在 Amazon EKS 上部署生成式 AI 模型

导言
生成式 AI 正在改变企业的运作方式,并加快创新的步伐。总体而言,人工智能正在改变企业利用技术的方式。生成式 AI 技术包括微调和部署大型语言模型(LLM),并允许开发人员访问这些模型以执行提示和对话。负责在 Kubernetes 上制定标准的平台团队可以在 Amazon EKS 上微调和部署大语言模型。
本文将通过一个端到端的例子带您了解如何在 Amazon EKS 上构建生成式 AI 系统。Amazon EKS 是一项托管的 Kubernetes 服务,可以在亚马逊云科技上轻松实现部署、管理和扩展容器化的应用程序。
Amazon EKS 的核心优势之一是其可扩展性,数据节点的动态扩展很好满足了大语言模型对于计算资源的灵活要求。例如,Amazon EKS 集群可以扩展到支持数万个容器,这使其成为密集型人工智能工作负载的理想选择。除了可扩展性,Amazon EKS 还提供高度定制化功能,允许用户根据具体需求对配置进行调整。Amazon EKS 具有强大的内置的保障措施,可保护您的人工智能模型和数据。
生成式 AI 模型是人工智能/机器学习领域的一个重大突破,因为它具有广泛的适用性,而且非人工智能专家也能轻松使用。传统上,利用人工智能意味着为每种特定的用例创建专门的模型,每次都需要大量的计算资源和人力资源。生成式 AI 通过创建基础模型克服了这一瓶颈。对基础模型进行微调,使其适用于多种用例,从而实现重复使用,而无需重复从头开始构建模型。目前最常见的是基础模型利用 Transformer(文本生成)/ Diffusers(即图像生成)来实现这种适应性。这些模型具有广泛的用例和行业垂直领域的潜在适用性,从聊天机器人和虚拟助手到完全通过文本提示生成视频的市场营销,不一而足。
大语言模型包含数十亿参数,需要大量资源来进行高性能训练和低延迟推理。Amazon EKS 可作为一个有效的协调器,帮助实现这些生成式 AI 工作负载所需的快速扩缩容,同时提供满足企业管理和控制的工具。Amazon EKS 不仅可以简化管理,还提供各种开源工具,以应对独特的机器学习方面的挑战。Amazon EKS 可让您完全控制自己的环境,从而确保最佳成本效益。
解决方案概述
在 Amazon EKS 上部署
Stable Diffusion 模型的架构
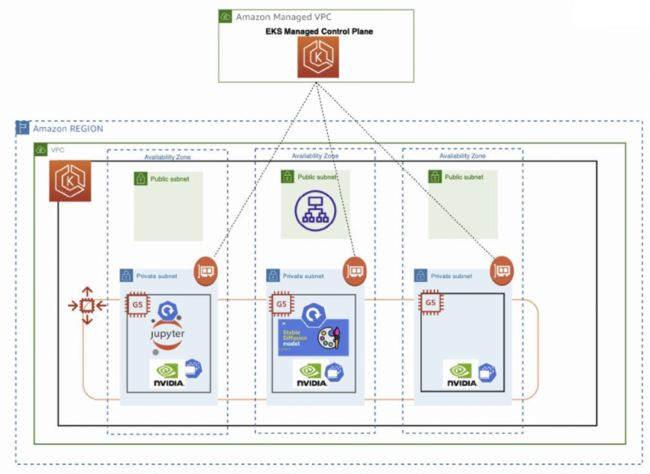
即使在 Kubernetes 环境中,也有大量可用来构建和运行模型的工具。一个新兴的工具栈是 Jupterhub,Argo Workflows,Ray 和 Kubernetes,我们称之为 JARK Stack。
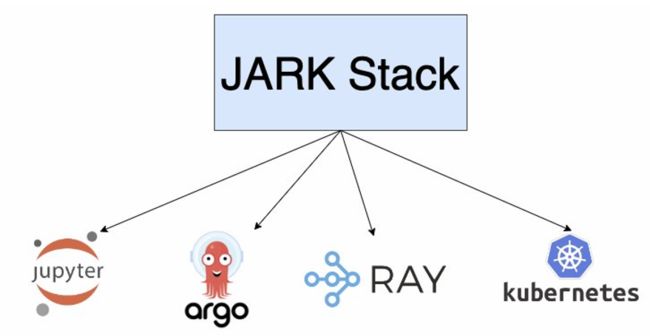
JARK 架构
JupyterHub 提供了一个共享平台,用于运行在商业、教育和研究领域广受欢迎的一些 notebook 。它促进了交互式计算,用户可以在这里执行代码、可视化结果并协同工作。在生成式 AI 领域,JupyterHub 加速了实验过程,尤其是反馈环节。数据工程师也可以在这里一起为模型创建相关的提示工程。
Argo Workflows 是一个开源的容器原生的工作流引擎,用于在 Kubernetes 上协调并行作业。它提供了一个结构化和自动化的流水线,专为微调模型而定制。
这个 Argo 的工作流水线包含以下几个阶段:
数据准备:组织和预处理训练数据集
模型配置:定义大语言模型微调的架构和超参数
微调:执行训练计划
验证:衡量微调模型的性能
超参数调优:优化设置,实现最佳性能
模型评估:使用测试数据评估模型效率
部署:托管模型,满足推理需求
Ray 是一个开源分布式计算框架,可轻松扩展应用程序并使用最先进的机器学习库。Ray 用于在多个节点上分布式训练生成模型,从而加快训练过程,并允许处理更大的数据集。
Ray Serve 是一个功能强大的模型服务库,用于创建在线推理应用编程接口(API)。值得注意的是,它与 PyTorch,Keras 和 Tensorflow 等主要框架兼容。它针对大语言模型服务进行了优化,具有流式响应、动态请求批处理和多节点/多 GPU(图形处理单元)支持等功能。除模型服务外,Ray Serve 还可以将多个模型和业务规则整合到一个服务中。Ray Serve 基于 Ray 构建,旨在实现跨机器的可扩展性,并提供资源节约型调度。关于和 JupyterHub 的关系,虽然两者之间的联系看起来不大,但这两种工具都可以成为更大的机器学习生态的一部分,JupyterHub 可以促进交互式计算,而 Ray Serve 则可以处理模型部署和服务。
Kubernetes 是一个功能强大的容器编排平台,可自动部署、扩展和管理容器化应用程序。Kubernetes 为在容器中运行和扩展生成式 AI 模型提供了基础架构,从而确保了高可用性、容错性和极高的资源利用率。
解决方案架构

