【CV论文精读】【MVDet】Multiview Detection with Feature Perspective Transformation
0.论文摘要
合并多个摄像机视图进行检测减轻了拥挤场景中遮挡的影响。在多视图检测系统中,我们需要回答两个重要问题。首先,我们应该如何从多个视图中聚合线索?第二,我们应该如何从空间上相邻的位置聚集信息?为了解决这些问题,我们引入了一种新的多视图检测器MVDet。在多视图聚合期间,对于地面上的每个位置,现有方法使用多视图anchor box特征作为表示,这可能会限制性能,因为预定义的anchor box可能不准确。相比之下,通过特征图透视变换,MVDet采用无anchor点表示,特征向量直接从多个视图中的相应像素采样。对于空间聚合,与以前需要在神经网络之外进行设计和操作的方法不同,MVDet采用完全卷积的方法,在多视图聚合要素图上使用大卷积核。所提出的模型是端到端可学习的,在Wildtrack数据集上实现了88.2%的MODA,比最先进的模型高出14.1%。我们还在新引入的合成数据集MultiviewX上提供了MVDet的详细分析,这使我们能够控制遮挡水平。
1.研究背景
遮挡是许多计算机视觉任务面临的基本问题。具体来说,在检测问题中,遮挡带来了很大的困难,并且已经提出了许多方法来解决它。一些方法集中于单视图检测问题,例如,基于部分的检测[35,25,48],损失设计[46,39],以及学习非最大抑制[13]。其他方法从多个线索联合推断对象,例如RGB-D[10,12,27]、激光雷达点云[6]和多个RGB相机视图[8,3]。在本文中,我们重点研究了来自多个RGB相机视图(多视图)的行人检测。
多视角行人检测通常具有来自多个校准摄像机的同步帧作为输入[8,29,3]。这些摄像机聚焦在同一个区域,
并且具有重叠的视野(参见图1)。相机校准提供2D图像坐标(u,v)和3D世界位置(x,y,z)之间的匹配。我们将3D世界中z=0的点称为地平面(鸟瞰视图)。对于地平面上的每个点,基于三维人体宽度和高度假设,通过投影计算其在多个视图中对应的边界框,然后存储。由于边界框可以通过表格查找检索,多视图行人检测任务通常评估地平面上的行人占用情况[8,3]。
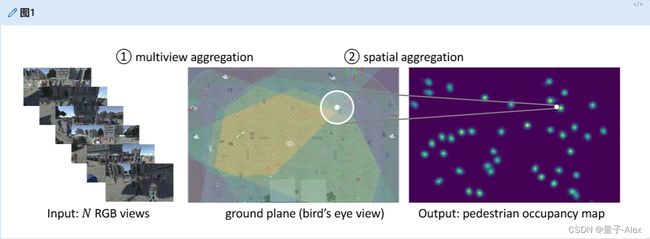
图1。多视角行人检测系统概述。左图:系统将来自N台摄像机的同步帧作为输入。中间:摄像机视野在地平面上重叠,多视图线索可以在地平面上聚合。右图:系统输出行人占用图(POM)。这里有两个重要的问题。首先,我们如何聚合多个线索。第二,如何聚合空间邻居信息进行联合考虑(大白圈),对行人占用情况做出综合决策(小白圈)。
解决遮挡和拥挤带来的模糊性是多视角行人检测的主要挑战。在遮挡状态下,很难确定一个人是否存在于某个位置,或者存在多少人以及他们在哪里。为了解决这个问题,必须关注多视图检测的两个重要方面:第一,多视图聚合,第二,空间聚合(图1)。多视图信息的聚合是必不可少的,因为具有多视图是单视图检测和多视图检测之间的主要区别。以前,对于给定的地平面位置,多视图系统通常选择基于anchor的多视图聚合方法,并用多视图anchor box特征表示特定的地平面位置[4,1,17]。然而,研究人员发现,基于anchor的方法的性能可能会受到单目视图系统中预定义anchor box的限制[49,16,43],而根据预定义的人体3D高度和宽度计算的多视图anchor box也可能不准确。空间邻居的聚集对于遮挡推理也是至关重要的。以前的方法[8,29,1]通常采用条件随机场(CRF)或平均场推断来共同考虑空间邻居。这些方法通常需要特定的潜在项设计或卷积神经网络(CNN)之外的额外操作。
在本文中,我们提出了一种简单而有效的方法,MVDet,这是迄今为止还没有在文献中探索的多视图检测。首先,对于多视图聚合,由于基于不准确的anchor box的表示会限制系统性能,而不是基于anchor的方法[4,1,17],MVDet选择具有在多个视图中的相应像素处采样的特征向量的无anchor表示。具体来说,MVDet通过透视变换投影卷积特征图,并连接多个投影的特征图。第二,对于空间聚合,为了最大限度地减少CNN之外的人工设计和操作,MVDet采用了完全卷积的解决方案,而不是CRF或平均场推理[8,29,1]。它在聚合的地平面特征图上应用(学习的)卷积,并使用大感受野来共同考虑地平面相邻位置。所提出的全卷积MVDet可以以端到端的方式进行训练。我们在两个大规模数据集上证明了MVDet的有效性。在真实世界的数据集Wildtrack上,MVDet实现了88.2%的MODA[15],比以前的最先进水平增加了14.1%。在合成数据集MultiviewX上,MVDet也在多级遮挡下取得了有竞争力的结果。
