【附代码】Pandas的groupby加速(sort+numpy)
文章目录
-
- 相关文献
- 测试电脑配置
- Pandas的groupby在重复率不同数据中的表现
-
- 重复数量<=10:
- 重复数量<=100:
- 重复数量<=1000:
- 重复数量<=10000:
- 代码
- 总结
作者:小猪快跑
基础数学&计算数学,从事优化领域5年+,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法
如有错误,欢迎指正。如有更好的算法,也欢迎交流!!!——@小猪快跑
相关文献
- 【附代码】Python函数性能测试(perfplot)-CSDN博客
测试电脑配置
博主三千元电脑的渣渣配置:
CPU model: AMD Ryzen 7 7840HS w/ Radeon 780M Graphics, instruction set [SSE2|AVX|AVX2|AVX512]
Thread count: 8 physical cores, 16 logical processors, using up to 16 threads
Pandas的groupby在重复率不同数据中的表现
在大数据处理中,我们有时候会遇到需要统计比如说每辆车今年违规了多少,但违规是个很低频的数据,也就是说一辆车发生违规的数据条数很少,这时候Pandas的groupby就不太适合了(除非能使用sum这种自带的groupby函数)。
我们具体来看测试结果。
重复数量<=10:

重复数量<=100:
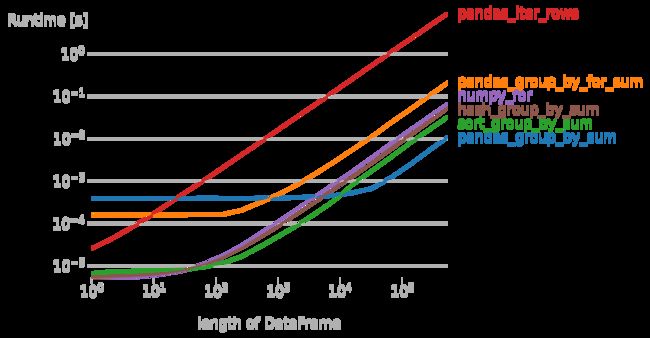
重复数量<=1000:

重复数量<=10000:

代码
from collections import defaultdict
import perfplot
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
def gen_data(m: int, n: int):
tmp = np.zeros(n, dtype=np.int64)
tmp[:n // m * m] = list(range(n // m)) * m
return tmp
def get_input(n, repeat_num):
df = pd.DataFrame()
df['a'] = gen_data(repeat_num, n)
df['b'] = 2
return df
def pandas_iter_rows(df):
res = defaultdict(int)
for i, row in df.iterrows():
res[row['a']] += row['b']
return [[k, v] for k, v in res.items()]
def sort_group_by(df, by, col):
k = df[by].apply(tuple, 1).values if isinstance(by, list) else df[by].values
v = df[col].values
idx = k.argsort()
k_sorted = k[idx]
v_sorted = v[idx]
idx2 = [-1] + np.where(k_sorted[1:] != k_sorted[:-1])[0].tolist() + [len(k_sorted) - 1]
for i, j in zip(idx2[:-1], idx2[1:]):
yield k_sorted[i + 1], v_sorted[i + 1:j + 1]
def hash_group_by(df, by, col):
k = df[by].apply(tuple, 1).values if isinstance(by, list) else df[by].values
v = df[col].values.tolist()
res = defaultdict(list)
for i, j in zip(k, v):
res[i].append(j)
for i, j in res.items():
yield i, j
def numpy_for(df):
res = defaultdict(int)
for a, b in zip(df['a'], df['b']):
res[a] += b
return [[k, v] for k, v in res.items()]
def pandas_group_by_sum(df):
return df.groupby('a').sum()['b'].reset_index().values.tolist()
def pandas_group_by_for_sum(df):
return [[k, v['b'].sum()] for k, v in df.groupby('a')]
def sort_group_by_sum(df):
return [[k, sum(v)] for k, v in sort_group_by(df, 'a', 'b')]
def hash_group_by_sum(df):
return [[k, sum(v)] for k, v in hash_group_by(df, 'a', 'b')]
if __name__ == '__main__':
for i in range(4):
repeat_num = 10 ** (i + 1)
b = perfplot.bench(
setup=lambda n: get_input(n, repeat_num=repeat_num),
kernels=[
pandas_group_by_sum,
pandas_group_by_for_sum,
sort_group_by_sum,
pandas_iter_rows,
numpy_for,
hash_group_by_sum,
],
n_range=[2 ** k for k in range(20)],
xlabel="length of DataFrame",
)
plt.figure(dpi=300)
b.save(f"{repeat_num}.png")
b.show()
总结
尽量不要用df.iterrows(),在数据分类较多的时候,又不能直接使用agg或者自带聚合函数时,pandas groupby效率偏低,更推荐使用
def sort_group_by(df, by, col):
k = df[by].apply(tuple, 1).values if isinstance(by, list) else df[by].values
v = df[col].values
idx = k.argsort()
k_sorted = k[idx]
v_sorted = v[idx]
idx2 = [-1] + np.where(k_sorted[1:] != k_sorted[:-1])[0].tolist() + [len(k_sorted) - 1]
for i, j in zip(idx2[:-1], idx2[1:]):
yield k_sorted[i + 1], v_sorted[i + 1:j + 1]