演练
关于如何在 Amazon EKS 上
微调和部署模型的分步指南
具体例子
正如我们前面提到的,大多数下游用例都需要根据业务需求为特定任务微调大语言模型。这通常只需要一个实例相对较少的小型数据集,而且在大多数情况下只需一个 GPU 即可完成。在本文中,我们将以 Dreambooth 为例,展示如何调整类似 Stable Diffusion 这种文生图的模型来为一个主题(例如,狗)在不同的场景生成不同的背景图像。Dreambooth 相关的论文描述了一种将唯一标识符与主题(如[v]狗的照片)绑定的方法,以便根据输入提示(如[v]狗在月球上的照片)在逼真的图像中合成所述主题的照片。
Dreambooth 相关的论文
https://arxiv.org/abs/2208.12242
Dreambooth 相关的商业应用可能包括如下几个:
根据文字描述为社交媒体平台、电子商务网站和其他在线平台生成图片。
为用户创建个性化头像。
为网店生成产品图像。
制作营销材料和生成使用视觉教具的教学内容。
在本文的剩余部分,我们将我们的示例模型和推理服务称为 dogbooth。为了在 Amazon EKS 上微调 dogbooth ,我们使用了几种开源技术来支持实现。除了 JARK Stack,我们还利用了 Hugging Face 的两个库,它们为我们提供了个性化 Stable Diffusion 模型的工具:Accelerate 和 Diffusers。
Accelerate 是一个开源库,专门用于简化和优化深度学习模型的训练和微调过程。就我们的目的而言,它提供了一个上层应用程序接口(API),让我们可以轻松地尝试不同的超参数和训练配置,而无需每次重写训练循环,并有效利用可用的硬件资源。
Diffusers 是最先进的预训练 diffusion 模型库,用于生成图像、音频甚至 3D分子结构。他们以脚本集的形式提供了易于使用的训练示例,演示了如何在各种个性化任务中有效地使用 Diffusers,如 Unconditional Training、Text-to-Image Training、Dreambooth、ControlNet、Custom Diffusion 等。
在 Amazon EKS 上部署 Stable Diffusion
模型的步骤
先决条件
Amazon Command Line Interface (Amazon CLI) v2 – the CLI for Amazon services
https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
kubectl – the Kubernetes CLI
https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/
Terraform 1.5 – an infrastructure as code tool
https://developer.hashicorp.com/terraform/downloads
Hugging Face Tokenwith write scope
https://huggingface.co/docs/hub/security-tokens
jq – a lightweight and flexible command line JSON processor
https://jqlang.github.io/jq/
第一步:下载代码
git clone https://github.com/awslabs/data-on-eks.git第二步:部署 Amazon EKS
进入第一步下载的代码目录,到 ai-ml/jark-stack 目录下并执行 install.sh 脚本。这个脚本会执行 Terraform 命令来创建基础设施。值得注意的是资源默认会被部署到 us-west-2 region,可以通过更新文件 variables.tf 里面的值来指定其他的 Amazon Region。整个部署过程大概需要耗时 30 分钟。
cd data-on-eks/ai-ml/jark-stack/terraform
export TF_VAR_huggingface_token=hf_XXXXXXXXXX
./install.sh
Initializing ...
Initializing the backend...
Initializing modules...
Initializing provider plugins...
Terraform has been successfully initialized!
...
SUCCESS: Terraform apply of all modules completed successfully部署的主要资源清单如下:
VPC (subnets, route tables, NAT gateway)
Amazon EKS cluster
Core-Managed Node Group
GPU-Managed Node Group
A kubernetes secret for Hugging Face token
Add-ons
Add-ons
让我们来看一下部署了哪些 add-ons。
