终于理清楚了,k8s服务流转
目录
k8s的service资源类型有ClusterIP、Nodeport、ExternalName、LoadBalancer、Headless(None)
必须了解↓↓↓↓↓↓
1. ClusterIP
是什么
配置服务的会话亲和性
服务发现
2. 就绪探针(readinessProbe)
3. headless
连接集群外部服务的方式:手动配置Endpoint、使用ExternalName 为外部服务创建别名↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1. Endpoint
2. ExternalName
暴露服务的几种方式:Nodeport、LoadBalancer、Ingress↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1. Nodeport
2. loadbalancer
防止不必要的网络跳数
获取客户端IP
3. Ingress
排除服务故障
k8s的service资源类型有ClusterIP、Nodeport、ExternalName、LoadBalancer、Headless(None)
必须了解↓↓↓↓↓↓
1. ClusterIP
是什么
cluster 生成一个虚拟IP,为一组pod提供统一的接入点,当service存在时,它的IP地址和端口不会改变,客户端通过service的ip和端口建立连接,由service将连接路由到该服务的任意一个pod上,通过这种方式,客户端不需要知道每个pod的具体ip,pod可以随时移除或创建,同时实现pod间的负载均衡。
service通过使用标签选择器来指定哪些pod属于同一组。
创建service:
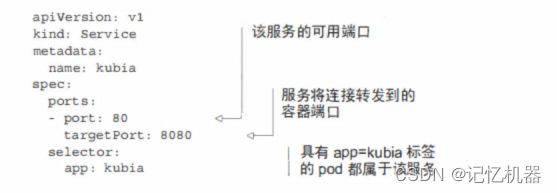
新的服务会分配一个集群内部IP,只能在集群内部访问,服务的主要目标是使集群内其他pod可以访问当前这种pod,但通常也希望对外暴露服务,如何对外暴露,在文章后面有讲解

集群内部服务流转:

配置服务的会话亲和性
同一个客户端向一组pod的服务发起请求,服务每次将请求转发给不同的pod,如果希望特定的客户端产生的所有请求都指向同一个pod,可以设置服务的sessionAffinity属性为ClientIP(而不是None,None是默认值)

这种方式会将来自同一个clientIP的所有请求转发至同一个pod。
k8s仅支持None和ClinetIP两种会话亲和性配置,不支持基于cooki的会话亲和性选项,因为k8s的service不是在http层面工作,服务处理TCP和UDP包,cookie是HTTP协议的内容,所以service并不知道cookie。
同一个服务可以暴露多个端口,暴露多个端口必须为端口指定名字。
服务发现
客户端pod如何知道服务的IP和端口?有两种方式
1. 通过环境变量
当创建一个新pod时,k8s会初始化一系列环境变量给容器,其中包含当前存在的所有服务ip和端口,在任意一个pod容器中执行env命令,可以看到
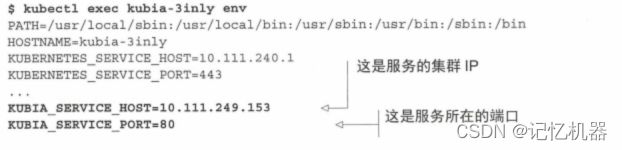
如上图所示,包含一个叫kubia的服务的地址和端口
2. 通过DNS发现服务
k8s的kube-system命名空间下有一个自带的dns服务组件kube-dns,集群中的所有pod都使用它作为dns,在每个容器的/etc/resolv.conf中有配置,所有pod中的进程dns查询都会被这个dns服务器响应,这个服务器知道集群中运行的所有服务。
(pod是否使用内部的dns服务器是根据pod中spec的dnsPolicy属性决定的)
客户端在知道服务名的前提下可以通过全限定域名(FQDN)来访问服务,格式为
{servicename}.{namespace}.svc.cluster.local
例如一个backend服务在default命名空间下,其域名为backend.default.svc,cluster.local,如果是在同一个命名空间下,可以省略命名空间及后面的部分
注意:直接ping service Ip是不通的,这是因为服务的集群IP是一个虚拟IP,并且只有与端口结合时才有意义。
2. 就绪探针(readinessProbe)
我们已经知道pod的标签和服务选择器一样时,pod就会作为服务的后端,但是存在一种情况,pod刚启动时还没有加载好配置,或者需要执行预热防止第一个请求时间过长,这时不想让该pod接收请求。
方案是实用就绪探测器,k8s定期向pod执行探测,发现探测结果成功了才将服务转发过去。
就绪探针有三种类型
Exec探针 :在容器内执行进程,根据进程退出码决定
HTTP GET探针: 向容器发送http get请求,根据返回码决定
TCP socket探针 :向容器指定端口打开TCP连接,如果连接成功,判定为就绪
启动容器后会定期向容器执行探针操作,如果pod报告为尚未就绪,则会从对应的服务中剔除该pod,等下次探测成功后,再将pod添加到endpoints

