python实训
一、项目目的与意义
二、项目的内容与操作环境
三、项目实施过程
四、项目总结及收获
一、项目目的与意义
数据采集课程设计是计算机科学与技术专业的一门专业课程,涉及python编程、数据库技术等课程。课程设计的目的是使学生掌握数据采集以及预处理的技术,理解数据采集的原理以及实现,培养学生综合运用所学知识的能力。通过数据采集项目解决实际问题,培养学生严谨的学习态度和良好的学习习惯。
数据采集课程是一门旨在教授如何使用 Python 编写程序来获取、处理和分析数据的课程。该课程将介绍如何使用 Python 编写网络爬虫、解析 HTML 页面、使用数据库存储数据并对数据进行预处理。旨在通过本次课程设计,锻炼学生发现问题、解决问题、综合编程、团队合作等方面的能力,通过案例开发掌握python爬虫基础技术和数据采集以及预处理思路,了侧重实践能力引导和培养。由浅入深的带领学生熟悉数据采集的技术和原理,并辅导学生一步一步的完成项目的开发,学习和提高数据采集和处理能力,提高项目开发能力,注重学生团队意识培养。
二、项目的内容与操作环境
(一)项目内容
本项目的目的是通过使用Python爬虫技术从目标网站上爬取数据,并将数据存储到MySQL数据库中,然后使用Kettle软件对爬取的数据进行处理。通过这个项目,学生可以学习并掌握Python爬虫的基本原理和实现方法,了解MySQL数据库的基本操作和Kettle软件的使用,同时也可以提高学生对数据处理和数据清洗的认识和实践能力。
(二)项目环境
一台PC机,Windows10/11操作系统,Pycharm,JDK8,MySQL数据库,Navicat premium15,kettle
三、项目实施过程
一.基础环境搭建安装
1.python相关库安装
安装爬虫所需的urllib和bs4包
pip install urllib3
pip install beautifulsoup4
安装数据入库所需的包
pip install pymysql
安装数据可视化所需要的包
pip install pyecharts
2. mysql数据库安装
下载安装包
解压压缩包,将my.ini文件放到解压后的目录
命令行窗口下,切换到指定的文件夹下面
安装并启动mysql服务
启动mysql服务,配置远程可连接
用Navicat连接mysql数据库
3. kettle软件安装并连接mysql数据库
解压缩文件pdi-ce-8.2.0.0-342.zip解压完成之后,配置环境变量,环境变量指向Java的安装目录
kettle 连接数据库
mysql-connector-java-8.0.30.jar放在kettle 的lib文件夹下面
修改kettel中的sample-jndi文件夹下的配置文件
修改完成后,采用jndi的方式连接mysql数据库
二.数据采集以及预处理
1.编写代码
python爬虫数据采集,构造请求,使用urllib库
urllib库的主要作用是发送HTTP请求和处理响应。它支持同步和异步两种方式,可以发送GET、POST、PUT、DELETE等HTTP请求,并支持HTTPS协议。urllib库还提供了许多有用的功能,例如URL编码、处理Cookie、处理重定向等。
python爬虫数据采集,解析数据
Beautiful Soup是一个Python库,用于解析HTML和XML文档,包括从网页或其他来源获取内容,并以树形结构组织这些内容,使其可以轻松地通过标签名、属性、ID或搜索等来访问。
Beautiful Soup的主要作用是:
1.解析HTML或XML文档:Beautiful Soup可以将复杂的HTML或XML文档转换成一个复杂的树形结构,每个节点都是Python对象,这样你就可以很方便地查询、修改文档。
2.搜索文档:Beautiful Soup支持在树形文档中进行搜索,可以搜索标签名、属性、文本内容等
数据采集代码如下
#!/usr/bin/env python
# coding: utf-8
# 导入所需库
import csv # 用于 CSV 文件的读写操作
import urllib # 用于 URL 解析
import urllib.request # 用于 HTTP 请求
from time import sleep # 用于添加延迟
from bs4 import BeautifulSoup as bs # 用于解析 HTML
from urllib.parse import urljoin # 用于处理 URL
import pymysql # 用于连接 MySQL 数据库
import random # 用于生成随机数
import time # 用于处理时间
import requests # 用于发送 HTTP 请求
from urllib.request import urlopen, build_opener # 用于构建 HTTP 请求
from urllib.request import Request, HTTPHandler # 用于处理 HTTP 请求
from fake_useragent import UserAgent # 用于生成浏览器 User-Agent
import urllib3 # 用于禁用警告
# 关闭警告
urllib3.disable_warnings()
# 获取代理 IP
def getProxy():
res = requests.get('http://127.0.0.1:5010/get/').json() # 从代理池获取代理 IP
proxies = {}