aws eks update-kubeconfig --name jark-stack --region us-west-2
kubectl get deployments -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
ingress-nginx ingress-nginx-controller 1/1 1 1 36h
jupyterhub hub 1/1 1 1 36h
jupyterhub proxy 1/1 1 1 36h
kube-system aws-load-balancer-controller 2/2 2 2 36h
kube-system coredns 2/2 2 2 2d5h
kube-system ebs-csi-controller 2/2 2 2 2d5h
kuberay-operator kuberay-operator 1/1 1 1 36h
nvidia-device-plugin nvidia-device-plugin-node-feature-discovery-master 1/1 1 1 36hAmazon EBS CSI Driver
这个 Driver 允许 Amazon EKS 管理 Amazon EBS 持久卷的生命周期。默认的 StorageClass 是 gp3 。
Amazon Load Balancer Controller
这个 controller 为 Amazon EKS 管理 Amazon ELB。您需要一个网络负载均衡器来访问我们的 Jupyter notebook,最终还需要另一个网络负载均衡器来为我们的自托管推理服务提供入口,这将在本文的后面部分讨论。
NVIDIA Device Plugin
NVIDIA Device Plugin 是一个 Kubernetes DaemonSet,它是 Kubernetes 集群和其底层 GPU 之间的桥梁,允许我们在集群上运行支持 GPU 的容器。
JupyterHub
Terraform 脚本安装了 JupyterHub。在本例中,我们将 values.yaml 传递给了 Helm Chart,这个 values.yaml 定义了 JupyterHub 使用负载均衡器对外提供服务、对 GPU 资源的要求、基于 Amazon EBS 的存储卷用于持久化。请注意,我们展示了 Notebook 基于用户名和密码的基本用户身份验证,仅供演示之用。对于实际场景的设置,请考虑使用 identity provider。
...
proxy:
service:
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-type: external
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: 'true'
service.beta.kubernetes.io/aws-load-balancer-ip-address-type: ipv4
singleuser:
image:
name: public.ecr.aws/h3o5n2r0/gpu-jupyter
tag: v1.5_cuda-11.6_ubuntu-20.04_python-only
pullPolicy: Always
..
extraResource:
limits:
nvidia.com/gpu: "1"
extraEnv:
HUGGING_FACE_HUB_TOKEN:
valueFrom:
secretKeyRef:
name: hf-token
key: token
storage:
capacity: 100Gi
...
- name: notebook
configMap:
name: notebook
...Ingress-Nginx
Ingress-Nginx 允许我们使用一些路径重写的规则,在同一个负载均衡器上同时暴露 Ray dashboard 和推理入口。还允许我们运行多个 Ray 服务入口,并使用基于路径的路由方式来实现同一个负载均衡器提供不同版本的模型服务。
Kuberay-Operator
KubeRay Operator 使在 Kubernetes 上部署和管理 Ray 集群变得简单便捷。Ray 集群被定义为 custom resource,由高容错性的 Ray Controller 管理。KubeRay Operator 可自动执行 Ray 集群生命周期管理、自动扩展和其他关键功能。 稍后,我们将介绍如何使用集群上的 RayService 自定义资源定义为 dogbooth 创建推理服务。
第三步:微调 Stable Diffusion 模型
现在,您可以开始尝试使用我们的模型,并准备一个 Jupyter Notebook,帮助我们根据您的需求进行个性化设置。
下面首先获取负载均衡器的域名。
kubectl get svc proxy-public -n jupyterhub --output jsonpath='{.status.loadBalancer.ingress[0].hostname}'使用浏览器打开上述域名,并使用在 jupyterhub-values.yaml 文件配置的用户名密码登陆。如下图。