3. headless
创建服务时默认会生成一个集群IP,客户端无需知道后面有几个pod,但是如果需要具体每一个pod 的IP呢,只需要指定clusterIp为None即可,即headless,headless类型的区别就是不会为服务生成虚拟IP

常规的服务通过DNS服务器获得servicename.namespace.svc.cluster.local的是集群IP,而headless服务获取该域名的实际IP是所有后台pod的IP列表。
从客户端角度来看headless与常规服务并无不同,但是对于headless服务,由于DNS返回了pod的IP,客户端直接连接到pod,而不是通过服务代理。
headless仍然提供跨pod负载均衡,但是是通过DNS轮询机制不是通过服务代理。
连接集群外部服务的方式:手动配置Endpoint、使用ExternalName 为外部服务创建别名↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1. Endpoint
服务service和pod并不是直接相连的,它们之间有个Endpoint资源,Endpoint资源就是一组pod的ip地址和端口的列表,和其他k8s资源一样,可以通过kubectl get endpoints 查看信息。
在Service的spec中定义的pod选择器,不是由服务直接使用,而是用于构建IP和端口列表,然后存储在Endpoint资源中。
如果创建服务时不指定选择器,将不会创建Endpoints(没有选择器不知道服务该包含哪些pod),这样可以分别手动配置它们。

为没有选择器的服务创建Endpoint资源,注意Endpoint是一个独立的资源,并不是Service的属性,由于Service没指定选择器,所以需要手动创建Endpoint

Endpoint对象需要与服务同样的名称,并包含目标IP地址和端口列表,这样服务就可以和有选择器一样正常使用了。将IP配置为外部服务,就可以连接外部服务了

2. ExternalName
创建外部服务的别名,创建service时指定type字段为ExternalName,例如有一个外部服务域名为api.somecompany.com

服务创建后可以通过external-service.defaul.svc.cluster.local 连接外部服务,ExternaleName服务仅在DNS级别实施,为服务创建了简单的CNAME DNS记录,因此,连接到服务的客户端将直接连接到外部服务,完全绕过服务代理。出于这个原因,这些类型的服务不会有集群IP.
CNAME 记录指向完全限定的域名而不是数字IP地址。
暴露服务的几种方式:Nodeport、LoadBalancer、Ingress↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1. Nodeport
创建Servcie时指定type为Nodeport,会在所有集群节点上开一个相同的端口,创建Nodeport时的同时会创建ClusterIP,指定端口不是强制的,如果忽略,集群会自动分配一个
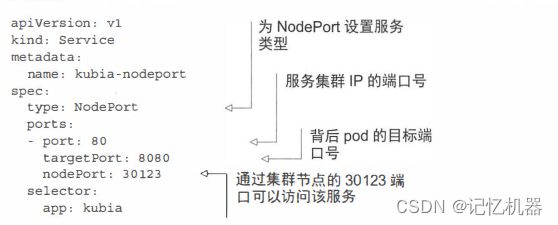
在集群内部可以通过clusterip访问,集群外部通过节点IP:nodeport 访问。到达任何一个节点的连接将会被重定向到一个随机的pod,该pod不一定是位于接收节点的Pod.

如果集群外部的客户端总是指向某个指定节点,那么当这个节点故障时将无法访问,因此节点前面需要一个负载均衡器,以保证发送的请求传播到健康的节点。
2. loadbalancer
负载均衡器