if res['https']:
proxies['https'] = res['proxy'] # 设置 https 代理
else:
proxies['http'] = res['proxy'] # 设置 http 代理
return proxies # 返回代理 IP 字典
# 获取页面信息
def get_info(page):
sleep(1) # 添加延迟,防止访问过快被封禁
url = 'https://www.cnhnb.com/p/mianfen-0-0-0-0-{}/'.format(page) # 目标网站 URL
proxy_ip = getProxy()['http'] # 使用随机获取的代理 IP
print(proxy_ip)
proxy_handler = urllib.request.ProxyHandler({"http": proxy_ip}) # 构造代理处理器对象
opener = urllib.request.build_opener(proxy_handler, urllib.request.HTTPHandler) # 构造一个自定义的 opener 对象
urllib.request.install_opener(opener)
headers = {} # 构造请求头信息
headers['User-Agent'] = UserAgent().chrome # 设置浏览器 User-Agent
headers['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
############ 需修改为自己的 Cookie
headers['Cookie'] = '' # 添加自己的 Cookie
req = Request(url, headers=headers) # 封装请求
response = opener.open(req) # 使用自定义的 opener 对象发起访问请求
html = urllib.request.urlopen(req)
soup = bs(html.read(), 'html.parser')
lu = soup.find_all('div', class_='show-ctn')
product_all = []
for i in lu:
product_name = i.find('h2').get_text() # 获取产品名称
supplier = i.find("a").get_text() # 获取供应商
supplier_web = i.find("a").attrs['href'] # 获取供应商网址
product_desc = i.find('div', class_='shop-image').img.attrs['alt'] # 获取产品介绍
product_img = i.find('div', class_='shop-image').img.attrs['src'] # 获取产品图片
product_price = str(i.find('div', class_='shops-price').get_text()).strip().replace('\n', '').replace(' ', '') # 获取产品价格
addr = str(i.find('div', class_='r-shop-btm').get_text()) # 获取发货地
mailing_ins = str(i.find('div', class_='cw-tags').get_text()).strip().replace('\n', '').replace(' ', '') # 获取邮寄说明
product = [product_name, supplier, supplier_web, product_desc, product_img, product_price, addr, mailing_ins]
product_all.append(product) # 将提取的信息添加到列表中
return product_all # 返回产品信息列表
# 保存到 MySQL
def save_mysql(all_data):
conn = pymysql.connect(host='127.0.0.1', user='root', port=3306, password='123456', db='mydb', charset='utf8') # 连接 MySQL 数据库
cursor = conn.cursor()
insertsql = 'insert into product_info(product_name,supplier,supplier_web,product_desc,product_img,product_price,addr,mailing_ins) value (%s,%s,%s,%s,%s,%s,%s,%s)' # 插入数据 SQL 语句
for data in all_data:
data = tuple(data)
cursor.execute(insertsql, data) # 执行插入数据操作
conn.commit() # 提交事务
# 主程序入口
if __name__ == '__main__':
lst = [i for i in range(1, 88)] # 生成页面列表
while len(lst) > 0:
for i in lst:
try:
all_data = get_info(i) # 获取页面信息
