最简数据挖掘|房租价格预测
目录
一、数据介绍
二、数据统计分析
1、数据基本统计
2、数据缺失统计
3、特征分布统计
4、相关系数矩阵
三、回归模型
划重点
少走10年弯路
一、数据介绍
数据源自最简数据挖掘系列,内容包括位置、出租方式、卧室/客厅/卫生间数量、楼层、面积、装修情况、户型朝向、小区房源情况等等信息,其中包括位置、区、小区名、Label等在内的多个字段都已经过编码/脱敏处理。数据获取见文末

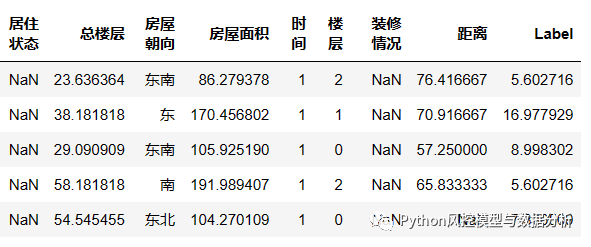
二、数据统计分析
1、数据基本统计
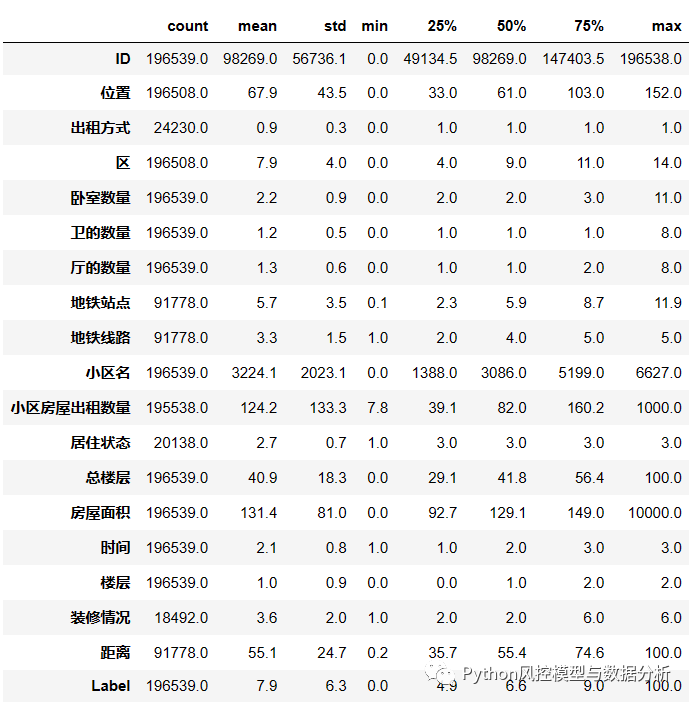
查看整体分布情况
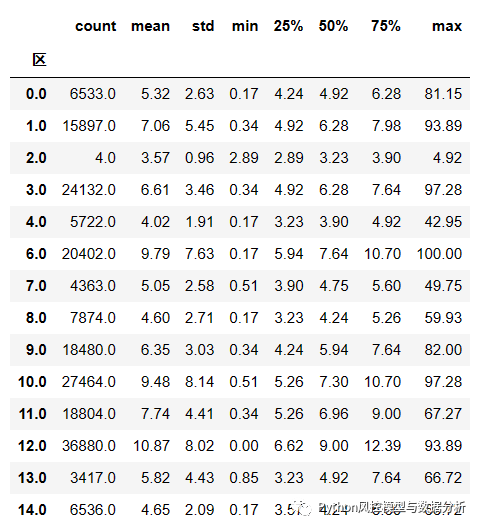
按照所在区分组统计Label(脱敏租金)的分布情况
2、数据缺失统计
缺失率见下图,字段最高缺失率达到90.6%

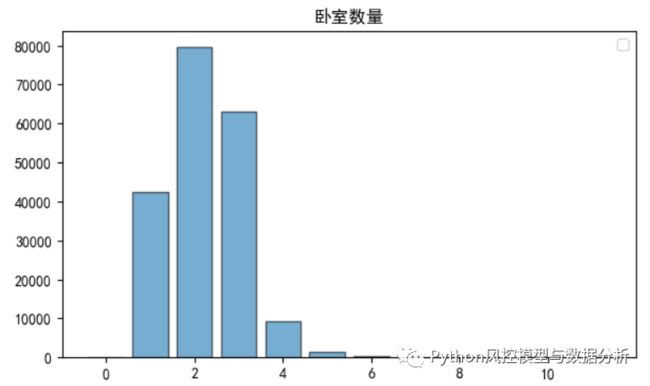
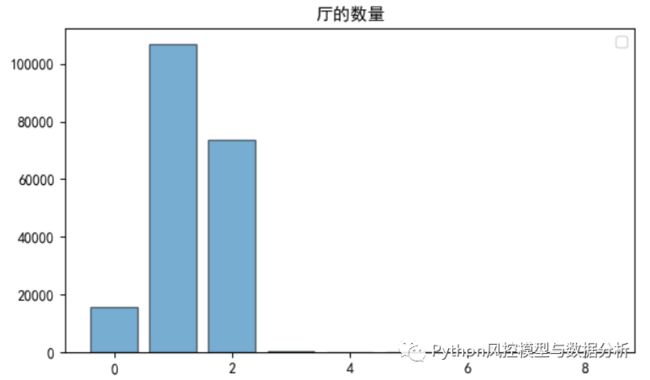
3、特征分布统计
查看各变量的分布情况,以频数分布图来展示
def cate_fea_hist(df,fea):
tmp=df[fea].value_counts().sort_index()
x=list(tmp.index)
y=list(tmp.values)
plt.figure(figsize=(7,4), dpi= 100)
plt.bar(x,y,alpha=0.6,edgecolor = 'k')
plt.title(fea)
plt.legend()
plt.show()
cate_fea_hist(df,'区')

