一种用于实时通信的Google拥塞控制算法
原文链接 draft-ietf-rmcat-gcc-02
简介
实时媒体的拥塞控制具有挑战性,原因如下:
1、媒体的编码格式不能快速的适应不同的带宽,带宽需求经常被改变。
2、参与者可能对如何响应有特定的期望,发现拥塞的流可能不会减少所需的带宽。
3、编码通常对数据包丢失很敏感,而实时性和通过重传修复数据包丢失相排斥。
本文描述了两种拥塞控制算法,它们共同能够提供良好的性能,并与使用相同拥塞控制的其他视频流以及共享相同链路的TCP流合理共享带宽。
系统模型
系统中包含以下元素:
1、RTP packet:包含媒体数据的RTP数据包。
2、Group of packets:由组出发和组到达时间(绝对发送时间)[abs发送时间]唯一标识的发送方发送的一组RTP数据包集合。这些数据包可以是视频数据包、音频数据包,也可以是音频和视频数据包的混合。
3、Incoming media stream:由RTP数据包组成的帧流。
4、RTP Sender:通过网络将RTP流发送到RTP接收器。它生成RTP时间戳和abs发送时间头扩展。
5、RTP receiver:接收RTP流,标记到达时间。
6、RTCP sender at RTP receiver :RTP接收端的RTCP发送者,负责发送接受者报告、REMB消息和传输范围的RTCP反馈消息。
7、RTCP receiver at RTP sender:RTP发送端端RTCP接收者,接收接收方报告和REMB消息,传输RTCP范围内的反馈消息,并将其报告给发送方控制器。
8、RTCP receiver at RTP receiver:从发件人处接收发件人报告。
9、Loss-based controller:基于丢包的控制器,获取丢失率测量、往返时间测量和REMB消息,并计算目标发送比特率。
10、Delay-based controller:基于延迟的控制器,在RTP接收器处或从RTP发送方接收的反馈中获取数据包到达信息,并计算其传递给基于丢包的控制器的最大比特率。
基于丢包的控制器和基于延迟的控制器共同实现了拥塞控制算法。
反馈和扩展
实现该算法有两种方法。一种是两个控制器都在发送端运行;一种是基于延迟的控制器在接收端运行,基于丢包的控制器在发送端运行。
第一个版本可以通过使用如[I-D.holmer-rmcat-transport-wide-cc-extensions]中所述的每包反馈协议来实现。这里,RTP接收器将记录每个接收到的数据包的到达时间和传输范围序列号,这些数据包将使用传输范围的反馈消息定期发送回发送方。建议的反馈间隔为每接收一个视频帧一次,或者如果仅音频或多流,则至少每30毫秒一次。如果需要限制反馈开销,该间隔可以增加到100毫秒。
发送方将收到的{sequence number,arrival time}对映射到反馈报告覆盖的每个数据包的发送时间,并将这些时间戳提供给基于延迟的控制器。它还将根据反馈消息中的序列号计算丢包率。
第二个版本可以通过在接收端使用基于延迟的控制器来实现,监控和处理传入数据包的到达时间和大小。发送方应使用abs发送时间RTP报头扩展[abs-send-time],使接收方能够计算组间延迟变化。基于延迟的控制器的输出将是比特率,该比特率将使用REMB反馈消息[I-D.alvestrand-rmcat-REMB]发送回发送方。丢包率通过RTCP接收器报告发回。在发送方,REMB消息中的比特率和丢失的数据包部分被送入基于丢包的控制器,该控制器输出最终目标比特率。建议在检测到拥塞时立即发送REMB消息,否则至少每秒发送一次。
发送引擎
pacing被用于启动控制器计算的目标比特率。
当媒体编码器产生数据时,这些数据被送入Pacer队列。Pacer在每个burst_time间隔向网络发送一组数据包。burst_time的建议值为5 ms。一组数据包的大小计算为目标比特率和burst_time之间的乘积。
基于延迟的控制
基于延迟的控制算法可以进一步分解为四个部分:预滤波、到达时间滤波器、过载使用检测器和速率控制器。
到达时间模型
本节描述了一种自适应滤波器,该滤波器基于接收到的数据包分组的时间来不断更新网络参数的估计值。
