突发。TLP 的大小限制是在外设的配置阶段设置的,但典型数字为每个 TLP 的最大 128、256 或 512 字节。
在继续之前,值得注意的是,内存写入 TLP 的发送方不会收到数据包已到达其最终目的地的指示,更不用说它已经执行了。即使数据链路层得到肯定的确认,这仅意味着数据包安全地到达了附近的交换机。从未进行过端到端的确认,也没有必要。
示例写入数据包
我们以上面提到的数据写入案例为例,看看TLP的细节。假设 CPU 使用 0 位寻址将值 12345678x0 写入物理地址040xfdaff32。然后,数据包可以由四个 32 位字(4 个 DW,双字)组成,如下所示:

内存写入请求 TLP 示例
因此,数据包以 0x40000001、0x0000000f、0xfdaff040 0x12345678 的形式传输。
我们来解释一下颜色编码:
- 灰色字段是保留的,这意味着发送方必须在那里放置零(接收方忽略它们)。一些灰色字段标记为“R”,这意味着该字段始终是保留的,而一些灰色字段具有名称,这意味着由于此特定数据包的性质,该字段被保留。
- 绿色字段允许具有非零值,但端点外围设备很少使用它们(据我所知)。
- 特定数据包的值标记为红色。
现在让我们简要说明有效字段:
- Fmt 字段和 Type 字段表示这是一个内存写入请求。
- TD 位为零,表示 TLP 数据(TLP 摘要)上没有额外的 CRC。如果我们相信我们的硬件不会损坏 TLP,那么这个额外的 CRC 是没有道理的,因为链路层有自己的 CRC 来确保在途中不会出错。
- Length 字段的值为 0x001,表示此 TLP 具有一个 DW(32 位字)数据。
- 请求者 ID 字段表示此数据包的发送方通过 ID 0 来识别 — 它是根复合体(最靠近 CPU 的 PCIe 端口)。虽然是必需的,但此字段在写入请求中没有实际用途,除了报告回溯错误。
- 在本例中,Tag 是一个未使用的字段。发送方可以在此处放置任何内容,所有其他组件都应忽略它。我们稍后会仔细研究它。
- 第一个 BE 字段(第一个双字字节启用)允许选择第一个数据 DW 中的四个字节中的哪个是有效的,并且应该写入。在我们的例子中设置为 1xf,它标志着所有四个字节都被写入。
- 当 Length 为 unity 时,Last BE 字段必须为零,因为第一个 DW 和最后一个 DW 是同一个。
- Address 字段只是第一个数据 DW 写入的地址。好吧,这个地址的第 31-2 位。请注意,TLP 中 DW 2 的两个 LSB 为零,因此 DW 2 实际上读取写入地址本身。将0x3f6bfc10乘以四,得到0xfdaff040。
- 最后,我们有一个DW的数据。现在是提到 PCIe 运行大端序的好时机,而英特尔处理器认为端序很小。因此,如果这是一台普通的 PC 计算机,它正在在其软件表示中编写0x78563412。
读取请求
现在让我们看看当 CPU 想要从外围设备读取数据时会发生什么。读取操作有点棘手,因为不可避免地会涉及两个数据包:一个从 CPU 到外设的 TLP,要求后者执行读取操作,另一个 TLP 返回数据。在PCIe术语中,我们有一个请求者(在我们的例子中为CPU)和一个完成者(外围设备)。
我们假设 CPU 需要来自地址 32xfdaff0 的单个 DW(040 位字)(与之前相同)。和以前一样,它可能会在与其内存控制器共享的总线上启动读取操作,该总线包含根复合体,而根复合体又会生成要通过 PCIe 总线发送的 TLP。这是一个读取请求 TLP,可能如下所示:

内存读取请求 TLP 示例
因此,此数据包由 3 个 DW 组成,0x00000001、0x00000c0f 0xfdaff040。它告诉外设在地址 0xfdaff040 处读取一个完整的 DW,并将结果返回给 ID 为 0x0000 的总线实体。
它与上面所示的 Write Request 示例惊人地相似,因此我将重点介绍其中的差异:
- Fmt/Type 字段已更改(实际上,仅更改了 Fmt)以指示这是读取请求。
