政安晨:快速学会~机器学习的Pandas数据技能(五)(分组和排序)
提升您的洞察力水平,数据集越复杂,这一点就越重要。

概述
映射允许我们逐个值地转换DataFrame或Series中的数据,针对整个列进行操作。然而,通常我们希望对数据进行分组,然后对所在组进行特定操作。
正如你将学到的,我们可以通过groupby()操作来实现这一点。我们还将涵盖一些额外的主题,例如更复杂的索引DataFrame的方式,以及如何对数据进行排序。
群组分析
咱们接着前几篇的文章继续处理数据,数据文件从我这篇文章中下载:
政安晨:快速学会~机器学习的Pandas数据技能(三)(重命名与合并) https://blog.csdn.net/snowdenkeke/article/details/136081348到目前为止,我们一直在大量使用的一个函数是value_counts()函数。我们可以通过以下方式复制value_counts()函数的功能:
https://blog.csdn.net/snowdenkeke/article/details/136081348到目前为止,我们一直在大量使用的一个函数是value_counts()函数。我们可以通过以下方式复制value_counts()函数的功能:
import pandas as pd
reviews = pd.read_csv("./winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
#查看表格
reviews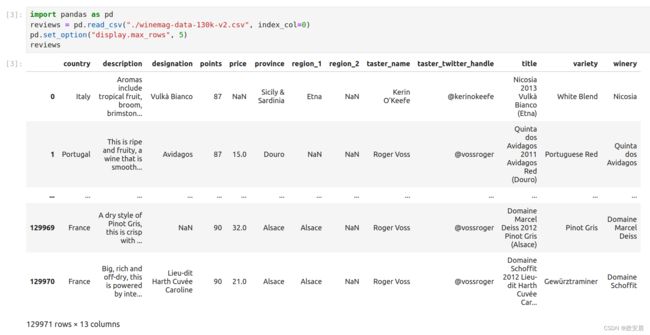
reviews.groupby('points').points.count()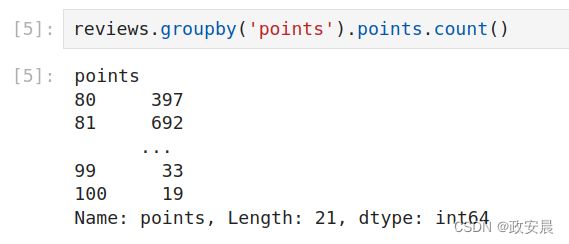
groupby()创建了一个评论的分组,为给定的葡萄酒分配了相同的点数值。然后,对于这些分组中的每一个,我们提取了points()列,并计算它出现的次数。value_counts()只是这个groupby()操作的一个快捷方式。
我们可以使用之前使用过的任何摘要函数来处理这些数据。例如,要获取每个点数值类别中最便宜的葡萄酒,我们可以执行以下操作:
reviews.groupby('points').price.min()
您可以将我们生成的每个组视为DataFrame的一个切片,其中仅包含与条件匹配的数据。我们可以直接使用apply()方法访问这个DataFrame,并可以以任何我们认为合适的方式操纵数据。例如,以下是选择数据集中每个酒庄的第一个被评价葡萄酒的名称的一种方法:
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])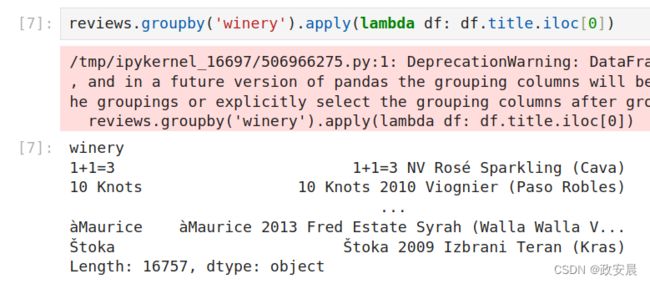
更加细致的控制,你还可以按多列进行分组。举个例子,这里是我们如何按国家和省份挑选出最好的葡萄酒:
reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])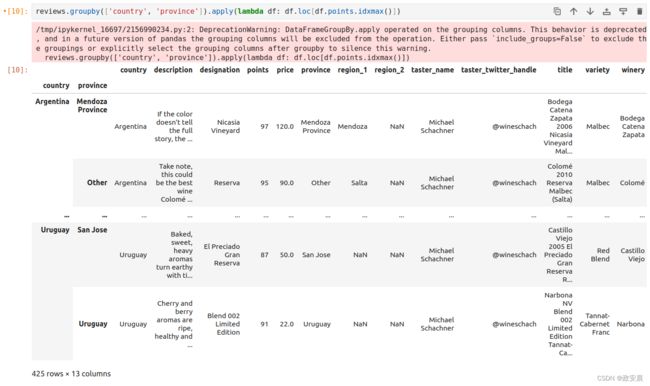
