H.264——H.264的基本介绍
目录
- 背景与基本概念
-
- 特点
- H.264的应用场景
- 编码整体架构
-
- 编码结构
- H.264对一个宏块编码
- H.264标准采用的编码工具
-
- 帧内预测
- 帧间预测
- MV的亚像素差值
- 整数变换与量化
- 无损熵编码
- 其他技术
本文是对H.264编码标准研究系列的开端
背景与基本概念
- 发起者:
ITU-T的VCEG(Video Coding Experts Group) - 发起时间:
2003
最初版本支持8bit/sample,4:2:0色度采样,主要针对大部分通用视频处理与传输场合,(#`O′)对特殊应用做处理
特殊应用可能需求:
- 源视频数据精度超过8bit/sample
- 色度采用使用4:2:2或4:4:4
- 超高码率和超高分辨率编码
- 超高保真度,或部分无损编码
为了解决这些专业应用场景的需求,2004年JVT公布:“fidenlily range extension”,即H.264FRExt
特点
同MPEG-4标准关注的灵活性和可交互性不同,H.264专注于采用新技术提高视频信号的编码效率和提高网络传输亲和性(NAL)
H.264的应用场景
- 数字电视广播
- 视频实时通信
- 网络视频流媒体
- DVD视频存储
- 视频点播
编码整体架构

z真题的编码框架方面,H.264依然采用块结构的混合编码框架;整个结构可以分为网络抽象层(NAL)和视频编码成(VCL)
-
首先通过帧内预测,帧间预测获取预测数据。并且对他的残差进行量化操作。(Intra(prediction)、Motion Comp)
-
然后将编码后的语法元素进行熵编码来形成压缩后的码流(Transform/Scaling/Quant)
在编码的过程中,每一帧被分为一个或多个条带(slice)进行编码;每一个条带包含多个宏块(MB,Macroblock)
宏块是H.264编码的基本单元,结构包含一个包含16 x 16亮度快+两个8 x 8色度块+其他一些宏块头信息
编码结构
编码结构大致可以分为两层
- VLC(video coding layer)
帧内预测、运动搜索、运动补偿、变化、量化,都可以归为视频编码层。在整个结构中处于一个比较底层的位置 - NAL(natwork abstract layer)
在slice以上主要考虑的是压缩之后的码流以及更上一层,通常被称作网络抽象层。设置这一层的意义,主要在于提升H.264格式视频对于网络传输和数据存储的亲和性。
简单的理解就是,如果h264是一段代码,VCL是负责视频编码的部分,NAL是负责和网络传输接轨的部分。
再通俗点来说,h264就像是卖产品。VCL是具体的产品,NAL是和快递打交道的部分,快递员会给你一个标准,比如多大的快递箱,放多少减震棉,放哪。
再回到h264,NAL就是为了使得VCL部分更容易被网络解析而存在的。
H.264对一个宏块编码
H.264的宏块编码提供了更加灵活的编码方式
- 每一个宏块会分割成多宗不同大小的子块进行预测
- 相比早期标准只能按照整个宏块或半个宏块进行运动补偿的方法,H.264更细分的宏块分割方式提供了更高的预测精度及编码效率
-
- 帧内预测采用的块大小可能为16x16或4x4(以亮度为例)
-
- 帧间预测/运动补偿采用的块可能有7种不同的形状:16x16、16x8、8x16、8x8、8x4、4x8、4x4
- 针对预测残差数据进行变换编码的变换块大小为4x4或8x8(仅在FRext版本支持)
- 效率更高的熵编码方法:CAVLC和CABAC
H.264标准采用的编码工具
工具主要包括
- 帧内预测
- 帧间预测
- 变换和量化编码
- 无损熵编码
- 其他技术(环路滤波器)
帧内预测
H.264中采用了基于像素块的帧内预测技术,用于降低图像空间内的像素相关性
- 在H.263、MPEG-等前期标准中,帧内预测数据由变换域实现;
- H.264使用空间域的左方与上方的相邻像素预测当前编码的像素值
若H.264的一个宏块为Intra宏块,也就是说这个宏块采用帧内预测进行编码,那么其亮度有两种分割模式:一个16x16像素块或16个4x4像素块
- 对于每个4x4像素块,共定义9种宇哥模式
- 对于16x16像素块,共定义4种预测模式
H.264的一个宏块种包含两个8x8的色度分量,对色度分量定义4种预测模式,同16x16的亮度分量
帧内预测模式如下
以下9种是对4x4的亮度分量进行预测的模式
垂直、水平、均值及6种角度模式模式
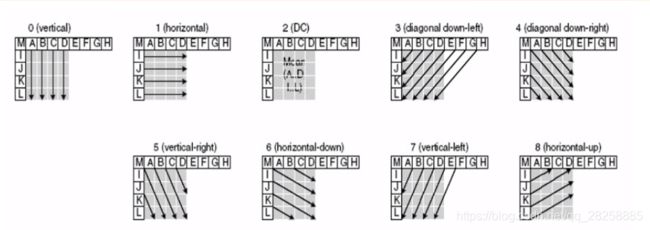
对16x16的亮度块及色度块的预测就比较简单了
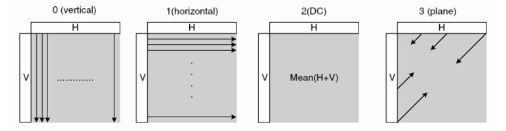
最后一种是平面模式。
如果把整个宏块的像素值看成一个三维的图(类似等高线),那么整个像素块呈或倾斜或水平的平面
也可以这么理解。
圈出的三个点可以确定一个平面。那么这个平面在水平面上的投影的高度(幅度值)就是整个像素块的预测值

