黑盒提示优化:在不进行模型训练的情况下对齐大型语言模型
Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
1、写作动机:
为了使LLMs更好地遵循用户的指令,现有的对齐方法大多集中在进一步训练它们。然而,LLMs的额外训练通常在GPU计算方面昂贵;更糟糕的是,用户需求的训练模型很多都是闭源的,例如GPTs。
2、过去的一些将LLM与人类偏好对齐的方式以及不足:
已经投入了大量工作来引导LLMs接近人类偏好,包括来自人类反馈的强化学习(RLHF)、来自AI反馈的强化学习(RLAIF),或者直接偏好优化(DPO)。然而,这些方法存在各种不足之处:
- 效率: 随着LLMs的规模变大,使用以RL算法为基础的目的训练这些模型变得更加昂贵和困难。
- 可访问性: 大多数性能最佳的LLMs,如GPT-4(OpenAI,2023)和Claude2(Anthropic,2023a),都是封闭的,只能通过API访问,这使得这些基于训练的方法不适用于组织外的用户来增强对齐。
- 可解释性: 在使用这些方法时,对人类偏好的建模和确切的改进是不可解释的。
3、本文贡献:
a、提出了一种黑盒提示优化方法BPO,它可以在不对这些模型进行训练的情况下增强LLMs对人类偏好的对齐,展示了在包括基于API和开源模型在内的各种LLMs上的改进。
b、证明BPO是一种新颖且有竞争力的对齐方法,除了现有的RLHF和偏好学习方法外,还在广泛实验中优于PPO和DPO。
c、系统地分析了BPO如何从提示解释、澄清、丰富和增强安全性的角度优化原始提示。展示了与对齐LLMs时现有偏好学习算法相比,其更好的可解释性。
4、黑盒提示优化:

黑盒提示优化的步骤:首先收集了带有人类偏好注释的多个指令微调数据集,仔细筛选和过滤低质量的数据。随后,利用LLM捕捉人类喜欢和不喜欢的响应之间的差异,基于这一差异,我们利用LLM来优化输入。然后,我们得到了原始指令及其改进版本的一对,利用这对数据我们进一步训练一个序列到序列的模型,以自动优化用户输入。
任务定义:形式上,将用户输入表示为Xuser。目标是构建一个函数F,将Xuser映射到其优化版本,表示为Xopt。LLMs具有理解各种响应中不同特征的能力。因此,选择利用LLMs获取Xopt。具体而言,每个样本表示为(Xuser,Ygood,Ybad),其中Ygood表示喜好的响应,Ybad表示不喜好的响应。因此,带有LLM的提示优化过程可以表示为Xopt = LLM(Xuser,Ygood,Ybad)。最后,通过在(Xuser,Xopt)对上训练一个较小的序列到序列模型来构建F函数。
训练数据集构建:从OASST1数据集、hh-rlhf数据集、Chatbot Arena Conversations数据集、Alpaca-GPT4数据集收集了约14k个格式为(Xuser,Ygood,Ybad)的多样化样本,随后,利用ChatGPT优化这些指令。最终分布如下表:

模型训练:
形式上为在给定输入Xuser的条件下生成Xopt,损失函数规定为:

其中N是Xopt的长度,xt表示Xopt中的第t个token。在这项工作中,选择使用llama2-7b-chat作为backbone,因为作者认为更强大的模型可以更好地学习Xuser和Xopt之间的隐式偏好映射。
与现有模型的比较:

5、实验:
5.1对齐性评估:
在Dolly Eval、Vicuna Eval、Self-Instruct Eval、BPO-test Eval数据集上,使用GPT-4和Claude进行评估,对于BPO,使用Llama-2-7b-chat-hf2作为backbone。实验结果如下:

在gpt-3.5-turbo和text-bison上,平均胜率提高了约20%,在包括gpt-4在内的一些模型上提高了更多10%,这表明了BPO方法的强大性能。此外,无论是在小型开源模型(如llama2-7b-chat和vicuna-7b)还是强大的大规模模型(如gpt-4和claude-2)上,都取得了一致的增益,突显了BPO对于各种模型的稳健泛化能力。
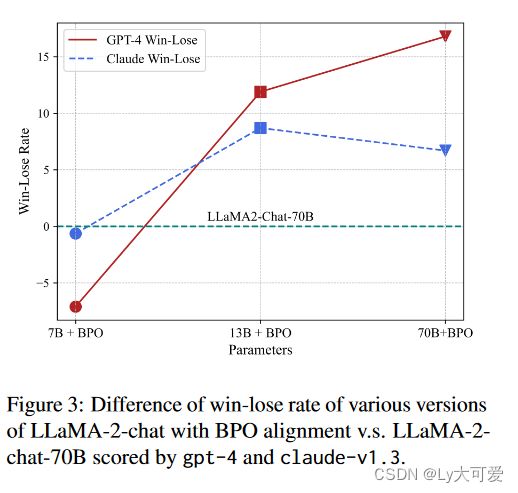
在Claude的评估下,经过BPO对齐的llama2-7b-chat几乎达到了llama2-70b-chat模型的性能水平。对于llama2-13b-chat模型,BPO使其在很大程度上超越了70b模型,展示了BPO提升小型模型超越大型模型的潜力。
5.2 RLHF实验结果:

PPO、DPO和BPO都成功地提高了vicuna-7b和vicuna-13b的性能。此外,具有BPO的SFT模型在性能上优于PPO和DPO对齐的模型,突显了BPO的优势。与BPO对齐一起,PPO和DPO都可以得到很大的改进。
5.3BPO用于数据增强:
首先使用BPO优化原始指令,并使用这些优化的指令作为text-davinci-003的输入来生成响应。这样就提供了一个精炼的Alpaca数据集,使用这个新数据集对llama-7b和llama-13b进行训练。实验结果表明,与在原始Alpaca数据集上训练的LLMs相比,BPO在重建数据上取得了实质性的增益。

5.4迭代提示优化:
对原始指令进行了5次迭代优化,并将胜率与原始指令进行了比较。如图所示,∆WR通过4次迭代实现了显著的改进,在第五次迭代上略微下降。

5.5消融实验:
比较了反馈学习优化(BPO)和直接使用gpt-3.5-turbo进行提示优化。如下表所示,直接优化可以提高模型性能,这验证了LLMs有成为良好提示工程师的潜力。但是BPO在直接优化的基础上提供了进一步的改进。

6、BPO的可解释性:
与基于模型训练的对齐方法(如PPO或DPO)相比,BPO在其强大的可解释性方面具有明显优势,因为我们可以直接比较优化前后的指令,以找出BPO的工作原理。BPO常见的4种优化策略如下:

错误分析:

7、局限性:
a、本文的提示优化器仅在来自少数现有学术反馈数据集的14k对优化提示的组合上进行了训练。它涵盖了有限的情境范围,尚未在大量数据上进行训练。
b、缺乏长上下文提示和与数学相关的问题的提示。