我们将到达时间t(i)-t(i-1)定义为两组数据包到达时间的差。相应地,间隔发送时间T(i)-T(i-1)被定义为两组分组的发送时间的差。最后,群间延迟变化d(i)被定义为到达时间和发送时间之间的差值。或以不同的方式解释,如i组和i-1组延迟之间的差异。
d(i) = t(i) - t(i-1) - (T(i) - T(i-1))
连续组之间的间隔发送时间被计算为T(i)-T(i-1),其中T(i)是正在处理的当前分组组中最后一个分组的发送时间戳。到达时间模型会忽略任何无序接收的数据包。
每个组被分配一个接收时间t(i),它对应于组的最后一个分组被接收的时间。如果t(i)-t(i-1)>T(i)-T(i-1),也就是说,如果到达间隔时间大于发送间隔时间,则一个组相对于它的前一个组是被延迟的。
我们可以将组间延迟变化建模为:d(i) = w(i)
这里,w(i)是随机过程w的样本,它是链路容量、当前交叉流量和当前发送比特率的函数。我们将W建模为一个白高斯过程。如果我们过度使用信道,我们期望w(i)的平均值增加,如果网络路径上的队列被清空,w(i)的平均值将减少;否则,w(i)的平均值将为零。
将平均值m(i)从w(i)中取出来,使过程的平均值为零,我们得到方程式:
d(i) = m(i) + v(i)
噪声项v(i)表示网络抖动和模型未捕捉到的其他延迟效应。
预滤波
预滤波旨在处理由通道中断引起的延迟瞬变。在中断期间,由于与拥塞无关的原因而在网络缓冲区中排队的数据包在中断结束时以突发方式发送。
预过滤将突发到达的分组合并在一起。如果以下两种情况之一成立,则数据包将合并到同一组中:
1、在突发时间间隔内发送的数据包序列构成一个组。
2、到达时间小于突发时间(小于5ms),并且组间延迟变化d(i)小于0的分组被认为是当前分组组的一部分。
到达时间滤波器
参数d(i)可随时用于每组分组(i>1)。我们想要估计m(i),并使用该估计来检测瓶颈链路是否被过度使用。该参数可以通过任何自适应滤波器进行估计——我们使用的是卡尔曼滤波器。
设m(i)为时间=i的估计值。
我们将从时间i到时间i+1的状态演化建模为:
m(i+1) = m(i) + u(i)
其中,u(i)是状态噪声,我们建模为均值和方差均为零的高斯统计平稳过程。
q(i) = E{u(i)^2}
建议q(i)等于10^-3
给定方程式1,我们得到:
d(i) = m(i) + v(i)
其中,v(i)是方差var_v=E{v(i)^2}的零均值高斯白测量噪声。
卡尔曼滤波器递归地更新我们的估计m_hat(i)为:
z(i) = d(i) - m_hat(i-1)
m_hat(i) = m_hat(i-1) + z(i) * k(i)
e(i-1) + q(i)
k(i) = ----------------------------------------
var_v_hat(i) + (e(i-1) + q(i))
e(i) = (1 - k(i)) * (e(i-1) + q(i))
方差var_v(i)=E{v(i)^2}使用指数平均滤波器估计,该滤波器针对可变采样率进行了修改
var_v_hat(i) = max(alpha * var_v_hat(i-1) + (1-alpha) * z(i)^2, 1)
alpha = (1-chi)^(30/(1000 * f_max))
其中f_max=max{1/(T(j)-T(j-1))}对于j是i-K+1...i之间接收到最后K个数据包组的最高速率,chi是通常选择为区间[0.1,0.001]中的数字的过滤系数。由于我们假设v(i)应为零,因此在某些情况下,WGN的平均值不太准确,我们在var_v_hat的更新中引入了额外的异常值过滤器。如果z(i)>3*sqrt(var_v_hat),则过滤器将更新为3*sqrt(var_v_hat)而不是z(i)。例如,在包以高于信道容量的速率发送的情况下,v(i)将不会是空白的,在这种情况下,它们将在彼此后面排队。
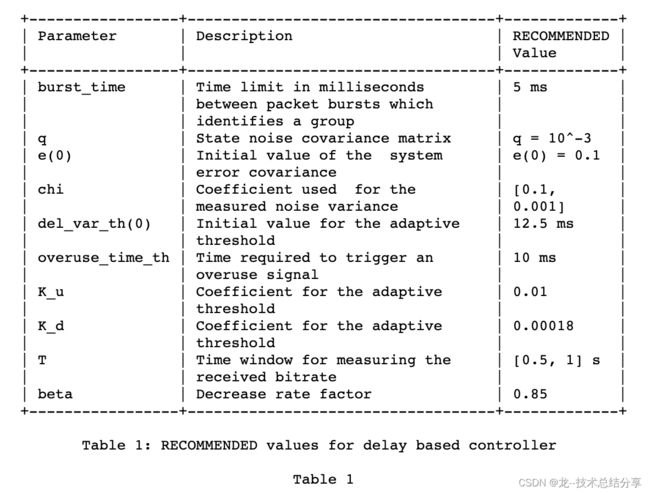
过载检测