帧间预测
H.264采用运动补偿的方式进行帧间编码,消除视频的时间冗余信息
H.264支持的帧间预测类型
- 单项帧间预测: P slice
- 双向帧间预测: B slice
H.264的帧间预测方法类似于H.263等前期标准的方法,在具体的算法上进行了一定的改进
- 更多种的块分割模式:16x16到4x4
- 更高的运动矢量精度:亮度MV可达1/4像素精度
- 支持多个候选参考帧
- 对于交错视频基于帧或者场的运动估计
帧间预测的宏块分割方式

MV的亚像素差值
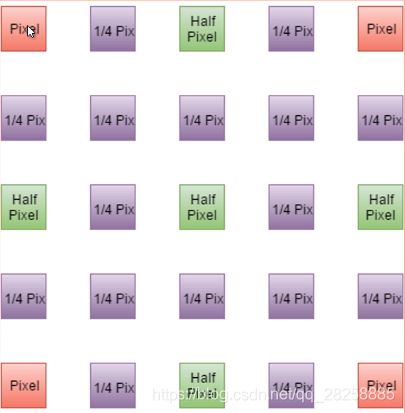
- 红色的块表示整像素的像素点
- 绿色的块是1/2的像素点,对整像素进行差值得到
- 紫色的快是1/4的像素点,绿色像素和红色像素进一步差值得到
由于差值的精度更高,H.264可以获得相对前期标准更为精确的估计值,可以进一步降低运动估计的残差来提高编码效率
整数变换与量化
图像的能量大部分集中在低频区域,将图像变换至频域处理可以减小图像编码的动态范围,有效降低码率
相比于前期编码标准,H.264对图像/残差数据采用4x4的整数DCT变换,在FRExt中,还支持8x8的变换矩阵
H.264的量化方法使用标量量化。在量化/反量化的过程中,量化参数QP决定量化步长的值,QP每增加6,量化步长增加一倍。量化步长越大,编码长度越小,信息损失越大。在H.264中QP可以取0~51。
无损熵编码
熵编码利用信源的统计特性进行编码,在编码过程中无信息损失,即生成的码流可以无失真的恢复出原始数据
所有编码造成的信息损失都是来自于量化这一部分
其他部分不存在信息损失部分
其他很多研究包括图像与视频的无损编码,其中一种比较流行的方式是直接采用量化和熵编码的方式。
经典的熵编码算法
- 哈夫曼编码
- 香浓-费诺编码
H.264正对不同的语法元素制定了不同的熵编码算法
- UVLC(Universal Variabble Length Coding)——主要采用指数哥伦布编码
视频的参数集 - CAVLC(Context Adaptive Variable Length Coding) ——上下文自适应的变长编码
用于预测模式、宏块类型、残差的数据等 - CABAC(Context Adaptive Variable Leng Coding)——上下文自适应的二进制算术编码
其他技术
- 环路去块滤波器
H.264是通过分割宏块进行编码,环路滤波器主要用于消除在这个过程中块的边际效应 - 帧/场编码
- SI/SP帧
- 码率控制