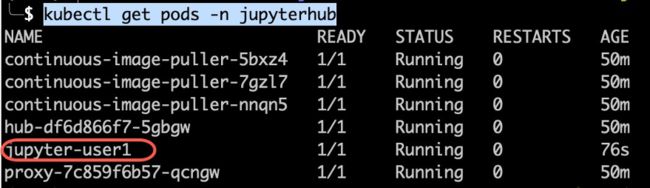
这会触发在 g5 节点上创建了一个 Jupyter-user1 的 Pod。执行 kubectl get pods -n jupyterhub 即可看到类似下图的结果。
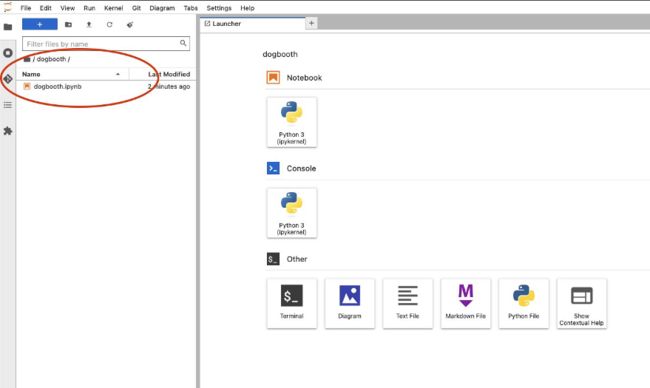
当这个 Pod 正常运行之后,您的浏览器就会自动跳转到 notebook console。点击打开 dogbooth 目录里面的 Python noteboot。如下图所示。
打开之后,您就可以逐步执行这个 jupyter notebook 定义的内容了。如下图所示,第一步执行了 nvidia-smi 命令去确认当前的 Notebook 实例是运行在 GPU 节点上的并且可以见到 GPU 芯片的详细信息。