将作为到达时间滤波器输出的群间延迟变化估计m(i)与阈值del_var_th(i)进行比较。超过阈值的估计值被视为过度使用的迹象。这种指示不足以让探测器向速率控制子系统发出过度使用的信号。只有在检测到过度使用的时间至少超过overuse_time_th毫秒时,才会发出确定的过度使用信号。然而,如果m(i) 阈值del_var_th对算法的整体动态和性能有显著影响。特别是,已经证明,使用静态阈值del_var_th,由该算法控制的流可以被并发TCP流导致饥饿状态[Pv13]。通过将阈值del_var_th增加到足够大的值,可以避免这种饥饿。 原因是,通过使用较大的del_var_th值,可以容忍较大的排队延迟,而对于较小的del_var_th值,过载检测器通过生成过度使用信号,减少基于延迟的可用带宽a_hat估计值,从而对偏移估计值m(i)的小幅增加做出快速反应(见第4.4节)。因此,有必要动态调整阈值del_var_th,以便在最常见的场景中获得良好的性能,例如在与基于丢包的流竞争时。 因此,我们建议根据以下动力学方程改变阈值del_var_th(i): del_var_th(i) = del_var_th(i-1) + (t(i)-t(i-1)) * K(i) * (|m(i)|-del_var_th(i-1)) 如果| m(i)| |m(i)| - del_var_th(i) > 15 还建议将del_var_th(i)钳制在[6, 600]范围内,因为太小的del_var_th(i)会导致探测器变得过于敏感。 另一方面,当m(i)回落到范围[-del_var_th(i-1),del_var_th(i-1)]时,阈值del_var_th(i)减小,从而可以实现更低的排队延迟. 建议选择K_>K_d,以使del_var_th增加的速率高于其减少的速率。通过此设置,可以在并发TCP流的情况下提高阈值,防止饥饿,并强制协议内公平性。del_var_th(0)、overuse_time_th、K_u和K_d的建议值分别为12.5 ms、10 ms、0.01和0.00018。 速率控制 速率控制分为两部分,一部分控制基于延迟的带宽估计,另一部分控制基于损耗的带宽估计。这两种方法都旨在增加对可用带宽的估计,只要没有检测到拥塞,并确保我们最终将匹配信道的可用带宽,并检测过度使用。 一旦检测到过度使用,基于延迟的控制器估计的可用带宽就会减少。通过这种方式,我们可以得到可用带宽的递归和自适应估计。 在本文中,我们假设速率控制子系统是周期性执行的,并且这个周期是恒定的。 速率控制子系统有三种状态:增加、减少和保持。“增加”是未检测到拥塞时的状态;“减少”是指检测到拥塞的状态,“保持”是指等待已建立的队列耗尽后再进入“增加”状态的状态。 状态转换(空白字段表示“保持状态”)为: 子系统启动时是在增加状态,直到探测器子系统检测到过度使用或不足为止。在每次更新时,基于延迟的可用带宽估计都会根据其当前状态成倍或累加地增加。 如果当前带宽估计似乎远未收敛,则系统会成倍增加,而如果似乎更接近收敛,则系统会线性增加。如果当前传入比特率R_hat(i)接近于我们之前处于下降状态时传入比特率的平均值,我们假设我们接近收敛。“接近”定义为围绕该平均值的三个标准差。建议使用平滑因子为0.95的指数移动平均值测量该平均值和标准偏差,因为预计该平均值涵盖了我们处于下降状态的多个情况。当这些统计数据的有效估计不可用时,我们假设我们尚未接近收敛,因此仍处于乘法递增状态。 如果R_hat(i)增加到平均最大比特率的三个标准偏差以上,我们假设当前拥塞水平已经改变,此时我们重置平均最大比特率并返回乘法增加状态。 R_hat(i)是基于延迟的控制器在T秒窗口内测量的输入比特率: R_hat(i) = 1/T * sum(L(j)) for j from 1 to N(i) N(i)是过去T秒内接收到的数据包数量,L(j)是数据包j的有效载荷大小。建议在0.5到1秒之间设置一个窗口。 在乘法增加期间,估计值每秒最多增加8%。 eta = 1.08^min(time_since_last_update_ms / 1000, 1.0) A_hat(i) = eta * A_hat(i-1) 在加法增加期间,每个响应时间间隔最多增加半个数据包。响应时间间隔估计为往返时间加上100 ms,作为过度使用估计器和检测器反应时间的估计。 