ACL2023:Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
1. 简介
论文题目:Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
论文来源:ACL2023 Findings
论文链接:https://aclanthology.org/2023.findings-acl.817
代码链接:https://github.com/LWL-cpu/SCPRG-master
1.1 Motivation
大多数先前的工作都侧重于捕捉每个事件中候选论点与事件触发器之间的关系,忽略了两个关键点:1)非参数上下文线索信息;2) 论证参数之间的相关性。
1)非参数上下文线索信息
非参数线索是除目标参数外的上下文文本,可以为预测许多复杂的参数角色提供重要的指导信息。例如,在图1中,对于*“冲突和袭击”事件,非参数线索“被引爆”、“索赔责任”和“恐怖袭击”*可以为识别参数爆炸带和伊斯兰国提供重要的线索信息。同样,对于暴力词汇死亡事件和审判,弗雷迪·格雷和小凯撒·古德森警官分别为预测受害者和凶手的角色提供了重要的指导信息。
然而,以前的许多工作只使用预先训练的基于转换器的编码器来隐式地获取全局上下文信息,而忽略了对于事件中出现的不同自变量,他们应该关注与实体甚至目标高度相关的上下文信息。因此
在本文中,我们设计了一个STCP模块,该模块基于预先训练的模型中的上下文注意力乘积,将每个自变量触发对的非自变量线索的信息合并,用额外的相关上下文信息增强候选自变量的表示。
2)参数角色之间的相关性
一些参数角色具有密切的语义相关性,这有利于参数的提取。例如,在图1中,角色伤害者和\textit{受害者之间存在密切的语义相关性,这可以为这两个角色在目标事件冲突和攻击中的参数提取提供重要的信息指导。此外,许多角色共同出现在多个事件中,这可能具有密切的语义相关性。具体而言,我们统计并可视化了RAMS数据集中15个最常见角色之间的共现频率,如图2所示。例如,角色attender、target 经常同时出现,这表明它们在语义上比其他角色更相关。在本文中,我们提出了一个基于角色的RLIG模块,该模块由角色交互编码和角色信息融合组成。具体来说,我们设计了一个角色交互编码器,将角色添加到输入序列中,其中角色嵌入不仅可以学习角色的潜在语义信息,还可以捕捉角色之间的语义相关性。然后,通过池化和串联操作将潜在的角色嵌入合并到候选参数中,为文档级EAE提供信息指导。

1.2 Contriburion
- 我们提出了一个基于跨度触发的上下文池模块,该模块自适应地选择和聚合非自变量线索的信息,用相关的上下文信息增强候选自变量的表示。
- 我们提出了一个基于角色的潜在信息引导模块,该模块提供了包含角色之间语义相关性的潜在角色信息引导。
- 扩展实验表明SCPRG的性能优于以前的在公共RAMS和WikiEvents数据集上进行了1.13 F1和2.64 F1改进。我们进一步分析了注意力权重和潜在角色表征,这表明了我们模型的可解释性。
2. 方法
SCPRG的主要架构如图3所示。带有角色的输入序列被馈送到角色交互编码器中,上下文表示、角色表示和注意力头作为输出。STCP基于触发器和自变量之间的注意力乘积,将非自变量上下文线索自适应地融合到上下文向量中。RLIG通过角色交互编码构建潜在角色嵌入,并通过池化操作将其融合为潜在角色向量。上下文向量和潜在角色向量被合并到最终跨度表示和分类模块中预测所有候选跨度的参数角色。
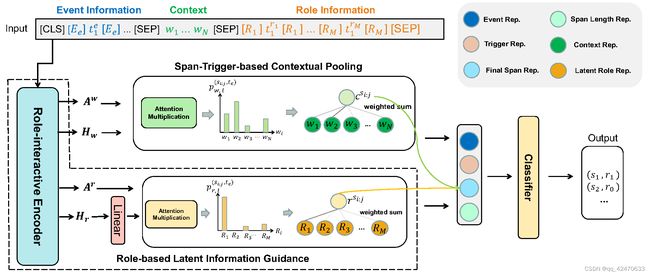
3. 实验
3.1 数据集
我们在两个大型公共文件级别上对所提出的模型进行了评估,RAMSv1.0和WikiEvents数据集。其详细数据统计如表1所示。我们报告了RAMS数据集的开发和测试集上的 Span F1和 Head F1。Span
F1要求预测的自变量跨度完全匹配金色的,而Head F1仅根据头部单词\脚注进行评估跨度的头部单词被定义为弧距最小的单词到依赖关系树的根。此外,对于WikiEvents数据集,我们分别报告了自变量识别任务(Arg-IF)和自变量分类任务(Arg-CF)的Head F1和Coref F1在测试集上的得分。Coref F1评估提取的自变量和黄金自变量之间的共引用,并且如果提取的自变量与黄金自变量共引用,则该模型实现Coref F1。

