【2024最全最细Lanchain教程-9】Langchain互联网查询
【2024最全最细Lanchain教程-8】Langchain数据库查询链-CSDN博客
上一节课我们介绍了数据库查询的方法,我们可以通过自然语言、借助langchain的数据库查询链实现SQL的自动生成、执行和回答。除了数据库,互联网也是我们丰富的数据来源。本节课介绍如何将互联网网页的信息进行抓取和查询。
Jupyter有同步问题,无法进行演示
因为我们调用互联网查询和检索工具,要用到Chromium一款浏览器的异步方法,这个异步方法应该是和Jupyter有冲突,所以本节课要展示的内容没办法用Jupyter演示,只能用Pycharm来进行演示。
代码实现输入URL将该页面的中文数据全部抓取下来以供查询
1. url_to_text方法实现输入URL返回一段str文本
首先引入必要用的包,注意这里的“Loader_Transformer ” 和 “transformer ”是我自己构造的两个类,等会儿会提到;构造一个Loader_Transformer 的实例,输入的参数是“www.baidu.com”的首页,然后调用Loader_Transformer 的url_to_text方法,输入是一个url,输出是一段文本:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from Loader_Transformer import Loader_Transformer
from transformer import text_to_vectorstore
if __name__ == '__main__':
loader = Loader_Transformer("https://www.baidu.com")
text = loader.url_to_text()我们来看Loader_Transformer 里面的具体代码:
import re
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
class Loader_Transformer:
'''该类的url_to_text方法输入一个url,并将该页面的全部中文字符获取下来,拼接后返回一个大的字符串作为函数的输出 '''
def __init__(self, url):
self.url = url
def display_info(self):
print(f"URL: {self.url}")
def url_to_text(self):
loader = AsyncChromiumLoader([self.url])
html = loader.load()
# print(html)
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html,
tags_to_extract=["span", "li", "p", "div", "a"]
)
# print(type(docs_transformed))
# object_size = sys.getsizeof(docs_transformed)
# print(f"Object Size: {object_size} bytes")
chinese_text = re.findall("[\u4e00-\u9fa5]+", docs_transformed[0].page_content)
# print(type(chinese_text), chinese_text)
text = ''
for i in chinese_text:
text = text + ',' + str(i)
return text该方法首先构造一个 AsyncChromiumLoader,这是一个异步的浏览器加载器,用于加载网页,然后调用 AsyncChromiumLoader 的load()方法,加载和返回一个网页文件 html。
构造一个BeautifulSoupTransformer,使用BeautifulSoupTransformer的transform_documents 方法来把这个html文件进行切分,就是把 等标签里面的东西提取出来,得到一个转化后的文档。
然后用一个正则表达式把这个文档里面的中文字符都抽取出来:
chinese_text = re.findall("[\u4e00-\u9fa5]+", docs_transformed[0].page_content)抽取出来的chinese_text是一个列表,再把列表里的每个元素拼接出来形成一个大的str文本作为函数的结果返回
2. text_to_vect 方法实现str文本向量化并返回一个向量数据库
从transformer中引入text_to_vectorstore这个类,实例化一个text_to_vectorstore类,并调用这个类的text_to_vect 方法,将一段文本转化为一个向量数据库:
vector = text_to_vectorstore(text)
vectorstore = vector.text_to_vect()text_to_vectorstore类以及text_to_vect方法的代码在下方:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
class text_to_vectorstore:
''' 调用text_to_vect()方法,将输入的一段文本存储在向量数据库里,并将该向量数据库作为结果返回'''
def __init__(self, text):
self.text = text
def display_info(self):
print(f"Input text as : {self.text}")
def text_to_vect(self):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len,
)
splitter_content = text_splitter.split_text(self.text)
api_key = os.getenv("OPENAI_API_KEY")
persist_path = r'C:\Users\PycharmProjects\langchain'
vectorstore = Chroma.from_texts(
splitter_content,
embedding=OpenAIEmbeddings(
openai_api_key=api_key,
base_url="https://wdapi7.61798.cn/v1"),
persist_directory = persist_path
)
return vectorstore3. 设置一个问题,然后可以先做一下向量相似度检索
我们可以根据页面内容问一个问题,比如“韩国什么视频爆红?”,然后进行一下向量相似度检索:
query = '韩国什么视频爆红?'
search_result = vectorstore.similarity_search_with_score(query)
print(search_result[0])我们可以查看一下相似度检索的结果,需要注意的是并不是每次得分最低的就是准确的结果,也有可能是第二第三的,这个有一定不确定性。
4. 也可以构造一个检索器,进行问题的检索
构造一个检索器,进行问题检索,这块代码是我们之前写过的【2024最全最细Lanchain教程-7】Langchain数据增强之词嵌入、存储和检索-CSDN博客 这里我们基本就照抄过来的:
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context and use chinese to answer:
{context}
Question: {question}
"""
setup_and_retrieval = RunnableParallel(
{"context": retriever, "question": RunnablePassthrough()}
)
prompt = ChatPromptTemplate.from_template(template)
output_parser = StrOutputParser()
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.7,
base_url="https://wdapi7.61798.cn/v1"
)
chain = setup_and_retrieval | prompt | llm | output_parser
result = chain.invoke(query)
print(result)我们看一下问题的回答是否结果:
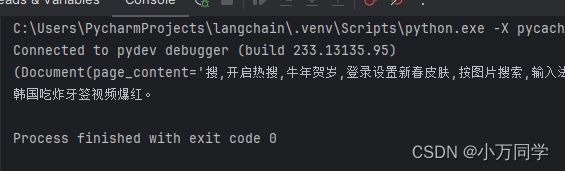
你可以把这个代码继续扩展,然后就可以得到专门用于检索中文内容的爬虫了,希望能对你有所启发。
项目git地址:https://github.com/jerry1900/jupyter
项目视频地址:【2024最全最细】Langchain之互联网查询_哔哩哔哩_bilibili
需要openai国内节点账号的同学站内私信聊。