测试工程师-SQL常用语句SQL面试必问
背景
SQL这个东西嘛,说难其实也不是很难,说难确实在应用场景当中真的很难。工作过的自然懂
作为一名有实力的测试工程师,不应该只会select简单语句,我们要使用SQL计算、SQL判断、子查询、多表连接、视图、事务等技能。
其次是为了下一次的面试做好准备!冲!
SQL执行的先后顺序
1、from 子句组装来自不同数据源的数据;
2、where 子句基于指定的条件对记录行进行筛选;
3、group by 子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用 having 子句筛选分组;
6、计算所有的表达式;
7、select 的字段;
8、使用 order by 对结果集进行排序
SQL书写的先后顺序
select *
from
where
group by
having
order by
limit查找
select 语句
先从简单的SELECT 查询开始
SELECT * FROM emp;DISTINCT去重查询
写一个最简单的去重语句DISTINCT
具有唯一性的
DISTINCT关键字,必须放在【列】的前面
DISTINCT不能部分使用,作用于所有【列】
SELECT DISTINCTclass_id FROM class
LIMIT查询前5条数据
返回不超过5行的数据
SELECT * FROM salgrade LIMIT 5LIMIT从第2条开始,查询前3条数据
SELECT * FROM salgrade LIMIT 3 OFFSET 2
# OFFSET的简写是反着来的
SELECT * FROM salgrade LIMIT 2,3 排序
按照列位置排序
SELECT会按照第二列prod_price进行排序,再按prod_name进行排序
SELECT prod_id,prod_price,prod_name FROM products ORDER BY 2,3指定排序方向
SQL默认从小到大(1~9,A~Z),升序ASC排序,可以写ASC也可以不写,不写就默认升序
从大到小(9~1,Z~A)降序DESC
CREATE TABLE products (
prod_id INT,
prod_price NUMERIC(10,2),
prod_name VARCHAR(50)
);
INSERT INTO products (prod_id, prod_price, prod_name)
VALUES
(1, 19.99, 'Product A'),
(2, 29.99, 'Product B'),
(3, 39.99, 'Product C');
SELECT prod_id, prod_price, prod_name
FROM products
ORDER BY prod_price DESC;
prod_id | prod_price | prod_name
--------+------------+-----------
3 | 39.99 | Product C
2 | 29.99 | Product B
1 | 19.99 | Product A指定顺序返回结果ORDER BY
SQL默认从小到大(1~9,A~Z),升序ASC排序,可以写ASC也可以不写,不写就默认升序
从大到小(9~1,Z~A)降序DESC
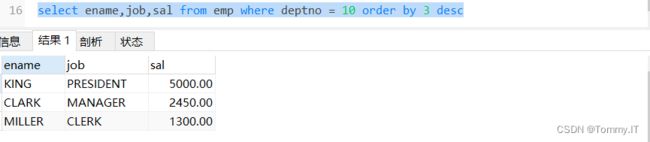
order by 3 desc,相当于以第3列,即SAL列
select ename,job,sal from emp where deptno = 10 order by sal asc
select ename,job,sal from emp where deptno = 10 order by sal desc
select ename,job,sal from emp where deptno = 10 order by 3 desc
指定字符串排序SUBSTR
按照最后2个字符排序,SUBSTR取是字符串开始位置到最后位置
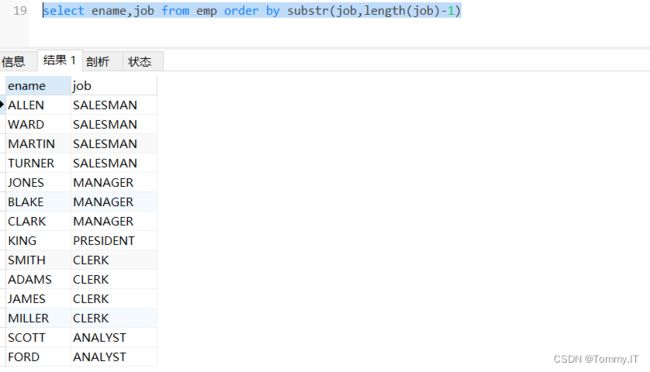
select ename,job from emp order by substr(job,length(job)-1)排序时处理,处理下图的NULL值(多列排序)
select ename,sal, comm from emp order by 3 查询出来的结果,升序排列,怎样才能先将NULL全部放后面,然后comm列正常升序排序;
又或者NULL先降序,又或者NULL再升序?