3.2 基线模型选择
我们比较了不同类别的文档级EAE模型,这些模型主要由基于标记的方法组成,如BERT-CRF、BERT-CRF-TCD,以及其他基于生成的方法,如FEAE、BERT-QA和 BART Gen、TSAR 、EAE。此外,我们使用BERT-base和BERT-large作为预训练的基于转换器的编码器。
3.3 基本实验结果
表2显示了RAMS数据集中dev和测试集的实验结果。与以前的基于标记和基于跨度的方法(如BERT-CRF和Two Step)相比,我们的SCPRG配备了BERTbase,在开发/测试集上产生了+8.46/+9.64~+6.36/+7.14的Span F1和+7.68/+9.00~+5.38/+6.40的Head F1的改进,表明我们的SCPR G框架在排除不可能的候选跨度和解决数据分布不平衡问题方面具有优势。值得注意的是,配备RoBERTalarge的SCPRG也优于以前最先进的模型。BART-Genlarge(试验台上为+3.68/+2.34Span/Head F1)和TSALarge(+1.14/+1.13Span/Head F1.)。这些结果证明了我们的模型优越的提取能力,得益于上下文线索信息和具有语义相关性的潜在角色表示的效果。此外,我们在WikiEvents上进一步验证了我们的SCPRG,并在具有基本和大型预训练模型的任务中实现了最先进的性能,如表3所示。我们的SCPRG优于以前的竞争方法,如TSAR和EA2E。与TSALarge相比,我们的SCPRG在测试集上的参数识别方面提高了+0.64/+0.58 Head/Coref F1,在参数分类方面提高了+1.22/+1.29 Head-Coref F1。此外,SCPRG在自变量识别方面也优于最近的基于竞争生成的方法EA2Elarge
(+2.64/+0.33 Head/Coref F1)和参数分类(+2.31/+0.38 Head/Coreff F1)任务。这些实验改进证明了我们的框架与论点事件特定的上下文信息相融合的巨大优势,以及潜在角色信息的有用指导。


3.4 消融实验
为了更好地说明我们组件的功能,我们对RAMS数据集进行了消融研究,如表4所示。我们还提供消融研究表5中的WikiEvents数据集上的结果。首先,当我们删除基于跨度触发的上下文池(STCP)模块时,SCPRGbase/SCPRGlasge的跨度F1和头部F1在测试集中的得分分别下降了1.61/1.43和1.42/2.09,这表明我们的STCP在捕捉对于文档级EAE至关重要的非参数上下文的线索信息。此外,在删除基于角色的潜在信息制导(RLIG)模块5,SCPRGbase/SCPRGlasge在RAMS测试台上的性能急剧下降1.03/1.04跨F1和1.58/1.2头F1。这表明,我们的RLIG模块通过包含角色之间语义相关性的有意义的潜在角色表示来有效地指导论点提取。当移除STCP和RLIG模块时,性能衰减超过移除单个模块时的衰减,这说明我们的两个模块可以协同工作以提高性能。此外,当移除参数不可能跨度排除(ASE)操作时,SCPRGbase和SCPRGlarge都具有性能衰减,这表明排除参数不可能候选跨度消除了噪声信息,并有助于参数提取。焦点丢失有助于平衡正样本和负样本的表示,有助于模型在训练过程中的平滑收敛。但是,这并不能提高模型的性能。