4、相关系数矩阵
如果使用线性回归模型的话,需要考虑特征间的线性相关性/共线性,相关系数矩阵如下
import seaborn as sns
sns.heatmap(df.drop(['ID','小区名', '位置', '区'],axis=1).corr())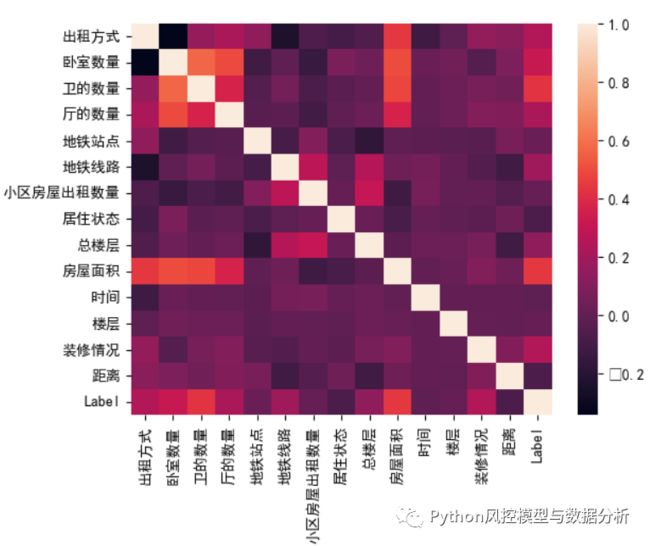
三、回归模型
由于数据中有多列类别型变量是经过编码的、且不知道编码方式,所以选择使用可以处理类别型变量的catboost回归模型,划分训练集、测试集,使用r方进行评估,结果如下
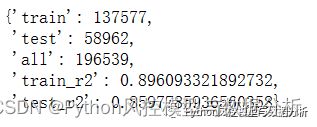
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
def r2_value(y_true,df,model):
y_pred=model.predict(df)
r2=r2_score(y_true, y_pred)
return r2
from catboost import CatBoostRegressor
def init_params_catboost():
params={
'loss_function': 'RMSE', # 损失函数,取值RMSE, Logloss, MAE, CrossEntropy, Quantile, LogLinQuantile, Multiclass, MultiClassOneVsAll, MAPE, Poisson。默认Logloss。
# 'custom_loss': 'F1', # 训练过程中计算显示的损失函数,取值Logloss、CrossEntropy、Precision、Recall、F、F1、BalancedAccuracy、AUC等等
'eval_metric': 'RMSE', # 用于过度拟合检测和最佳模型选择的指标,取值范围同custom_loss
'iterations': 1300, # 最大迭代次数,默认500. 别名:num_boost_round, n_estimators, num_trees
'learning_rate': 0.15, # 学习速率,默认0.03 别名:eta
'random_seed': 123, # 训练的随机种子,别名:random_state
'l2_leaf_reg': 0, # l2正则项,别名:reg_lambda
'bootstrap_type': 'Bernoulli', # 确定抽样时的样本权重,取值Bayesian、Bernoulli(伯努利实验)、MVS(仅支持cpu)、Poisson(仅支持gpu)、No(取值为No时,每棵树为简单随机抽样);默认值GPU下为Bayesian、CPU下为MVS
# 'bagging_temperature': 0, # bootstrap_type=Bayesian时使用,取值为1时采样权重服从指数分布;取值为0时所有采样权重均等于1。取值范围[0,inf),值越大、bagging就越激进
'subsample': 0.6, # 样本采样比率(行采样)
'sampling_frequency': 'PerTree', # 采样频率,取值PerTree(在构建每棵新树之前采样)、PerTreeLevel(默认值,在子树的每次分裂之前采样);仅支持CPU
'use_best_model': True, # 让模型使用效果最优的子树棵树/迭代次数,使用验证集的最优效果对应的迭代次数(eval_metric:评估指标,eval_set:验证集数据),布尔类型可取值0,1(取1时要求设置验证集数据)
'best_model_min_trees': 2000, # 最少子树棵树,和use_best_model一起使用
'depth': 6, # 树深,默认值6
'grow_policy': 'SymmetricTree', # 子树生长策略,取值SymmetricTree(默认值,对称树)、Depthwise(整层生长,同xgb)、Lossguide(叶子结点生长,同lgb)
'min_data_in_leaf': 10, # 叶子结点最小样本量
# 'max_leaves': 12, # 最大叶子结点数量
'one_hot_max_size': 4, # 对唯一值数量划重点
少走10年弯路
关注威信公众号 Python风控模型与数据分析,回复 房租价格预测2 获取本篇数据及代码
还有更多理论、代码分享等你来拿