2.相关工作
2.1 Monocular view detection 单目检测
检测是计算机视觉中最重要的问题之一。像faster R-CNN[28]和SSD[21]这样基于anchor的方法实现了很好的性能。最近,寻找预定义的anchor可能会限制性能,提出了许多无anchor方法[49,36,16,43,7,18]。在行人检测方面,一些研究人员通过头—脚点检测[32]或中心和比例检测[22]来检测行人边界框。行人检测中的遮挡处理引起了研究界的极大关注。基于部分的检测器非常受欢迎[25,35,24,46],因为被遮挡的人只能部分观察到。霍桑等人。[13]学习遮挡行人的非最大抑制。排斥损失[39]被提出来排斥边界盒。
2.2 3D object understanding with multiple information sources
结合多个信息源,如深度、点云和其他RGB相机视图,研究了3D对象理解。对于多视图三维物体分类,苏等。[33]使用最大池化来聚合来自不同2D视图的特征。对于三维目标检测,来自RGB图像和激光雷达点云的聚合信息被广泛研究。陈等。[5]研究了立体图像的三维目标检测。[17]中研究了3Danchor点的视图聚合,研究人员从RGB相机和激光雷达鸟瞰图中提取每个3Danchor点的特征。梁等。[19]从K个最近邻激光雷达点的相机视图特征计算鸟瞰视图中每个点的特征,作为多层感知器输出。平截头体点网[27]首先从RGB图像生成2D边界框建议,然后将它们挤压到3D观察平截头体。姚等。编辑3D车辆模型的属性,以创建内容一致的车辆数据集[44]。
2.3 Multiview pedestrian detection
在多视角行人检测中,首先,聚合来自多个RGB摄像机的信息至关重要。在[4,1]中。搜索者为多视图2Danchor融合多个信息源。给定人的宽度和高度的固定假设,首先计算所有地平面位置及其对应的多视图2Danchor box。然后,[4,1]中的研究人员用相应的anchor box特征来表示地平面位置。在[8,41,29]中,单视图检测结果被融合。第二,为了聚集空间邻居信息,利用了平均场推断[8,1]和条件随机场(CRF)[29,1]。在[8,1]中,场景中的总占用率被视为能量最小化问题,并用CRF解决。弗勒特等人。[8]首先估计一定占用率下的理想2D图像,然后将它们与真实的多视图输入进行比较。巴克等人。[1]构造高阶势作为CNN估计和生成的理想图像之间的一致性,并以组合的方式用CNN训练CRF,并在Wildtrack数据集上实现最先进的性能[3]。
2.4 Geometric transformation in deep learning
仿射变换和透视变换等几何变换可以对计算机视觉中的许多现象进行建模,并且可以用一组固定的参数显式计算。Jaderberg等人[14]提出了空间Transformer model网络,该网络学习用于2D RGB输入图像的平移和旋转的仿射变换参数。Wu等[40]估计投影参数并从3D骨架投影2D关键点。Yan等[42]通过透视变换将一个3D体积转换为2D剪影。[38]中通过估计实例级仿射变换研究了几何感知场景文本检测。对于交叉视图图像检索,Shi等[30]应用极坐标变换使特征空间中的表示更接近。Lv等为车辆的新型视图合成提出一个透视感知生成模型[23]。
3.核心思想
在这项工作中,我们重点研究了多视图场景中的遮挡行人检测问题,并设计了MVDet来处理模糊度。MVDet的特点是无anchor多视图聚合,减轻了以前工作中不准确anchor box的影响[6,17,4,1],以及不依赖于CRF或平均场推断的完全卷积空间聚合[8,29,1]。如图2所示,MVDet将多个RGB图像作为输入,并输出行人占用图(POM)估计。在接下来的章节中,我们将介绍建议的多视图聚合(第3.1节)、空间聚合(第3.2节)以及训练和测试配置(第3.3节)。
3.1 Multiview Aggregation
多视图聚合是多视图系统中非常重要的一部分。在本节中,我们将解释MVDet中减轻不准确anchor box影响的无anchor聚合方法,并将其与几种替代方法进行比较。
3.1.1 Feature map extraction
在MVDet中,首先,给定N个形状为 [ H i , W i ] [H_i, W_i] [Hi,Wi]的图像作为输入( H i H_i Hi和 W i W_i Wi表示图像高度和宽度),所提出的架构使用CNN来提取N个C通道特征图(图2)。