print(i)
lst.remove(i) # 移除已爬取的页面
save_mysql(all_data) # 保存至 MySQL
except:
pass # 忽略异常
2.登录网站获取获取cookie信息
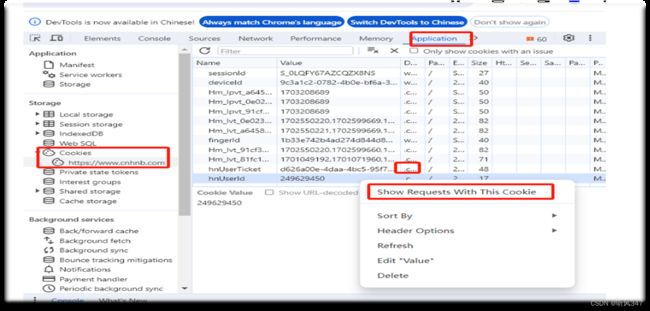
使用chrome浏览器打开惠农网的页面,注册登录之后,按F12
一次选择Application -> Storage -> Cookies -> .c > show Requests With Cookie,获取cookie信息后,将代码中的cookie信息替换掉
二.数据采集以及预处理
3.获取IP代理
有些网站有反爬虫机制,通过代理ip可以绕开限制
1.首先解压proxy_pool-master.zip,解压之后用pycharm打开
2.修改setting.py DB_CONN = 'redis://127.0.0.1:6379/0’
3.安装redis 运行 redis-cli.exe
4.python proxyPool.py schedule
运行时如果报某个库不存在,用pip install 语句安装对应的库就可以
5.python proxyPool.py server
4.使用kettle做数据预处理
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装。它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,功能强大可以对多种数据源进行抽取(Extraction)、加载(Loading)、数据落湖(Data lake Injection)、对数据进行各种清洗(Cleaning)、转换(Transformation)、混合(Blending),并支持多维联机分析处理(OLAP)和数据挖掘(Data mining)
1.安装并打开kettle
2.kettle 连接数据库
3.kettle数据etl处理
3.1数据抽取
3.2数据转换
4.数据转换
4.1数据剔重
4.2缺失值替换
5.数据load(将数据加载到数据库中的新表)
6.查看新表product_info_new中的数据
三.数据可视化
1.编写代码
导入相关库
import pandas as pd # 导入 pandas 库用于数据处理
import pymysql # 导入 pymysql 用于连接 MySQL 数据库
from pyecharts import options as opts # 导入 pyecharts 中的选项模块
from pyecharts.charts import Bar # 导入柱状图模块
from pyecharts.globals import ThemeType # 导入主题类型
连接到 MySQL 数据库
创建游标对象
编写 SQL 查询语句,获取数据
执行 SQL 查询,获取数据并存入 Pandas DataFrame
显示 DataFrame 的前 500 行数据
将 ‘price’ 列转换为浮点型,并筛选出小于 100 的值
按 ‘addr’ 列分组计算 ‘price’ 列的均值,排序并重置索引
提取前 20 个 ‘addr’ 和相应的 ‘price’ 值
定义一个函数,创建带有次级 y 轴的柱状图
渲染柱状图,并将其保存为一个 HTML 文件
数据可视化代码如下
# 导入所需库
import pandas as pd # 导入 pandas 库用于数据处理
import pymysql # 导入 pymysql 用于连接 MySQL 数据库
from pyecharts import options as opts # 导入 pyecharts 中的选项模块
from pyecharts.charts import Bar # 导入柱状图模块
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType # 导入主题类型
import random
# 连接到 MySQL 数据库
db = pymysql.connect(host='127.0.0.1', user='root', port=3306, password='123456', db='mydb', charset='utf8')
# 创建游标对象
cursor = db.cursor()
# 编写 SQL 查询语句,获取数据
sql = '''select addr,replace(product_price,"元/斤","") price
from product_info_new1
where product_price like "%元/斤%"'''
# 执行 SQL 查询,获取数据并存入 Pandas DataFrame
cursor.execute(sql)
data = cursor.fetchall() # 获取所有查询结果
pd.set_option('display.precision', 2) # 设置 pandas 显示精度
df = pd.DataFrame(list(data), columns=['addr', 'price']) # 创建 DataFrame 存储查询结果
# 显示 DataFrame 的前 500 行数据
df.head(500)
# 将 'price' 列转换为浮点型,并筛选出小于 100 的值
df["price"] = pd.to_numeric(df["price"], downcast="float") # 将价格列转换为浮点型
