06、全文检索 -- Solr -- Solr 全文检索之在图形界面管理 Core 的 Schema(演示对 普通字段、动态字段、拷贝字段 的添加和删除)
目录
- Solr 全文检索之管理 Schema
-
- 使用Web控制台管理Core的Schema
-
- 3 种 字段解释:
-
- Field:普通字段
- Dynamic Field:动态字段
- Copy Field:拷贝字段
- 演示:添加 普通字段( Field )
- 演示:添加 动态字段( Dynamic Field )
- 删除或修改Field
- 管理 Copy Field(添加和删除拷贝字段)
-
- 1、添加 源field
- 2、删除 源field
- 3、删除拷贝字段
- 4、从 0 添加和删除拷贝字段
-
- 添加:
- 删除:
- 拷贝字段应用场景解释:
Solr 全文检索之管理 Schema
使用Web控制台管理Core的Schema
由于 Core 相当于传统 RDBMS 的一个表(类似关系型数据库的表)。
向 Core 中添加文档时,文档所包含的 Field 应该是 Core 所定义的 Field 的子集。
由于前面创建该 Core 时,以 sample_techproducts_configs 为配置模板的,而该配置模板默认已经定义了大量的 field。
(1)选中指定 Core,然后选择 “Schema” 标签页,进入 Schema 管理界面。
(2)通过该界面可添加 Field:
通过界面添加 Field,其实也是保存在 conf / managed-schema 文档中。
3 种 字段解释:
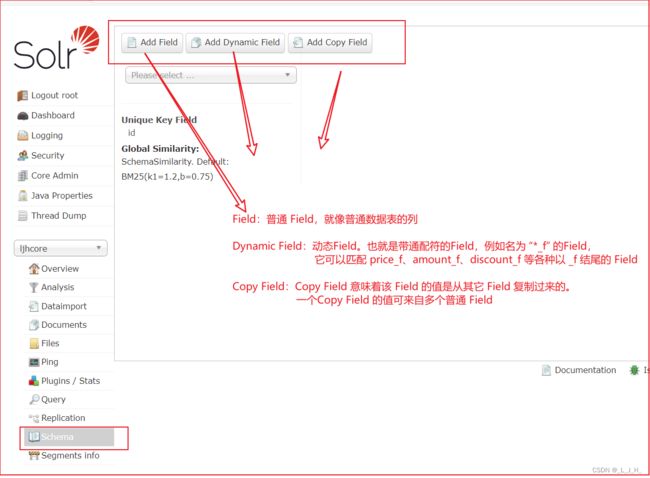
Field:普通字段
Field:普通 Field,就像普通数据表的列。

Dynamic Field:动态字段
Dynamic Field:动态Field。也就是带通配符的Field,例如名为 “*_f” 的Field,
它可以匹配 price_f、amount_f、discount_f 等各种以 _f 结尾的 Field。
由此可见,动态字段是个好东西:通过动态字段,可以让 Core 中有限的字段去匹配所添加文档的无数字段。
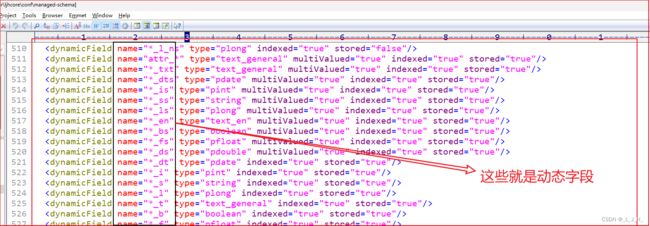
Copy Field:拷贝字段
Copy Field:Copy Field 意味着该 Field 的值是从其它 Field 复制过来的。
一个Copy Field 的值可来自多个普通 Field。
源1 ↘
源2 → Copy Field(目标Field)
源3 ↗
Copy Field,意味着它的值是来自其他普通 Field。
这意味着:** Copy Field 就是 目标field;而其他字段就是源字段。**
如图: text 、manu_exact 、price_c 这些就叫 拷贝字段
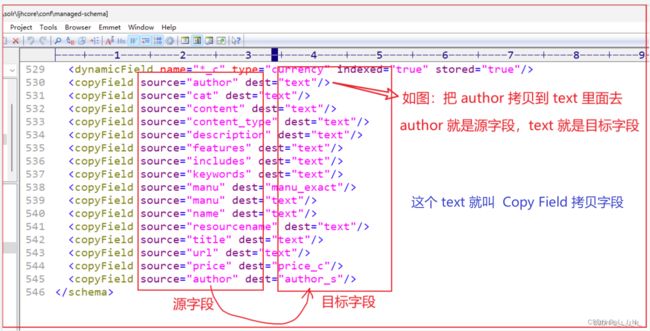
如图,可以看到,其实 拷贝字段中的 目标字段 “text” ,其实它本身也就是一个普通的字段而已。
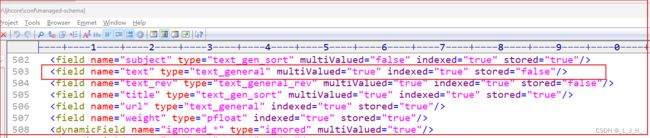
Field管理参考:https://solr.apache.org/guide/8_7/documents-fields-and-schema-design.html
演示:添加 普通字段( Field )
Field:普通 Field,就像普通数据表的列。
如图:
text_ckb 是一种字段的分词类型
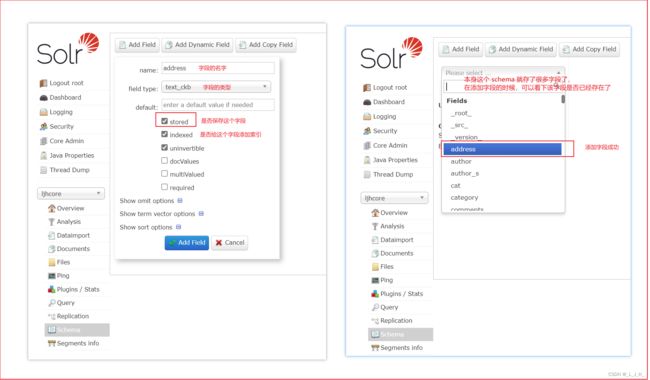
创建的 Field 就存在这个配置文件里面