负载均衡器拥有一个可公开访问的IP地址,并将连接重定向到服务。需要注意的是 ,loadbalancer需要额外的基础设施支持,如果环境不支持,则不会调负责均衡器,该服务就像一个Nodeport服务一样了。
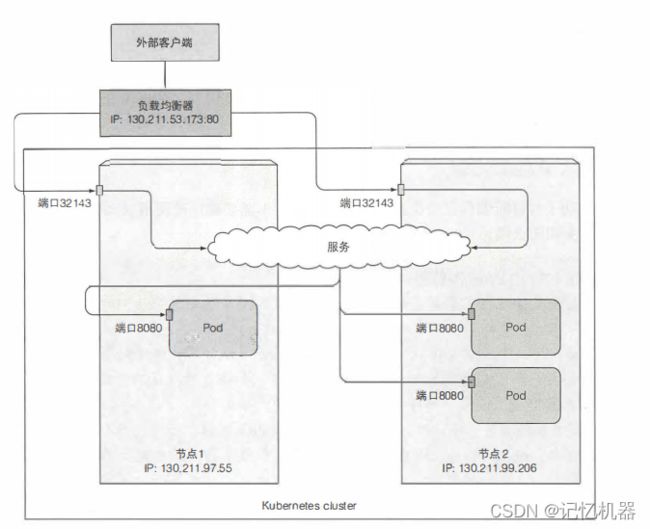
防止不必要的网络跳数
当外部客户端通过节点端口(包括使用负载均衡的情况),随机选择的pod不一定和接收连接在同一个节点,需要额外的网络跳转,可以在服务的sepc中设置亲和性为local避免这种情况

弊端是这样必须要保证节点都有Pod,如果节点没有pod,连接会被挂起。同时会出现pod负载不均衡,如下图

获取客户端IP
在集群内访问服务时,服务端可以获取客户端地址,但是通过节点端口访问时,由于发生了源网络地址转换(SNAT),因此数据包的源IP地址发生了更改。使用上述的Local策略可以保留源IP,因为接收连接的节点和pod节点没有额外的跳跃(不执行SNAT)。
3. Ingress
上文介绍的LoadBalancer需要自己的负载均衡器,以及独有的公网IP地址,而Ingress只需要一个公网IP就能为许多服务提供访问。当客户端向Ingress发送http请求时,Ingress会根据请求的主机名和路径决定要发送的服务。
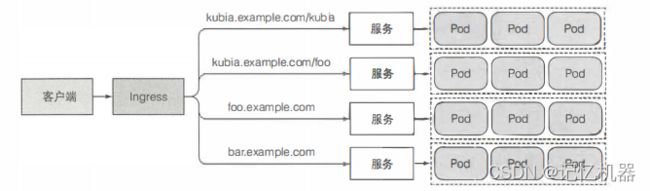
Ingress在应用层工作,可以提供基于cookie的会话亲和性功能。
Ingress必需要Ingress控制器才能运行,不同的k8s环境使用不同的控制器实现,首先要确保环境启用了Ingress控制器。


上图定义了一个单一规则的Ingress,Ingress控制器收到的请求主机kubia.example.com的请求会被发送到kubia-noport服务的80端口。
获取Ingress的IP地址:

配置DNS服务器将kubia.example.com指向得到的IP,或者在客户端 /etc/hosts文件中配置。
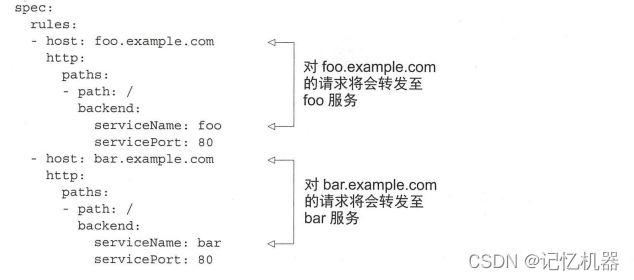
将不同服务映射到同一主机名的不同路径下:

将不同服务映射到不同主机名下:
排除服务故障
服务是k8s的重要概念,也是让许多开发感到困惑的根源。许多开发同学为了弄懂无法通过服务IP或FQDN连接到pod的原因花了大量时间。了解如何排序服务故障是有必要的,如果无法访问pod,排查如下:
- 首先, 确保从集群内连接到服务的集群IP,而不是从外部
- 不要通过ping服务IP 来判断服务是否可访问(请记住,服务的集群IP是虚拟IP, 是无法ping通的)。
- 如果已经定义了就绪探针, 请确保 它返回成功;否则该pod不会成为服务的一部分 。
- 要确认某个容器是服务的一部分, 请使用kubectl get endpoints来检查相应的端点对象。
- 如果尝试通过FQDN或其中一部分来访问服务(例如,myservice.mynamespace.svc.cluster.local或 myservice.mynamespace), 但
并不起作用, 请查看是否可以使用其集群IP而不是FQDN来访问服务 。 - 检查是否连接到服务公开的端口,而不是目标端口 。
- 尝试直接连接到podIP以确认pod正在接收正确端口上的 连接。
- 如果甚至无法通过pod的IP 访问应用, 请确保应用不是仅绑定 到本地主机。