df = df[df.iloc[:, 1] < 100] # 筛选出价格小于 100 的数据
# 按 'addr' 列分组计算 'price' 列的均值,排序并重置索引
price_mean = df.groupby("addr")['price'].mean().sort_values(ascending=False).to_frame() # 按地址分组计算价格均值
price_mean.reset_index(inplace=True) # 重置索引
# 提取前 10 个 'addr' 和相应的 'price' 值
x = list(price_mean['addr'])[0:10] # 获取前 10 个地址数据
y_tmp = list(price_mean['price'])[0:10] # 获取前 10 个价格数据
y = [round(num, 1) for num in y_tmp] # 对价格数据保留一位小数并保存
# 定义一个函数,创建带有次级 y 轴的柱状图
def overlap_bar_line(x, y, title) -> Bar:
# 初始化柱状图,并设置主题为亮色
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
# 设置 x 轴数据
.add_xaxis(x)
# 添加 y 轴数据,并设置柱状图的宽度和样式
.add_yaxis(
"惠农网面粉价格Top10发货地",
y,
bar_width=46,
itemstyle_opts=opts.ItemStyleOpts(
# 设置渐变颜色
color=JsCode(
"""
new echarts.graphic.LinearGradient(0, 0, 0, 1, [
{ offset: 0, color: '#6197EE' },
{ offset: 1, color: '#B7BFE8' }
])
"""
),
# 设置柱状图边框圆角
border_radius=[2, 2, 0, 0],
),
)
# 添加次级 y 轴的设置
.extend_axis(
yaxis=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}"), interval=15
)
)
# 设置柱状图上数据标签样式
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=18, color='black'))
# 设置全局选项
.set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title=title),
# 设置左侧 y 轴选项
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter="{value}", font_size=15)
),
# 设置 x 轴选项
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(
is_show=True, position="top", color="black", rotate=0, interval=0, font_size=15
)
),
)
)
return bar
# 渲染柱状图,并将其保存为一个 HTML 文件
overlap_bar_line(x, y, "").render("C:/Users/LENOVO/Desktop/数据采集课程设计/bar_chart5.html")
2.运行
3.生成结果

四、项目总结及收获
(一)难点问题/关键技术/优势与特色
1.难点问题
Mysql安装后无法连接数据库,通过更改端口成功连接数据库
无法导入UserAgent库,通过手动在pycharm中导入
代理服务器运行时没有定位到相关目录,更改目录后成功运行
数据采集后通过kellte处行预处理时数据库结果一直不变,实际是每次预处理后都会在原来的记录下边生成,通过更改查看记录的范围,找到了原因
数据可视化时无法产生结果,通过渲染柱状图,并将其保存为一个 HTML 文件,成功打开结果
2.关键技术
Python语言编程和应用
Pycharm的安装与使用
JDK8的安装与配置环境变量
MySQL数据库的安装与连接
Navicat premium15的安装,连接与使用
Kettle的安装,配置和使用
数据采集技术,数据预处理技术和数据可视化技术的应用
3.优势与特色
3.1除了使用本地数据库以外,我们还实现了云服务器数据库的配置和连接
配置云服务器
安装centos 系统
配置docker环境
通过docker拉取1panel可视化面板的镜像
通过1panel镜像创建容器
在1panel可视化面板里安装和配置mysql并成功连接
最后成功了实现采集数据到云数据库,预处理云数据库,可视化云服务器数据库数据

3.2通过青龙面板,实现了定期爬取数据和分析数据
通过docker拉取青龙面板镜像
通过青龙面板镜像创建容器并启动
导入数据爬取与可视化代码
添加相关依赖
添加定时任务
查看爬取和可视化结果总结及收获
(二)团队体会与收获
通过团队合作进行基于Python爬虫的数据采集与预处理的设计与实现,我们获得了技术实践的机会,提高了团队协作能力和问题解决能力,加深了对数据质量的认识,并获得了宝贵的学习与成长的机会。这些经验和收获将对我们未来的职业发展产生积极的影响,并为我们在数据领域的探索和进一步学习奠定了坚实基础。