演示:添加 动态字段( Dynamic Field )
Dynamic Field:动态 Field。
也就是带通配符的 Field,例如名为 “*_f” 的Field,它可以匹配 price_f、amount_f、discount_f 等各种以 _f 结尾的 Field。
通过动态字段,可以让 Core 中有限的字段去匹配所添加文档的无数字段
如图:Schema 配置文件里面本身就存有这些动态字段。
动态字段用的比较多,如图:只要后缀能匹配上就可以查询到。
比如我添加了一个动态字段为 “_动漫”,那么就可以匹配到 “七龙珠_动漫”、“火影忍者_动漫”…等等

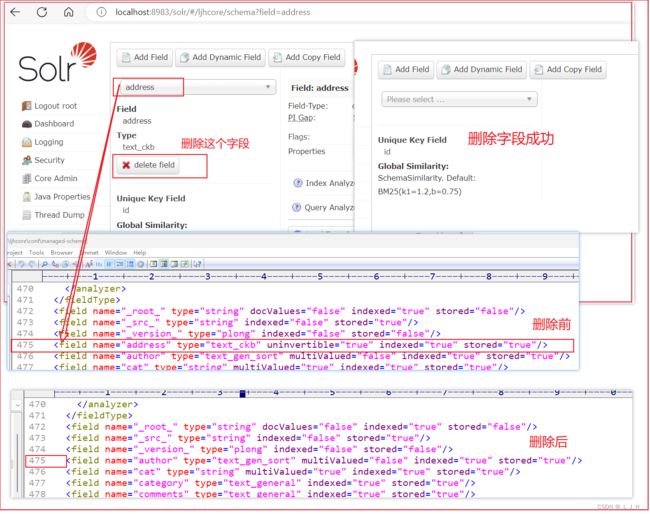
删除或修改Field
在Field管理界面上,选中指定 Field 或 Dynamic Field 后,就可以对该 Field 或 Dynamic Field 执行删除或修改操作。
管理 Copy Field(添加和删除拷贝字段)

Copy Field,意味着它的值是来自其他普通 Field。
这意味着: Copy Field 就是 目标field;而其他字段就是源字段。
源1 ↘
源2 → Copy Field(目标Field)
源3 ↗
对Copy Field的管理,无非就两个:
添加 源field 和 删除 源 field
1、添加 源field
演示添加一个拷贝字段
1、 可以选择先添加一个普通的字段作为源字段

2、单击 “Add Copy Field” 按钮,如图:这样就成功的添加了一个拷贝字段。

如果添加的 目标 copy Field 不存在,显示添加失败;
如图:在添加拷贝字段的时候,我这个“address_abc” 目标字段 是乱写的,就添加不了了,显示没有 “address_abc” 这个字段

如果添加的目标 copy Field 已经存在,它就表示只是为 copy field 新增一个源field。
就跟上面演示添加一样。
事实上,对于managed-schema文件而言,不管你是添加Copy Field,还是为已有的Cppy Field添加源字段,其最终都只是定义一个如下元素:
2、删除 源field
演示删除拷贝字段中的某个源字段。
(1)选中目标 Copy Field(Web图形界面中,Copy Field 依然是被归类在 Fields 中)
(2)单击“源字段”列表右边的红色×即可删除指定的源字段。