response_time_ms = 100 + rtt_ms alpha = 0.5 * min(time_since_last_update_ms / response_time_ms, 1.0) A_hat(i) = A_hat(i-1) + max(1000, alpha * expected_packet_size_bits) expected_packet_size_bits用于在较低的比特率下获得稍微较慢的斜率。例如,可以通过假设每秒30帧的帧速率从当前比特率计算: bits_per_frame = A_hat(i-1) / 30 packets_per_frame = ceil(bits_per_frame / (1200 * 8)) avg_packet_size_bits = bits_per_frame / packets_per_frame 由于系统依赖于过度使用信道来验证当前可用带宽估计,我们必须确保我们的估计不会偏离发送方实际发送的速率。因此,如果发送方无法产生具有拥塞控制器要求的比特率的比特流,可用带宽估计值应保持在给定范围内。因此,我们引入了一个阈值 A_hat(i) < 1.5 * R_hat(i) 当检测到过度使用时,系统将转换到减少状态,在此状态下,基于延迟的可用带宽估计将减少到当前输入比特率的一倍。 A_hat(i) = beta * R_hat(i) beta通常选择在区间[0.8,0.95]内,建议值为0.85。 当探测器向速率控制子系统发送正在使用的信号时,我们知道网络路径中的队列正在清空,这表明我们的可用带宽估计值低于实际可用带宽。收到该信号后,速率控制子系统将进入保持状态,在该状态下,接收端可用带宽估计值将保持不变,同时等待队列稳定在较低水平,这是一种尽可能降低延迟的方法。这种延迟的减少是需要的,也是预期的,在估计值由于过度使用而减少之后,但是如果某些链路上的交叉流量减少,也可能发生这种情况。 建议每个响应时间间隔至少运行一次更新A_hat(i)的例程。 参数设置 基于丢包的控制 拥塞控制器的第二部分基于从延迟控制器接收到的往返时间、分组丢失和可用带宽估计来做出决策。基于丢包的控制器计算的可用带宽估计值用As_hat表示。 只有当路径上的队列足够大时,基于延迟的控制器产生的可用带宽估计才是可靠的。如果队列很短,过载只会通过丢包来判断,而基于延迟的控制器不会使用丢包判断。 每次接收到来自接收器的反馈时,基于丢包的控制器都应运行。 1、如果自上一次来自接收方的报告以来,有2-10%的数据包丢失,则发送方可用带宽估计值(i)将保持不变。 2、如果超过10%的数据包丢失,则新的估计值计算为as_hat(i)=as_hat(i-1)*(1-0.5p),其中p是丢失率。 3、只要丢失的数据包少于2%,As_hat(i)将增加为As_hat(i)=1.05 *(As_hat(i-1)) 将基于丢包的估计值与基于延迟的估计值进行比较。实际发送速率设置为as_hat和A_hat之间的最小值。 我们注意到,如果传输信道由于过度使用而有少量数据包丢失,那么如果发送方不调整其比特率,该数据包丢失量将很快增加,从而激发数据包丢失阈值。因此,我们将很快达到10%以上的阈值,并按(i)进行调整。然而,如果数据包丢失率没有增加,那么丢失可能与自身造成的拥塞无关,因此我们不应该对它们做出反应。 互操作性考虑 如果实现这些算法的发送方与未实现任何拟议RTCP消息和RTP报头扩展的接收方对话,建议发送方监控RTCP接收方报告,并使用丢失数据包的分数和往返时间作为基于丢失的控制器的输入。基于延迟的控制器应保持禁用状态。 实施经验 该算法已在开源WebRTC项目中实现,从M23开始在Chrome中使用,并被Google Hangouts使用。 该算法的部署揭示了与拥挤或其他问题WiFi网络相关的问题,这些问题导致了算法的改进。该算法也在多方会议场景中进行了测试,会议服务器终止了端点之间的拥塞控制。这确保了拥塞控制不会对最大发送和接收比特率等做出任何假设,这通常是会议服务器无法控制的。 未来展望 该草案作为拥塞控制讨论的输入。 在此基础上可以完成的工作包括: 1、综合丢包控制的考虑因素:如何更好地整合丢包和延迟控制,并改进丢包控制。 2、对控制点的考虑:与发送方和接收方之间的分离逻辑相比,评估在发送方拥有所有拥塞控制逻辑的性能。 3、考虑将ECN用作拥塞估计和链路过度使用检测的信号。