接下来的四步就是配置开发环境,包括从 GitHub 下载 diffusers 库和安装 Python 依赖。另外,为了实现 memory efficient attention,还需要安装 xFormers。

接下来就是安装 bitsandbytes,它可以允许我们使用 8-bit 的优化器进一步减少内存的需求。
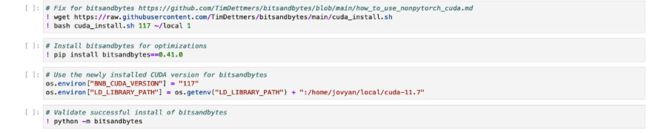
成功安装 bitsandbytes 之后,下一步就是要配置 dreambooth 训练脚本所需要的环境。这包括安装一些额外的依赖包,配置默认加速设置,登录 HuggingFace 并下载示例数据集。
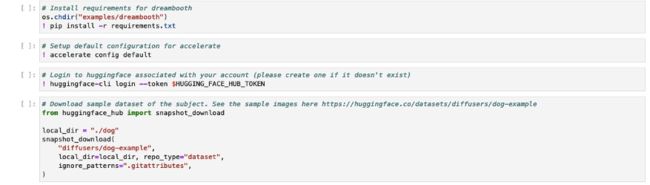
现在,您可以为输入模型的位置、数据集目录和微调后模型的输出目录设置环境变量,然后开始微调模型。HuggingFace accelerate 会完成所有繁重的工作,帮助我们对模型进行实验。以下示例中使用的超参数经过优化,可在 1 个配备 24 GB 内存的英伟达 A10G GPU 上成功运行训练。

完成这项工作大约需要 1.5 个小时。您可以通过更改一些超参数(如 -max_train_steps=400 )来减少训练时间,但这是以牺牲模型的性能和准确性为代价的。
训练脚本完成后,您就可以验证模型是否已创建,并运行样本推理以检查其性能如何。

打开 dog-bucket.png,这张图片在/home/jovyan/diffusers/examples/deambooth 目录下。
由于 HuggingFace accelerate 也会将模型上传到 HuggingFace,因此您甚至可以在其托管推理 API 上测试推理样本。您可以在这里找到您的模型 https://huggingface.co/spaces//dogbooth 或者在您指定的模型输出目录中。

