【论文笔记】OSDI04 MapReduce: Simplified Data Processing on Large Clusters
overview
论文地址
google的经典论文。
MapReduce是一种编程模型(类似于现在的框架),主要是将分布式算法进行了抽象,MP负责处理分布式中的容错、通信等,程序员只需要关注具体的业务实现,即Mapper和Reducer的逻辑。
MP run on GFS.
整个模型的输入是 key/value对 集合,输出也是若干的 key/value对集合,以文件的形式保存。用户需要自定义两个函数,map和reduce。map是将输入的KV进行处理,转为中间KV,中间KV交给reduce处理,最终输出结果。以字数统计为李,输入的是文档,k是文件名,V是文档内容,map处理文档后,产生中间结果KV,K是字,V是字出现的次数(一般都以1为例了,但论文中提到map后会进行combiner,即变成了出现次数,但仅是部分文档中出现的次数,并非最终的结果)。对于中间KV,reduce再次进行合并,最终得到每个字在全部文档中的出现次数。
实现
以执行的流程来介绍实现。示意图如下。
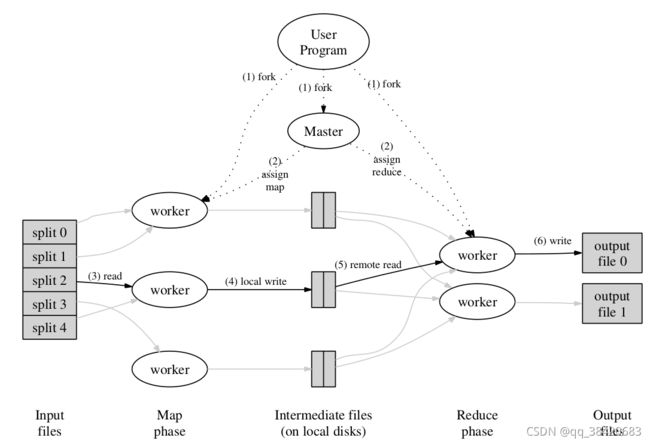
- 划分
MP(mapreduce)首先对数据进行划分,划分为M份(该值由用户指定),一般每份数据在16M-64M之间,也用户指定了输出的文件数R。划分函数一般直接使用hash,对于特殊的如url等可以基于域名来进行划分
M和R即 map task 和reduce task的数量,为了负载均衡,M一般远大于机器数,R受到输出文件的约束,一般为机器数的若干倍。论文中举例,集群有2,000个worker,则M为200,000,R为5,000。
在GFS中,数据会在不同的机器上进行备份,一般是3份。
然后进行fork。
- fork && master
在众多子进程中,master是一个重要的副本,剩下的都是worker。worker被划分为map和reduce。
master负责进行调度worker执行任务。由于数据有多个副本,为了降低数据的转移对网络带宽的需求,在分配任务时,尽量保证在本地执行,即数据在哪,相关的map 和reduce就在哪执行。
master中还保留了所有任务的信息,包括状态和执行的worker id。每当一个map 执行完成后,map返回中间KV的文件地址和大小给master,master将这些信息以增量的方式给正在执行的reduce 。(reduce不停?)
当master宕机后,理论上可以通过对master备份来恢复,但MP没有实现,master宕机后的建议是重启…
master对worker进行心跳检测,当worker宕机后,已完成的map任务会重新执行,因为原map任务执行后的结果在map worker本地,已经不可访问;而已完成的reduce任务则不需要,因为最终结果是在全局文件系统中(GFS中)。
- map
map从输入中读入数据,处理后产生中间KV,缓存于内存中。 缓存被划分为R份,并定期的写入map所在的本地磁盘上( 谁写入的 master还是work)。缓存划分一般是通过hash来实现的,也提供了通过url域名的方式来划分。
写入后通知master中间结果的文件位置。对于同一个map task产生的多个中间结果,master只记录一次的。有多个中间结果是因为map worker宕机后重新执行产生的。
在一些情况下,map执行后,进行一次reduce会更方便后续处理。如在word count中,每个KV对中,V都是1,对相同的K进行合并也是合理的,这样能降低网络中数据传送量。这样的reduce被成为combiner funcion。
- reduce
master通知reduce worker中间kv的文件地址,reduce通过rpc去读取,并且根据key对其进行排序。
reduce对排序后的结果进行遍历,将相同key的KV对传给用户定义的reduce function。reduce function的输出被追加到这个reduce task的输出文件中。
一个reduce task执行完成后,其结果是产生一个由用户指定名字的最终文件,该文件是由临时文件改名而来的。若一个reduce task被执行多次,则在改名时会发生冲突,GFS将拒绝改名。避免reudce task重复执行产生的重复结果是通过GFS中改名的原子操作实现的。
after all Maps have finished, coordinator hands out Reduce tasks
each Reduce fetches its intermediate output from (all) Map workers
each Reduce task writes a separate output file on GFS
- 结束
当map 和reduce都执行完,master 唤醒 用户程序。
在快结束的时候,可能会出现straggler影响整体的时间,即个别任务执行较慢,花费时间较长。straggler出现的原因可能是硬件导致的,如磁盘中坏道增多等。解决的办法是,在快结束时,每个task分配多个worker去执行。
缺点
MP是无状态的
不方便迭代