LLM——大型语言模型简介
在coursera上看到的视频,把一些重要内容的笔记写一下。原视频更加生动,推荐有能力者可以去观看原视频
大型语言模型简介 - 大型语言模型简介 | Coursera
(翻着翻着发现了别人写过类似的内容,但还是发出来了,毕竟也只是自己的记录而已,感谢捧场的各位)
一.LLM是什么?
大型语言模型(LLM)是指可以进行预训练 并出于特定目的进行微调的 大型通用语言模型。
1.预训练:
预训练是为一般用途而训练,用于解决常见的语言问题, 例如,文本分类、问题解答、 文档摘要,以及跨行业的 文本生成。
在视频中的例子:训练一条狗坐下、趴下,了解基本指令后,狗可以听懂人一般的要求。

2.微调
对模型可以进行定制, 以便解决不同领域中的具体问题,比如零售业、金融业和娱乐业的具体问题,只需要使用少量的数据集就可以完成。
在视频中的例子:把狗训练成警犬、导盲犬或者猎犬,来适应不同方面的要求。

二.LLM的特点

1.“大型”
LLM具有规模庞大的数据集和大量的参数
2.通用
LLM可以解决常见的问题。一是因为LLM使用的自然语言是具有通用性的,不会因为某个特定的任务而无法用语言表达;二是,LLM的大型决定了必须要由非常大型的组织使用大量数据集与参数去训练好基本模型后,再供其他人使用。
3.预训练和微调
(前文已经出现过,此处再次呈现)
使用大型数据集 为一般用途预训练大型语言模型, 然后使用小得多的数据集针对特定目标进行微调。
三.LLM的优点

1.一个模型可用于不同的任务
在通用语言模型的基础下,已经可以用于解决非常多的日常问题。
这些大型语言模型是用 PB 级数据训练出来的,可以生成数十亿参数,足够智能来处理不同的任务, 包括语言翻译、句子补全、 文本分类、问题解答等。
2.用很少的数据集也可以实现出色性能
解决特定问题对LLM进行定制时, 即使只有很少的领域训练数据,它也可以实现出色的性能,可以用于小样本甚至零样本场景。
在机器学习中, “小样本”是指用极少的数据训练模型。 “零样本”则意味着, 模型可以识别在之前的训练中没有明确学习过的事物。
3.添加更多数据和参数时, LLM性能将随之持续提升
四.LLM和机器学习的区别

LLM开发不需要在语言模型方面掌握大量的专业知识,不需要训练示例, 也不需要训练模型,只需要考虑提示设计。提示设计,就是创建一个清晰、简洁并且内容丰富的提示。 【自然语言处理 (NLP) 的 重要组成部分】
机器学习需要掌握相关知识(见上图)
五.Prompt Design 和Prompt Engineering

Design 和Engineering都涉及到建立清晰、简洁且内容丰富的提示。但是,Design更加侧重于“从无到有”的设计,例如写提示实现将英语翻译为法语;而Engineering旨在提高性能,比如通过“think step by step”等提示词让模型能够给予我们更加准确的答案。
六.三种LLM

1.Generic Language Model 预测下一个词是什么

2.Instruction Tuned 指令微调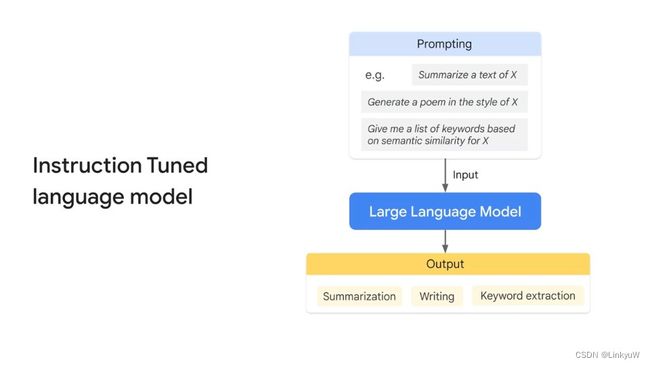
这里在视频中叙述并不详细,因此摘抄了一篇知乎中的描述作为补充
什么是大语言模型(LLM)的指令微调? - 知乎
指令微调是指通过构建指令格式的实例,然后以有监督的方式对大语言模型进行微调。指令格式通常包含任务描述,一对输入输出以及示例(可选)。
例如,“请回答以下问题:中国的首都是哪个城市?”,回答:“中国的首都是北京”,其中“请回答以下问题:”是任务描述,“中国的首都是哪个城市?”是输入,“中国的首都是北京”是输出。又比如“请将英文翻译为中文,输入示例:The capital city of China is Beijing,输出示例:中国的首都是北京。请翻译:Which city is the capital of US?”,回答:“美国的首都是哪个城市?”,这里就多一个示例,这有助于大模型理解任务。
指令微调可以帮助LLM拥有更好的推理能力, 从而展现出泛化到未见过任务的卓越能力。也就是说,就算微调的指令中没有设计相关的任务,大模型在新任务上的表现也会优于微调之前。
3.Dialog Tuned 对话微调
通常以向AI提问的方式呈现的,得到更好的输出结果的方式。例如,使用形容词"briefly”

或者,用思维链的方式,让AI一步步想出答案

七.微调
针对特定任务进行微调,可以让 LLM 更加可靠.
1.Tuning

通过调整模型,可以基于希望模型执行的任务示例,自定义模型的回应。
从本质上来讲,这个流程就是使用新数据来训练模型,使模型适应新领域或一系列自定义应用场景。
例如,我们可能会收集训练数据, 然后专门针对法律或者医疗领域 “调整”模型。
2.Fine tuning

在这种场景下,可以使用自己的数据集,调整 LLM 中的每个权重,进而重新训练模型。 不过,这需要大量的训练工作。
当然,这里还存在着更高效的微调办法,不过在此视频中没有具体解释。其中一个提及到的是
参数高效微调(PETM),大家可以自行上网搜索。