如果模型过拟合或者欠拟合,请参考 HuggingFace 对 dreambooth 的深入分析(https://huggingface.co/blog/dreambooth),以帮助您调整超参数,提高模型性能。这些建议超出了本文的讨论范围。
第四步:提供大语言模型服务
现在您已经拥有了一个微调过的模型,可以使用这个模型在 Amazon EKS 上创建推理节点了。
您可以使用 RayService 自定义资源定义(CRD)来部署一个带有 RayServe 应用程序的 Ray 集群,该应用程序会调用您之前通过 accelerate 训练脚本微调并推送到 HuggingFace 的模型。
定义 RayService 入口
RayServe 的 Python 应用程序被打包成一个容器镜像,在部署的时候可以被拉取到 RayCluster 中。Ray 的文档提供了使用 Ray Serve 和 FastAPI 创建推理应用程序的示例代码。我们对提供的 Python 代码进行了调整,通过向 RayService 配置传递环境变量 MODEL_ID,将推送到 HuggingFace 的自定义 dogbooth 模型的 model_id 作为该环境变量的值传递进去,如以下步骤所示。同时可以在 src/service/dogbooth.py 查看相关的 Python 代码。想要查看 RayCluster 的 head 和 worker 节点的容器镜像的 Dockerfile, 可以在这里 src/service/Dockerfile 找到。
探索更高级的 RayService 的配置将作为练习留给读者。
定义 RayService
现在可以部署 RayService 了。我们在目录 data-on-eks/ai-ml/jark-stack/terraform/src/service 提供了 RayService 的 Kubernetes 定义文件 ray-service.yaml。这个文件主要包含了如下定义:
创建名为 dogbooth 的命名空间,用以部署 RayCluster。
创建一个 ingress, 以便通过 ingress-nginx 将 RayService 入口暴露给亚马逊云科技网络负载均衡器,并为界面和推理服务提供基于路径的路由。
编辑 env_vars 下的 MODEL_ID,将模型库更改为微调后的模型库。
---
apiVersion: v1
kind: Namespace
metadata:
name: dogbooth
---
apiVersion: ray.io/v1alpha1
kind: RayService
metadata:
name: dogbooth
namespace: dogbooth
spec:
...
serveConfig:
importPath: dogbooth:entrypoint
runtimeEnv: |
env_vars: {"MODEL_ID": "askulkarni2/dogbooth"}
rayClusterConfig:
rayVersion: '2.6.0'
headGroupSpec:
...
template:
spec:
containers:
- name: ray-head
image: $SERVICE_REPO:0.0.1-gpu
resources:
limits:
cpu: 2
memory: 16Gi
nvidia.com/gpu: 1
...
workerGroupSpecs:
- replicas: 1
...
template:
spec:
containers:
- name: ray-worker
image: $SERVICE_REPO:0.0.1-gpu
...
resources:
limits:
cpu: "2"
memory: "16Gi"
nvidia.com/gpu: 1
...
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dogbooth
namespace: dogbooth
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/\$1"
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /dogbooth/(.*)
pathType: ImplementationSpecific
backend:
service:
name: dogbooth-head-svc
port:
number: 8265
- path: /dogbooth/serve/(.*)
pathType: ImplementationSpecific
backend:
service:
name: dogbooth-head-svc
port:
number: 8000执行命令 kubectl apply -f src/service/ray-service.yaml 在 dogbooth 命名空间中创建 RayService。
一旦执行,RayCluster 的 head 和 worker 节点就会被调度到 GPU 节点上,同时推理入口会被创建并通过负载均衡器向我们提供服务。因为基于 GPU 的 rayproject/ray-ml:2.6.0-gpu 基础镜像比较大,整个部署过程会持续大概 8 分钟左右。