3.5 分析
1)对上下文注意力权重的分析
为了评估STCP在为候选论点捕获有用的上下文信息方面的有效性,我们将上下文权重可视化。如图5所示,我们的STCP对攻击、责任和恐怖袭击,其中最相关的是跨度触发器对(伊斯兰国,受伤)。有趣的是,我们的STCP也给予了相对较高的关注与其他论点中的单词(如爆炸性的、数十个和喀布尔)相比,这意味着这些论点单词为伊斯兰国的角色预测。可视化表明,我们的STCP不仅可以捕获相关的非论证线索信息对候选跨度进行建模,但对事件中相关参数之间的信息交互进行建模。此外,我们还探讨了一个事件中基于不同跨度触发对的注意力权重。在图4中,我们在一个事件中随机选择30个候选跨度,并根据他们的注意力与上下文有关。热图显示,不同的候选自变量关注不同的上下文信息,表明我们的STCP可以根据候选自变量跨度自适应地选择上下文信息。


2)对上下文注意力权重的分析
为了验证我们的模型能够捕捉角色之间的语义相关性,我们可视化了两个潜在角色表示之间的余弦相似性。图6中RAMS数据集中的事件。如图所示,角色来源和目的地、攻击者和目标具有相似的表示,这是一致的。通过它们的语义,证明我们的模型可以捕捉角色之间的语义相关性。此外,为了验证角色表征的有益指导,我们展示了属于两个不同角色的论点的t-SNE(van der Maaten和Hinton,2008)可视化,这两个不同的角色同时出现在5个不同的文档中,以及相应的潜在角色嵌入。如图7a所示,属于不同文档中的角色由于其不同的目标事件和上下文而分散在整个嵌入空间中。值得注意的是,融合了潜在的角色嵌入,在图7b中,属于受害者或地点的论点的表示更为相邻,这说明我们的RLIG提供了有效的社会潜角色信息引导。


3.6 参数量和复杂性分析
SCPRG是文档级EAE的一个简单但有效的框架,其中STCP和RLIG引入的参数很少。具体而言,STCP利用了来自预训练编码器的学习良好的注意力头,并进行乘法和归一化运算,如表4所示,这只引入了约0.28%的新参数。我们的RLIG在角色嵌入层6和特征融合中只引入了约0.3%的新参数层这使得我们的模型的参数量近似于基于变换器的编码器加上MLP分类器。
4. 局限性
尽管我们的实验证明了我们的SCPRG模型的优越性,但它仅适用于具有已知事件触发器的文档级EAE任务,因为STCP和RLIG都计算触发器和候选跨度的注意力乘积。然而,在现实场景中,事件触发器并不总是可用的。针对这个问题,我们有了初步的解决方案,并计划在下一步工作中改进我们的模型。我们方法的核心思想是基于候选论点和目标事件来选择和集成上下文和角色信息。基于这一思想,我们简要地为上述限制提供了两种解决方案。首先,我们可以使模型预测最佳候选触发词。其次,我们可以用特殊的事件标记替换触发词。在接下来的工作中,我们计划将我们的模型扩展到没有触发词的文档级EAE任务,并通过广泛的实验对其进行评估。
5. 结论
在本文中,我们提出了一种新的用于文档级EAE的SCPRG框架,该框架主要由两个紧凑、有效且可移植的模块组成。具体来说,我们的STCP自适应地聚合了非论证线索词的信息,RLIG提供了潜在的作用包含角色之间语义相关性的信息指导。实验结果表明,SCPRG的性能优于现有最先进的EAE模型和进一步的分析表明,我们的方法有效且可解释。对于在未来的工作中,我们希望将SCPRG应用于更多的信息提取任务,例如作为关系提取和多语言提取,其中上下文信息起着重要作用。