另外一个值得一提的groupby()方法是agg(),它允许你同时对DataFrame运行多个不同的函数。例如,我们可以这样生成数据集的简单统计摘要:
reviews.groupby(['country']).price.agg([len, min, max])
使用groupby()方法的有效用法将使您能够在数据集中做许多非常强大的事情。
多级索引
迄今为止,在我们看到的所有示例中,我们一直在使用具有单标签索引的DataFrame或Series对象。但是,groupby()稍有不同,它根据我们运行的操作不同,有时会生成所谓的多级索引。
多级索引与常规索引不同,它具有多个级别。例如:
countries_reviewed = reviews.groupby(['country', 'province']).description.agg([len])
countries_reviewed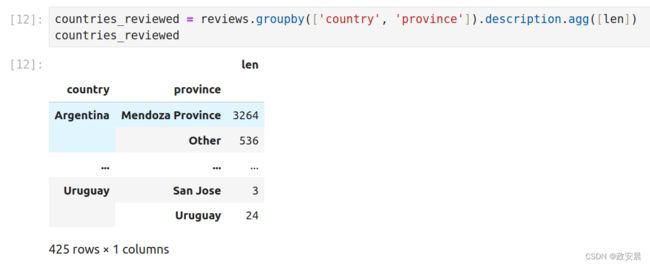
mi = countries_reviewed.index
type(mi)
多层索引具有几种处理层次结构的方法,这些方法在单级索引中是不存在的。它们还需要两个级别的标签来检索值。处理多层索引输出是对Pandas新用户常见的"陷阱"。
在Pandas文档的MultiIndex / Advanced Selection部分详细介绍了多层索引的使用案例以及使用它们的说明。
然而,通常你会经常使用的多层索引方法是将其转换回常规索引的reset_index()方法:
countries_reviewed.reset_index()
分类排序
再次查看countries_reviewed,我们可以看到分组返回的数据是按照索引顺序而非值顺序排序的。也就是说,当输出groupby的结果时,行的顺序取决于索引中的值,而不是数据中的值。
为了按照我们期望的顺序获取数据,我们可以自己进行排序。sort_values()方法非常方便用于此操作。
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by='len')
sort_values()默认按升序排序,其中较小的值先出现。然而,大多数情况下,我们希望进行降序排序,即较高的数字先出现。这样可以这样做:
countries_reviewed.sort_values(by='len', ascending=False)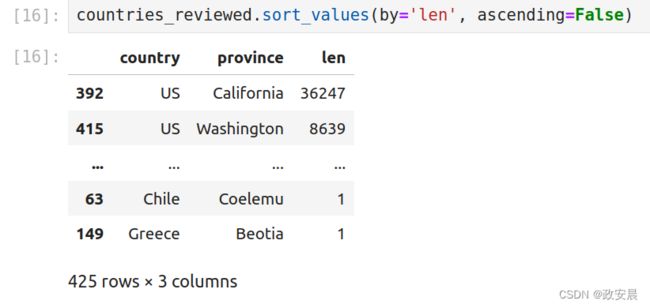
要按索引值排序,请使用sort_index()方法。该方法具有相同的参数和默认排序顺序:
countries_reviewed.sort_index()
为了按索引值排序,可以使用sort_index()方法。这个方法具有相同的参数和默认排序顺序:
countries_reviewed.sort_index()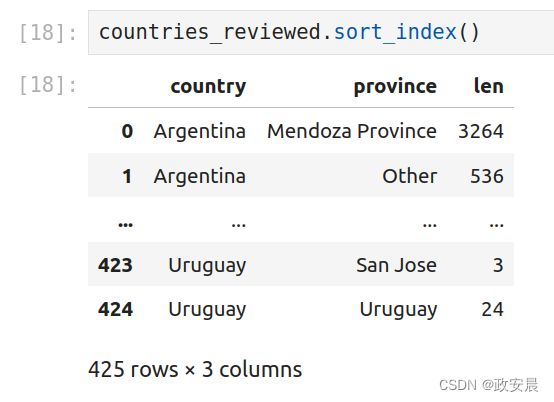
最后,要知道你可以同时按多列进行排序:
countries_reviewed.sort_values(by=['country', 'len'])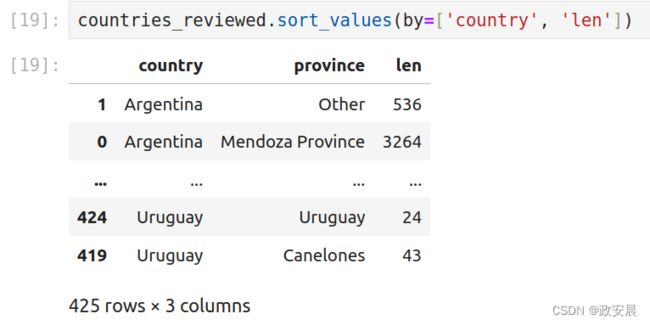
小伙伴们有空可以尝试一下,其实把数据降维思考,您会有不一样的认识。