- 和以前一样,“请求者 ID”字段表示此数据包的发送方的 ID 为零。它与之前的字段相同,但在读取请求中,它在功能上至关重要,因为它告诉完成者将其响应发送到何处。我们将在下面看到有关此 ID 的更多信息。
- 标签在读取请求中很重要。重要的是要意识到,它本身没有任何意义,但它具有跟踪号的功能:当完成者响应时,它必须将此值复制到完成 TLP。这允许请求者将完成答案与其请求相匹配。毕竟,允许来自总线上单个设备的多个请求。此 Tag 是 Requester 根据自身需求设置的,标准不要求某种枚举方法,只要所有未完成请求的 Tags 都是唯一的即可。尽管分配了 8 位,但只允许使用 5 个 LSB,其余的 LSB 默认必须为零。这允许一对总线实体之间最多有 32 个未完成的请求。对于需要它的应用程序,标准扩展可能允许多达 2048 个。
“长度”字段指示应读取一个 DW,“地址”字段指示从哪个地址读取。这两个 BE 字段保留与写入请求相同的含义和规则,只是它们选择要读取的字节,而不是要写入的字节。
完成
当外围设备收到读取请求 TLP 时,它必须使用某种完成 TLP 进行响应,即使它无法完成请求的操作。我们将看一个成功的案例:外设从其内部资源中读取数据块,现在需要将结果返回给请求者(在本例中为 CPU)。
数据包可能如下所示:
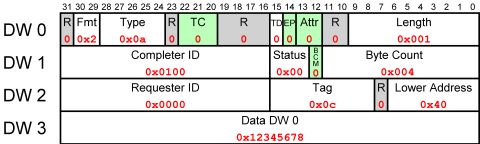
完成 TLP 示例
因此,TLP 由 0x4a000001、0x01000004、0x00000c00 0x12345678组成。数据包基本上是说“告诉总线实体0x0000,其对实体0x0100的请求(标记为0x0c)的答案是0x12345678。CPU(或者实际上,内存控制器 = Root Complex)现在可以在其内部记录中查找该请求的内容,并完成相关的总线周期。让我们把它切成碎片:
- Fmt 字段和 Type 字段表示这是一个包含数据的 Completion 数据包。
- Length 字段的值为 0x001,表示此 TLP 具有一个 DW(32 位字)数据。但是等等。难道请求者不应该知道吗?答案是 TLP 的长度是有限制的,它可能小于所需的 DW 数量。发生这种情况时,将发回多个完成 TLP。因此,“长度”字段表示此特定数据包中有多少个 DW。但那是另一回事了。
- 如果我们使用它,我们有字节计数字段。在单个 TLP 完成的情况下,它只是数据包中有效负载字节数。由于请求中的第一个 DW BE 字段都是 1,因此我们有四个有效字节,如字段中所述。仅供一般知识使用,此字段的真正定义是剩余用于传输的字节数,包括当前数据包中的字节数。这在多个 TLP 完成中很有用,如下图所示。
- 然后我们有较低的地址字段。它是地址的 7 个最低有效位,从中读取此 TLP 中的第一个字节。在我们的例子中,它0x40,来自0xfdaff040的较低部分。此字段可用于多个 TLP 完成。
- 完成者 ID 标识此数据包的发送方,即0x0100。我将在下面剖析这个 ID。
- 请求者 ID 标识此数据包的接收方,即零 ID(根复合体)。如果有一些 PCIe 交换机要路由,则将其用作目标地址。
- “状态”字段为零,表示“完成”成功。可以猜到,其他值表示不同类型的拒绝。
- BCM 字段始终为零,除非数据包来自具有 PCI-X 的网桥。所以它是零。
- 最后,我们有一个DW的数据。
顺便说一句,Completer 可能会返回切片成多个数据包的数据。然后,可以通过检查
Length == ((LowerAddress & 3) + ByteCount + 3) >> 2
如果我们碰巧在请求中将自己限制在 DW 粒度上,这只会变成
Length == ByteCount >> 2
这两个例子就这么多。现在更笼统地说。
报告和非报告传输(posted and no-posted)
