基于Pytorch的DDP训练Mnist数据集
在前几期的博文中我们讲了pytorch的DDP,但是当时的demo是自制的虚拟数据集(Pytorch分布式训练:DDP),这期文章我们使用Mnist数据集做测试,测试并完善代码。
快速开始
1. 我们修改一下main函数,在main函数中导入Mnist数据。我这里把测试集关闭了,需要的可以打开。
def main(rank, world_size, max_epochs, batch_size):
ddp_setup(rank, world_size)
train_dataset = datasets.MNIST(root="./MNIST", train=True, transform=data_tf, download=True)
train_dataloader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=False,
sampler=DistributedSampler(train_dataset))
model = Net()
# optimzer = torch.optim.Adam(model.parameters(), lr=1e-3)
optimzer = torch.optim.SGD(model.parameters(), lr=1e-2)
trainer = Trainer(model=model, gpu_id=rank, optimizer=optimzer, train_dataloader=train_dataloader)
trainer.train(max_epochs)
destroy_process_group()
# test_dataset = datasets.MNIST(root="./MNIST", train=False, transform=data_tf, download=True)
# test_dataloader = DataLoader(test_dataset,
# batch_size=32,
# shuffle=False)
# evaluation(model=model, test_dataloader=test_dataloader)2. 修改模型结构,非常简单的一个网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear( 64*5*5, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# print(x.shape)
x = x.view(-1, 64*5*5)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return x3. 完整代码如下,增加了计算准确率的功能,这些代码可以自己写个函数进行封装的,我太懒了。。。
"""
pytorch分布式训练结构
"""
from time import time
import os
import torch.nn as nn
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 多gpu训练所需的包
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
def ddp_setup(rank, world_size):
"""
每个显卡都进行初始化
"""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
# init_process_group(backend="nccl", rank=rank, world_size=world_size)
init_process_group(backend="gloo", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5],[0.5])]
)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear( 64*5*5, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
# print(x.shape)
x = x.view(-1, 64*5*5)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return x
class Trainer:
def __init__(self, model, train_dataloader, optimizer, gpu_id):
self.gpu_id = gpu_id
self.model = model.to(gpu_id)
self.train_dataloader = train_dataloader
self.optimizer = optimizer
self.model = DDP(model, device_ids=[gpu_id])
self.criterion = torch.nn.CrossEntropyLoss()
def _run_batch(self, xs, ys):
self.optimizer.zero_grad()
output = self.model(xs)
loss = self.criterion(output, ys)
loss.backward()
self.optimizer.step()
_, predicted = torch.max(output, 1)
return ys.size(0), (predicted == ys).sum()
def _run_epoch(self, epoch):
batch_size = len(next(iter(self.train_dataloader))[0])
# print(f"|GPU:{self.gpu_id}| Epoch:{epoch} | batchsize:{batch_size} | steps:{len(self.train_dataloader)}")
# 打乱数据,随机打乱
self.train_dataloader.sampler.set_epoch(epoch)
sample_nums = 0
train_correct = 0
for xs, ys in self.train_dataloader:
xs = xs.to(self.gpu_id)
ys = ys.to(self.gpu_id)
sample_num, correct = self._run_batch(xs, ys)
sample_nums += sample_num
train_correct += correct
# print(train_correct.item(), sample_nums)
print(f"train_acc: {train_correct.item() / sample_nums * 100 :.3f}")
def _save_checkpoint(self, epoch):
ckp = self.model.module.state_dict()
PATH = f"./params/checkpoint_{epoch}.pt"
torch.save(ckp, PATH)
def train(self, max_epoch: int):
for epoch in range(max_epoch):
self._run_epoch(epoch)
# if self.gpu_id == 0:
# self._save_checkpoint(epoch)
def evaluation(model, test_dataloader):
model.eval()
model.to("cuda:0")
sample_nums = 0
train_correct = 0
for xs, ys in test_dataloader:
xs = xs.to("cuda:0")
ys = ys.to("cuda:0")
output = model(xs)
_, predicted = torch.max(output, 1)
sample_nums += ys.size(0)
train_correct += (predicted == ys).sum()
print(f"test_acc: {train_correct.item() / sample_nums * 100 :.3f}")
def main(rank, world_size, max_epochs, batch_size):
ddp_setup(rank, world_size)
train_dataset = datasets.MNIST(root="./MNIST", train=True, transform=data_tf, download=True)
train_dataloader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=False,
sampler=DistributedSampler(train_dataset))
model = Net()
# optimzer = torch.optim.Adam(model.parameters(), lr=1e-3)
optimzer = torch.optim.SGD(model.parameters(), lr=1e-2)
trainer = Trainer(model=model, gpu_id=rank, optimizer=optimzer, train_dataloader=train_dataloader)
trainer.train(max_epochs)
destroy_process_group()
# test_dataset = datasets.MNIST(root="./MNIST", train=False, transform=data_tf, download=True)
# test_dataloader = DataLoader(test_dataset,
# batch_size=32,
# shuffle=False)
# evaluation(model=model, test_dataloader=test_dataloader)
if __name__ == "__main__":
start_time = time()
max_epochs = 50
batch_size = 128
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, max_epochs, batch_size), nprocs=world_size)
print(time() - start_time)
训练测试
我简单的测试了一下单卡和多卡的GPU性能(一张3090、一张3090ti),表格如下:
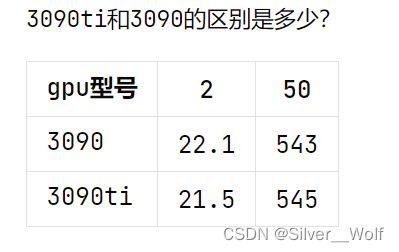
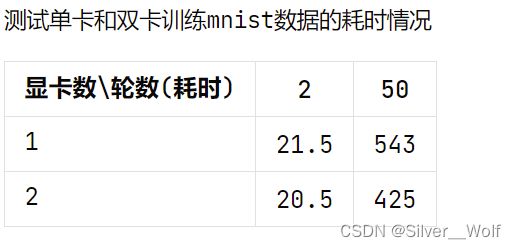
在数据量较小的前提下双卡对单卡优势不明显,加大epoch才能看出明显差距。
结尾
如果不出意外DDP的内容已经结束了,后续发现什么好玩的继续发出来
如果觉得文章对你有用请点赞、关注 ->> 你的点赞对我太有用了
群内交流更多技术
130856474 <-- 在这里