AdaBoost算法
Boosting是一种集成学习方法,AdaBoost是Boosting算法中的一种具体实现。
Boosting方法的核心思想在于将多个弱分类器组合成一个强分类器。这些弱分类器通常是简单的模型,比如决策树,它们在训练过程中的错误会被后续的弱分类器所修正。Boosting算法通过逐步增加新的弱分类器来提高整体模型的性能,每个新的弱分类器都专注于之前模型分类错误的样本。
AdaBoost(Adaptive Boosting)是Boosting算法家族中的一员,它的特点是使用了指数损失函数(exponential loss function),这种损失函数会给分类错误的样本赋予更大的权重,使得后续的弱分类器更加关注这些难以分类的样本。通过这种方式,AdaBoost能够自适应地调整每个样本的权重,从而提高模型的整体性能。除了AdaBoost,还有其他基于不同损失函数的Boosting算法,如L2Boosting和LogitBoost等。这些算法虽然在具体的实现细节上有所不同,但都遵循了Boosting方法将弱分类器组合成强分类器的基本框架。
Boosting每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。

Bagging 和 Boosting
Bagging 通过均匀取样的方式从原始样本集中抽取训练集,而 Boosting 使用全部样本,并在每一轮训练中根据错误率调整样例权重。这意味着 Bagging 的训练过程可以并行进行,因为它的基模型之间是独立的,而 Boosting 通常是串行进行的,因为每个模型都依赖于前一个模型的表现。
Bagging 方法中每个基模型对于最终决策的贡献是相等的,类似于民主投票制,每个模型有一票;而在 Boosting 中,每个基模型的贡献是根据其性能加权的,性能更好的模型会有更大的影响力。
AdaBoost
AdaBoost算法的核心步骤是:
-
权重更新:在每一轮迭代中,根据样本的分类结果来更新每个样本的权重。如果一个样本被正确分类,那么它的权重将会降低;如果一个样本被错误分类,那么它的权重将会增加。这样可以使得在后续的迭代中,分类器更加关注那些难以分类的样本。
-
弱分类器的选择:在每一轮迭代中,从所有的弱分类器中选择一个最佳的弱分类器。这个最佳的弱分类器是指在当前权重分布下,分类误差最小的那个弱分类器。
-
分类误差率较小的弱分类器的权值大,在表决中起较大作用。
AdaBoost 模型公式
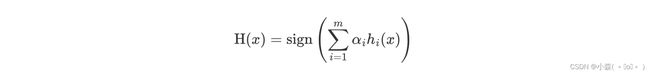
- α 为模型的权重,m 为弱学习器数量。
- hi(x) 表示弱学习器
- H(x) 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost 构建过程
| Sample | Feature (x) | Label (y) |
|---|---|---|
| 1 | 1 | -1 |
| 2 | 2 | -1 |
| 3 | 3 | 1 |
| 4 | 4 | 1 |
初始化
D1(1)=D1(2)=D1(3)=D1(4)=1/4
第1轮迭代
- 训练一个弱分类器 ℎ1(x),例如 h_1(x) = \sign(x - 1.5)。
- 计算错误率 ϵ1,假设所有样本都被正确分类,则 ϵ1=0。
- 计算权重α1,由于epsilon1=0,则α1=infty。但通常我们会设置一个上限,比如α1=0.5。
- 更新样本权重,由于所有样本都被正确分类,权重保持不变。
第2轮迭代
- 训练另一个弱分类器 ℎ2(x),例如 h_2(x) = \sign(x - 3)。
- 计算错误率 ϵ2,假设样本1和2被正确分类,样本3和4被错误分类,则ϵ2=21。
- 计算权重α2,α2=21ln(212)=21ln(4)≈0.693。
- 更新样本权重,增加样本3和4的权重,减少样本1和2的权重。
最终分类器
- 组合弱分类器的预测结果,形成最终的强分类器H(x)。
这个过程会根据迭代次数M 重复进行,直到达到预定的迭代次数或者满足某个停止条件(如错误率达到某个阈值)。
Demo实战
import pandas as pd
df_wine = pd.read_csv('wine.data')
df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines',
'Proline']
df_wine = df_wine[df_wine['Class label'] != 1]
X = df_wine[['Alcohol', 'Hue']]
y = df_wine['Class label']划分训练集测试集
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
le = LabelEncoder()
y = le.fit_transform(y)
# 划分训练集测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
tree = DecisionTreeClassifier(criterion='entropy',max_depth=1)
ada= AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pre = tree.predict(X_train)
y_test_pre = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pre)
tree_test = accuracy_score(y_test,y_test_pre)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
# 0.845/0.854
ada = ada.fit(X_train,y_train)
y_train_pre = ada.predict(X_train)
y_test_pre = ada.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pre)
ada_test = accuracy_score(y_test,y_test_pre)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
# 1/0.875AdaBosst的决策区域比单层的决策区域更加复杂。
集成学习与单独的分类器性能比较,集成学习提高了复杂度,但在实践中,需要衡量是否愿意为适度提高预测性能付出更多的计算成本。
AdaBoost算法的总结
AdaBoost的核心思想是通过对错误分类的样本增加权重,使得后续的弱分类器更加关注这些难以分类的样本。通过加权投票的方式,将多个弱分类器的预测结果组合起来,形成一个强分类器。
- 初始化:为每个训练样本分配相同的权重。
- 迭代训练弱分类器:对于每一轮迭代,训练一个弱分类器,使其在加权训练集上的错误率最小化。
- 计算弱分类器权重:根据弱分类器在加权训练集上的错误率,计算其权重。错误率越低,权重越高。
- 更新样本权重:根据弱分类器的表现,更新样本权重。被错误分类的样本权重增加,正确分类的样本权重减少。
- 构建最终分类器:将所有弱分类器的预测结果按照其权重进行加权求和,形成最终的强分类器。

应用领域
AdaBoost算法广泛应用于各种机器学习任务,包括图像识别、文本分类、医学诊断等领域。
优点
- 提高模型的性能:AdaBoost可以显著提高弱分类器的性能,使其成为一个强大的分类器。
- 鲁棒性:AdaBoost对于过拟合具有很好的鲁棒性。
- 灵活性:可以与各种类型的弱分类器结合使用。
缺点
- 对噪声敏感:如果训练数据包含噪声,AdaBoost可能会给噪声样本分配较高的权重,从而影响模型的性能。
- 长时间训练:对于大规模数据集,AdaBoost的训练时间可能会很长。