如果我们将总线写入操作的生命周期与读取操作的生命周期进行比较,就会发现一个明显的区别:写入 TLP 操作是即发即弃的。一旦数据包形成并移交给数据链路层,就无需再担心它了。另一方面,读取操作要求请求者等待完成。在完成数据包到达之前,请求者必须保留有关请求是什么的信息,有时甚至保留 CPU 的总线:如果 CPU 的总线开始读取周期,则必须将其保持在等待状态,直到总线数据线上所需的读取操作的值可用。这可能是总线的可怕减速,这在最近的系统中是理所当然的。
即发即弃操作的术语,例如“内存写入即报告”操作。此类操作仅包含一个请求。当然,由“请求”和“完成”组成的操作称为“非报告”操作。
32 位与 64 位寻址
如上所述,读取和写入请求中给出的地址可以是 32 位或 64 位宽,使标头的长度为 3 或 4 DW。但是,PCIe 规范中的第 2.2.4.1 节指出,仅在必要时才必须使用 4 DW 标头格式:
对于小于 4 GB 的地址,请求者必须使用 32 位格式。如果接收到寻址低于 64 GB 的 4 位格式请求(即,地址的上限为 32 位均为 0),则不会指定接收器的行为。
实际上,任何外设的寄存器都很少映射在 4 GB 范围内,但 DMA 缓冲区很可能超出 4 GB 边界。因此,在设计新器件时,应支持具有 64 位寻址的读写 TLP。
I/O 请求
PCIe 总线仅出于向后兼容性而支持 I/O 操作,强烈建议不要在新设计中使用 I/O TLP。原因之一是 I/O 空间中的读取和写入请求都是未发布的,因此请求者也被迫等待写入操作的完成。另一个问题是 I/O 操作仅采用 32 位地址,而 PCIe 规范通常支持 64 位。
识别和路由
由于PCIe本质上是一个分组网络,因此交换机可能会在路上,因此这些交换机需要知道将每个TLP发送到何处。有三种路由方法:按地址、按 ID 和隐式。按地址路由应用于内存和 I/O 请求(读取和写入)。隐式路由仅用于某些消息 TLP,例如来自根复合体的广播和始终转到根复合体的消息。所有其他 TLP 均按 ID 路由。
ID 是一个 16 位字,由众所周知的三元组组成:总线号、设备号和功能号。它们的含义与传统PCI总线中的含义完全相同。ID 的格式如下:

PCIe ID的形成
如果你运行的是 Linux,我建议你尝试 lspci 实用程序及其众多标志,以结识总线结构。
总线主控 (DMA)
在PCIe之前,这个问题曾经有点令人毛骨悚然。毕竟,告诉 CPU 离开总线有一些侵入性,现在我正在主持节目。
在PCIe上,它的异国情调要小得多。它归结为一个简单的概念,即总线上的任何人都可以在总线上发送读写 TLP,就像根复合体一样。这允许外设直接访问 CPU 的内存 (DMA) 或与对等外设交换 TLP(在交换实体支持的情况下)。
与任何PCI设备一样,首先需要做两件事:需要通过在其中一个标准配置寄存器中设置“Bus Master Enable”位来授予外设总线主控权。第二件事是,驱动程序软件需要通知外设相关缓冲区的物理地址,最有可能是通过写入BAR映射寄存器来实现的。
中断
PCIe 支持两种中断:传统 INTx 和 MSI。
支持 INTx 中断是为了与传统软件兼容,也是为了允许在经典 PCI 总线和 PCIe 之间桥接。由于 INTx 中断是电平触发的(即,只要物理 INTx 线路处于低电压状态,中断请求就处于活动状态),因此有一个 TLP 数据包表示该线路已被置位,另一个数据包表示该线路已被解除置位。这不仅本身很奇怪,而且 INTx 中断仍然存在一些老问题,例如中断共享以及每个中断处理例程都需要检查中断的真正对象。
正是由于这些问题,在(传统)PCI 2.2 中引入了一种新的中断形式 MSI。我们的想法是,既然几乎所有的PCI外设都具有总线主控功能,为什么不让外设通过写入某个地址来发出中断信号呢?
PCIe对生成MSI的作用完全相同:发出中断信号仅包括通过总线发送TLP,该TLP只是一个已发布的写入请求,具有一个特殊地址,主机在初始化期间已将其写入外设的配置空间。任何现代操作系统(当然包括 Linux)都可以调用正确的中断例程,而无需猜测谁生成了中断。如果外设不需要确认,则实际上也没有必要“清除”中断。