执行 kubectl get pods -n dogbooth –watch 命令观察并等待 Pods 正常运行。之后就可以执行命令 kubectl get ingress dogbooth -n dogbooth --output jsonpath='{.status.loadBalancer.ingress[0].hostname}' 获取负载均衡器的域名来访问 Ray 的控制台。在浏览器中打开获取到的连接(类似 http://k8s-ingressn-ingressn-xxx.elb.us-east-1.amazonaws.com/dogbooth/) ,您可以见到如下图所示的界面。
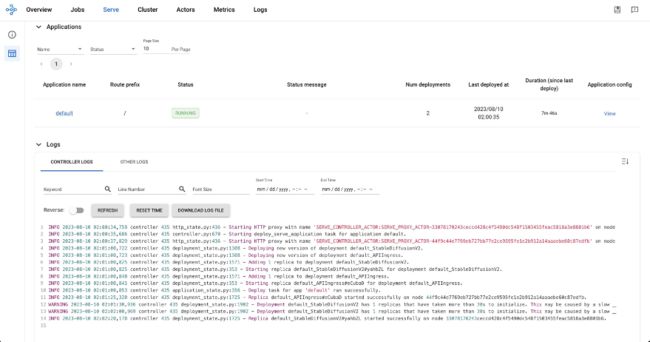
最后,通过以下提示验证我们的 dogbooth 模型部署,例如:
http://k8s-ingressn-ingressn-xxx.elb.us-east-1.amazonaws.com/dogbooth/serve/imagine?prompt=a photo of [v]dog on the beach但 Argo Workflows 在哪里?
很高兴您能这么问,我们并没有忘记 Argo Workflows。我们前面讨论的步骤非常适合在问题形成和用例分析的早期阶段进行实验。一旦您找到了符合特定目标的模型,并希望将其部署到生产环境中,这时候协调数据科学家,开发者,运营团队和领域专家的就是 MLOps 了。这种协作可确保模型的开发、部署和管理符合业务目标,并满足运营要求。这就是工作流引擎发挥作用的地方。业界比较流行的工作流引擎有 Kubeflow Pipeline(基于 Argo Workflows),Apache Airflow,Amazon Step Functions 等等。我们在这篇文章(https://aws.amazon.com/blogs/containers/dynamic-spark-scaling-on-amazon-eks-with-argo-workflows-and-events/)中介绍了类似的方法,使用 Argo Events 和 Argo Workflows 作为 Kubernetes 原生的 Workflow 引擎来编排使用 Spark 进行的数据处理作业。进一步延展,我们可以开始思考怎么利用类似方法为生成式 AI 项目构建一个 MLOps 平台。我们将在接下来的文章和 re:Invent 研讨会中更深入地探讨这个系列的话题。
清理资源
要清理在本文中创建的相关资源,执行以下命令即可。
./cleanup.sh这个脚本会删除 RayService 和执行 terraform destroy 命令删除所有基础设施。
总结
在这篇文章中,我们向您介绍了生成式 AI 模型的出现、它们的优势、关键用例以及创建高适用性输出所需的资源密集性质。我们还谈到了 Amazon EKS 对于实现这些用例所具备的关键优势。Amazon EKS 通过它内置的可扩展性、弹性和跨环境的可重复部署,使客户能够拥有更多的控制权、更大的灵活性以及更高的成本效益。然后,我们还向您介绍了利用 JARK Stack 在 Amazon EKS 上部署生成式 AI 模型的步骤。
亚马逊云科技通过 DataonEKS 项目向您提供了加速采纳机器学习的能力。DataonEKS 是亚马逊云科技的一个开源项目,为在 Amazon EKS 上部署数据工作负载提供最佳实践、基准报告、基础设施即代码(Terraform)模板、部署示例和参考架构。
此外,亚马逊云科技还提供 Amazon Bedrock 和 Amazon Sagemaker 等全托管的机器学习解决方案,可用于轻松部署现成的基础模型,或创建和运行自己的模型。
生成式 AI 处于非常早期的阶段,几乎每天都在快速发展和持续创新。亚马逊云科技很高兴能成为您的合作伙伴,利用我们在市场上最全面、最完整的机器学习功能支持您任何的生成式 AI 需求。我们期待与您在生成式 AI 和机器学习之旅以及未来的道路上合作!
原文链接:https://aws.amazon.com/blogs/containers/deploy-generative-ai-models-on-amazon-eks/
本篇作者

Sanjeev Ganjihal
亚马逊云科技高级解决方案架构师。Sanjeev 专注于服务网格、GitOps、IAC、自动扩展和成本优化。他帮助客户在亚马逊云科技上运行、构建和扩展容器化工作负载。

Apoorva Kulkarni
亚马逊云科技高级解决方案架构师。Apoorva 帮助客户在亚马逊云科技的容器服务上构建现代应用程序平台。

Rama Prasanna Ponnuswami
亚马逊云科技 WorldWide Goto-Market Specialist,专注于 EKS/EKS-A 领域。Rama 与世界各地的客户合作,指导他们使用亚马逊云科技提供的各种容器解决方案,加速他们的云/容器现代化之旅。

Roland Barcia
亚马逊云科技解决方案架构师总监。Roland 花了 25 年的时间帮助客户构建和现代化系统,并领导着一支专注于 Kubernetes、应用程序现代化、微服务、无服务器、集成和平台工程的全球团队。
校译作者

梁宇
亚马逊云科技专业服务团队 DevOps 顾问,主要负责 DevOps 技术实施。尤为热衷云原生服务及其相关技术。在工作之余,他喜欢运动,以及和家人一起旅游。
星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