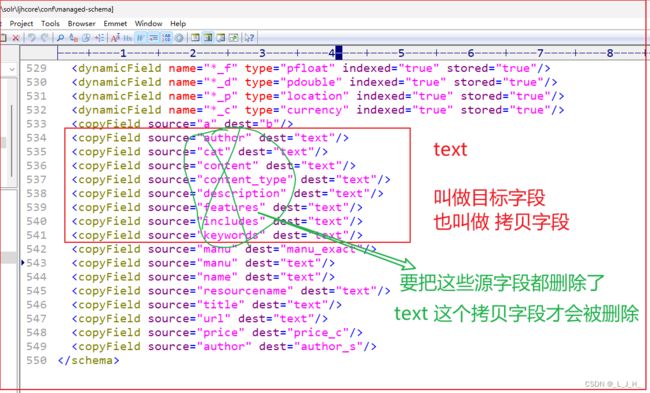
3、删除拷贝字段
如图:上面只是删除拷贝字段的 源字段,如果要完整的删除一个拷贝字段的话,需要把Copy字段的所有源字段删除时,该Copy字段才会被删除。
我们需要把属于 text 拷贝字段 的所有源字段(author…keywords)都删除,这个text拷贝字段才会被删除。
4、从 0 添加和删除拷贝字段
添加:
上面是基于已有的目标字段来添加源字段。
我这里就自己随便弄个源字段和目标字段来演示添加拷贝字段的过程。
1、我先添加两个源字段,字段a 和 字段b,
如图,在配置文件中,a和b就是两个普通的字段而已。

2、然后现在来添加一个拷贝字段:
此时把a字段作为源字段,b作为目标字段,点击添加
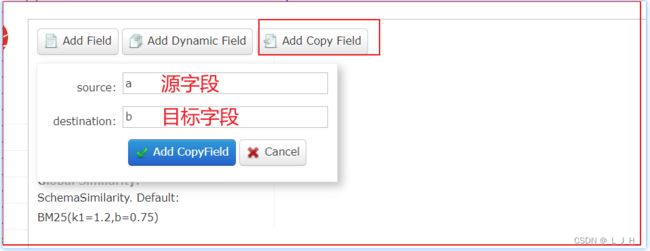
添加成功:
如图:此时的 b 这个目标字段,我们就也可以称它为 拷贝字段 了。
这样就相当于创建了一个拷贝字段了。

删除:
1、选择b这个拷贝字段,可以看到属于b这个拷贝字段的源字段只有a字段,现在我们把a源字段给删了。
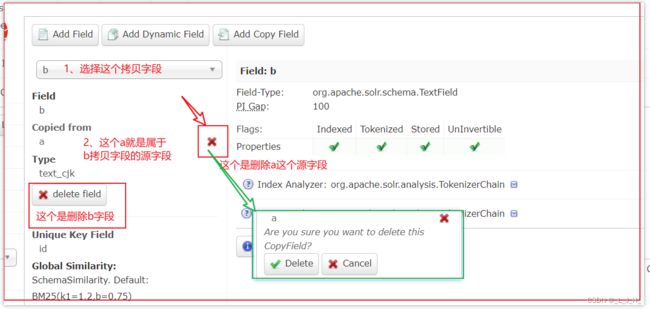
2、如图:b这个拷贝字段 只拥有 a这个源字段,如果把a这个源字段删除了,那么b这个拷贝字段也就被删除了。
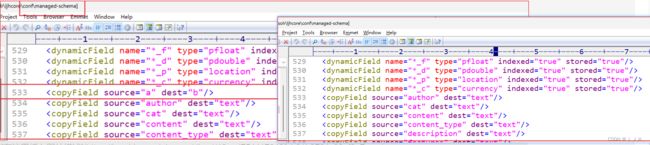
注意:
上面删的是a这个源字段,然后b这个拷贝字段因为没有源资源,所以也被删除了。
但是,a 字段 和 b 字段,它们作为普通字段,是还存在着的,这点不要混淆。
个人理解为:本来就只是存在 a 字段 和 b 字段,上面所谓删除拷贝字段的操作,删除的只是 a 字段 和 b 字段之间的拷贝关系而已。
拷贝字段应用场景解释:
如图:比如说“手机”这个关键字,存在很多字段里面,例如存在 “title”、“description”、“brand” 和 “category” 这些字段里面等。
如果我们全文检索的时候,通过 title 字段 查询 “手机”,只能查到 title 字段里面的“手机”关键字,但是却查不到 “description” 字段里面的“手机”关键字。
如果我们把 “title”、“description”、“brand” 和 “category” 这些字段都拷贝到 search_field 字段里面去,我们根据 search_field 字段来查 “手机” 这个关键字时,就能把存在 “title”、“description”、“brand” 和 “category” 这些字段里面的 “手机” 关键字都查询出来。