这里需要用CASE,创建一个‘标签’,先看看最终结果

select ename,sal,comm from
(select ename,sal,comm,
case when comm is null then 0 else 1 end as is_null
from emp
) c
order by is_null desc,comm拆解一下括号里面的语句,comm如果是IS NULL =0 否则=1,查询处理的结果是

假设现在我们再将is_null再排序,升序0~1,降序1~0

显然要么有数据都在前面,要么都在后面,这样子,就可以多列排序
where条件
where子句比较操作符号
| 操作符 | 作用 |
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| !< | 不小于 |
| > | 大于 |
| !> | 不大于 |
| >= | 大于等于 |
| BETWEEN | 在指定的两个值之间 |
| IS NULL | 为NULL值 |
在where子句中使用别名来引用列
出现这一种报错是什么原因?Error Code: 1054. Unknown column 'salary'......
-- 在where子句中使用别名来引用列
select sal as salary ,comm as commission from emp where salary < 5000;
-- Error Code: 1054. Unknown column 'salary' in 'where clause'
select * from (select sal as salary ,comm as commission from emp) sc where salary < 5000;查找NULL值IS NULL /IS NOT NULL
判断一个值是否为NULL,必须用 IS NULL,NULL与任何值都不相等(包括NULL本身),不能使用!=去判断
select * from emp where comm is null如果需要查询出不为NULL,必须用IS NOT NULL来查找不为NULL的行
select * from emp where comm is not null范围值检查 BETWEEN AND
从范围开始值到范围结束值,必须是低值到高值,或者是一个开始日期到结束日期
select * from emp where emp_id BETWEEN 1 AND 10;where 多条件检查
AND操作符,表示并且的关系,每增加一个过滤的条件,必须同时增加AND的关键字
查询emp_id = 1 和 emp_name = 'ceo',满足两个条件的要求
select * from emp where emp_id = 1 AND emp_name = 'ceo'OR操作符,表示或者的关系,只要有一个条件为真就满足查询结果
查询emp_id = 1 或者是 emp_name = 'ceo',满足其中一个条件的要求,当一个条件满足是,不管第二个条件,都会被检索出来
select * from emp where emp_id = 1 OR emp_name = 'ceo'多表连接
合并多个行集UNION ALL
需要将表1,表2的数据合在一起,先看看2个表的数据
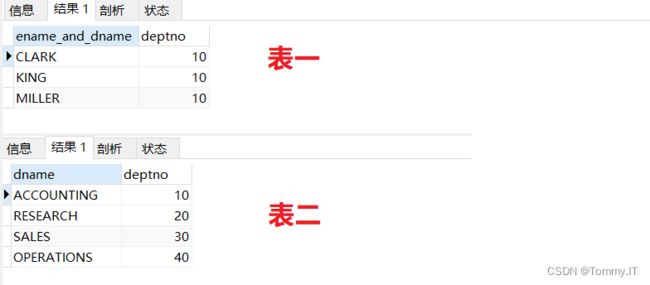
使用union all ,需要注意的是,select中指定的列的数量和类型必须匹配,union all 不会剔除重复行
select ename as ename_and_dname,deptno from emp where deptno = 10
union all
select '------------', null
union all
select dname,deptno from dept 最终效果

查找没有出现在另一张表中的值
从表2中哪一条数据没有在表1中出现过?
deptno 40的没有在表1
select * from dept where deptno not in(select deptno from emp)
查找没有出现在另一张表中的行
select d.* from dept d
left join emp e
on d.deptno = e.deptno
where e.deptno is null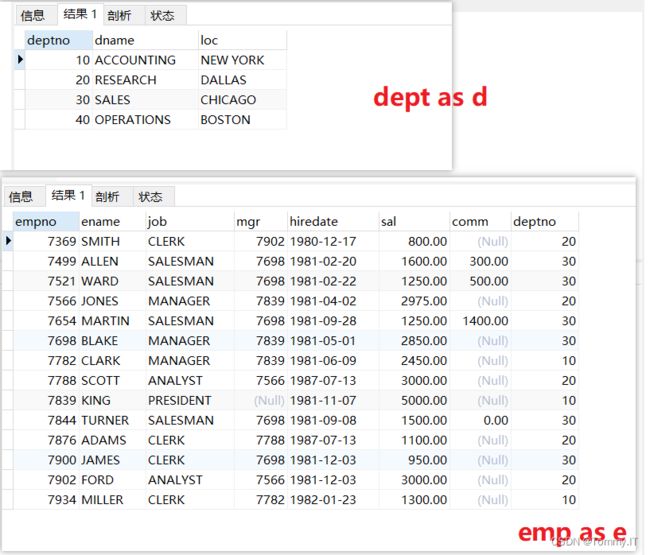
插入1条或多条新记录
insert into dept (deptno,dname,loc) values(50,'testing','GUANGZHOU')
-- 插入多行
insert into dept (deptno,dname,loc)
values
(51,'testing2','GUANGZHOU'),
(52,'ADMIN','GUANGZHOU')更新表中指定的记录
指定记录必须要有where的条件否则,更新所有的列
update dept set dname = 'TESTING' where deptno = 50例子:
要么问你平时怎么使用SQL
临时查询,select *,但一般会了解自身业务,需要哪些字段返回,通常select 带上对于的列作为展示;一来方便自己快速查找想要的数据,二来别人从字段中快速找到需要的数据
遇到什么场景下使用SQL
比如需要添加批量的会员数据,使用insert into语句;
查询会员下单金额,数量等
SQL如何优化
减少使用select *
另外一些where 条件能用等于的就尽量用等于,减少用 like的查询