C++回顾(二十五)—— map/multimap容器
25.1 map/multimap的简介
- map是标准的关联式容器,一个map是一个键值对序列,即(key,value)对。它提供基于key的快速检索能力。
- map中key值是唯一的。集合中的元素按一定的顺序排列。元素插入过程是按排序规则插入,所以不能指定插入位置。
- map的具体实现采用红黑树变体的平衡二叉树的数据结构。在插入操作和删除操作上比vector快。
- map可以直接存取key所对应的value,支持[]操作符,如map[key]=value。
- multimap与map的区别:map支持唯一键值,每个键只能出现一次;而multimap中相同键可以出现多次。multimap不支持[]操作符。
- 需要添加头文件:`#include
25.2 map/multimap构造
- map/multimap采用模板类实现,对象的默认构造形式:
map
multimap
如:
map<int, char> mapA;
map<string,float> mapB;
//其中T1,T2还可以用各种指针类型或自定义类型
map(const map &mp); //拷贝构造函数
25.3 map的使用
(1)map的插入与迭代器
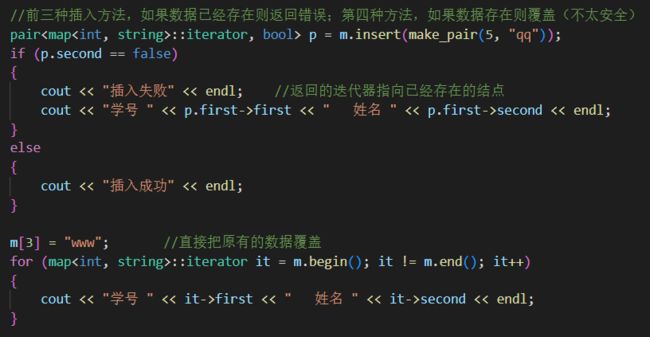
map.insert(…); //往容器插入元素,返回pair
在map中插入元素的三种方式:
假设 map
-
一、通过pair的方式插入对象:
mapStu.insert( pair -
二、通过make_pair的方式插入对象:
mapStu.inset(make_pair(-1, “校长-1”)); -
三、通过value_type的方式插入对象:
mapStu.insert( map -
四、通过数组的方式插入值:
mapStu[3] = “小刘"; mapStu[5] = “小王"; -
前三种方法,采用的是insert()方法,该方法返回值为pair
-
第四种方法非常直观,但存在一个性能的问题。插入3时,先在mapStu中查找主键为3的项,若没发现,则将一个键为3,值为初始化值的对组插入到mapStu中,然后再将值修改成“小刘”。若发现已存在3这个键,则修改这个键对应的value。

(2)map对象的拷贝构造与赋值
map& operator=(const map &mp);//重载等号操作符map.swap(mp);//交换两个集合容器
(3)map的大小
map.size();//返回容器中元素的数目map.empty();//判断容器是否为空
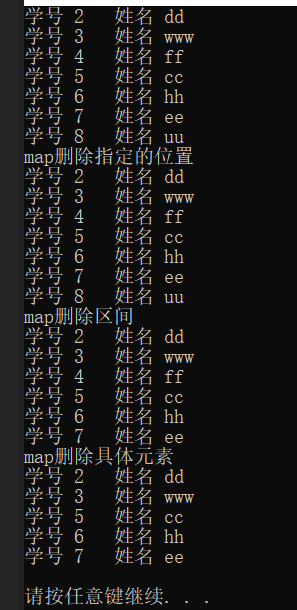
(4)map的删除
map.clear();//删除所有元素map.erase(pos);//删除pos迭代器所指的元素,返回下一个元素的迭代器。map.erase(beg,end);//删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。map.erase(keyElem);//删除容器中key为keyElem的对组。
(5)map的查找
map.find(key);查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回map.end();map.count(keyElem);//返回容器中key为keyElem的对组个数。对map来说,要么是0,要么是1。对multimap来说,值可能大于1。
完整示例代码:
#include 运算结果:
(6)multimap
- Multimap:1个key值可以对应多个value
Multimap 案例:
公司有销售部 sale (员工2名)、技术研发部 development (1人)、财务部 Financial (2人)
人员信息有:姓名,年龄,电话、工资等组成
通过 multimap进行 信息的插入、保存、显示
分部门显示员工信息
示例代码:
#include 运行结果:

25.4 容器的共性机制
25.4.1 容器共同能力
理论提高:
所有容器提供的都是值(value)语意,而非引用(reference)语意。容器执行插入元素的操作时,内部实施拷贝动作。所以STL容器内存储的元素必须能够被拷贝(必须提供拷贝构造函数)。
-
除了queue与stack外,每个容器都提供可返回迭代器的函数,运用返回的迭代器就可以访问元素。
-
通常STL不会丢出异常。要求使用者确保传入正确的参数。
-
每个容器都提供了一个默认构造函数跟一个默认拷贝构造函数。如已有容器vecIntA。
vector//调用拷贝构造函数,复制vecIntA到vecIntB中。vecIntB(vecIntA); -
与大小相关的操作方法(c代表容器):
c.size();//返回容器中元素的个数
c.empty();//判断容器是否为空 -
比较操作(c1,c2代表容器):
c1 == c2 判断c1是否等于c2
c1 != c2 判断c1是否不等于c2
c1 = c2 把c2的所有元素指派给c1
25.4.2 各种容器的使用时机
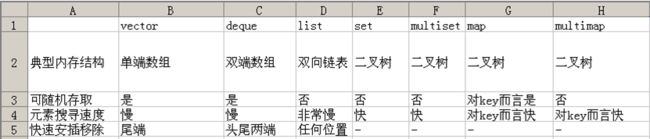
-
deque的使用场景:比如排队购票系统,对排队者的存储可以采用deque,支持头端的快速移除,尾端的快速添加。如果采用vector,则头端移除时,会移动大量的数据,速度慢。
-
vector与deque的比较:
(1)vector.at()比deque.at()效率高,比如vector.at(0)是固定的,deque的开始位置却是不固定的。
(2)如果有大量释放操作的话,vector花的时间更少,这跟二者的内部实现有关。
(3)deque支持头部的快速插入与快速移除,这是deque的优点。 -
list的使用场景:比如公交车乘客的存储,随时可能有乘客下车,支持频繁的不确实位置元素的移除插入。
-
set的使用场景:比如对手机游戏的个人得分记录的存储,存储要求从高分到低分的顺序排列。
-
map的使用场景:比如按ID号存储十万个用户,想要快速要通过ID查找对应的用户。二叉树的查找效率,这时就体现出来了。如果是vector容器,最坏的情况下可能要遍历完整个容器才能找到该用户。