图二。MVDet架构。首先,给定来自N个摄像机的形状 [ 3 , H i , W i ] [3, H_i, W_i] [3,Hi,Wi]的输入图像,所提出的网络使用CNN来提取每个输入图像的C通道特征图。这里的CNN特征提取器在N个输入中共享权重。接下来,我们将C通道特征图重塑为 [ H f , W f ] [H_f , W_f ] [Hf,Wf]的大小,并通过检测头—脚对来运行单视图检测。然后,对于多视图聚合(圈1),我们采用无anchor方法,并结合基于相机校准的N个特征图的透视变换 θ ( 1 ) , . . . , θ ( N ) θ^{(1)}, . . . , θ^{(N)} θ(1),...,θ(N),其产生形状为 [ C , H g , W g ] [C, H_g, W_g] [C,Hg,Wg]的N个特征图。对于每个接地层位置,我们将其X-Y坐标存储在双通道坐标图中[20]。通过将N个投影特征图与一个坐标图连接起来,我们聚合了整个场景的地平面特征图(形状为 [ N × C + 2 , H g , W g ] [N × C + 2, H_g, W_g] [N×C+2,Hg,Wg])。最后,我们在地平面特征图上应用大核卷积,以便聚集空间邻居信息(圈出的2),用于联合和全面的最终占用决策。
这里,我们选择ResNet-18[11]是因为它性能强,重量轻。该CNN分别计算N幅输入图像的C通道特征图,同时在所有计算中分担权重。为了保持特征图相对较高的空间分辨率,我们用扩张卷积替换了最后3个跨步卷积[45]。在投影之前,我们将N个特征贴图调整为固定大小 [ H f , W f ] [H_f , W_f ] [Hf,Wf]( H f H_f Hf和 W f W_f Wf表示特征贴图的高度和宽度)。在每个视图中,类似于[18,32],我们然后用共享重量的单视图检测器将行人检测为一对头——脚点。
3.1.2 Anchor-free representation
以前,在具有多个线索的检测任务中,例如3D对象检测和多视图行人检测,通常采用基于anchor点的表示[6,17,4,1]。具体来说,可以通过ROI-pooling[9]用anchor box(图3中的绿框)特征来表示接地层位置(图3中的红点)。
根据假设的3D人体高度和宽度计算anchor boxes的大小和形状[4,1],这些anchor box可能不准确,这可能会限制系统性能[49,16,43]。如图3所示,穿白大褂的女士坐着,只占anchor箱的一半。因此,ROI池将导致在很大程度上描述背景的特征表示,并导致混乱。

图3。用特征向量(无anchor)或anchor box特征(基于anchor)表示地平面位置。红点代表某个接地层位置及其在不同视图中的对应像素。绿色边界框是指对应于接地层位置的anchor定框。由于人类目标的大小可能与假设的不同(例如,穿着白大褂的女士),多视图anchor box的ROI池可能无法为该位置提供最准确的特征表示。相反,由于没有anchor,从相应点检索的特征向量避免了不准确anchor box的影响。
相反,由于没有anchor,所提出的方法用从相应点的特征图中采样的特征向量来表示地平面位置,这避免了不准确anchor box的影响。给定摄像机校准,可以精确地检索相应的点。通过可学习的卷积核,这些特征向量可以表示来自其感受野中的自适应区域的信息。因此,通过无anchor特征表示构建的地平面特征图避免了来自不准确anchor box的汇集,并且仍然包含来自2D图像的足够信息用于检测。
3.1.3 Perspective transformation
为了检索无anchor点表示,我们用透视变换投影特征图。3D位置(x,y,z)和2D图像像素坐标(u,v)之间的转换通过

其中 s s s是实值比例因子, P θ P_θ Pθ是3 × 4透视变换矩阵。具体来说,A是3 × 3内参数矩阵。 [ R ∣ t ] [R|t] [R∣t]是3 × 4联合旋转——平移矩阵,或外部参数矩阵,其中 R R R指定旋转, t t t指定平移。
图像中的一个点(像素)位于3D世界中的一条线上。为了确定图像像素的精确3D位置,我们考虑一个公共参考平面:地平面,z=0。对于地平面上的所有3D位置 ( x , y , 0 ) (x, y, 0) (x,y,0),逐点变换可以写成
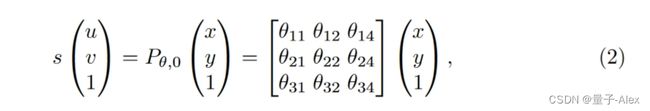
其中 P θ , 0 P_{θ,0} Pθ,0表示从 P θ P_θ Pθ中取消第三列的3 × 3透视变换矩阵。
为了在神经网络中实现这一点,我们将接地层位置量化为形状为 [ H g , W g ] [H_g, W_g] [Hg,Wg]的网格。对于相机 n ∈ { 1 , . . . , N } n ∈ \{1, . . . , N \} n∈{1,...,N},具有校准 θ ( n ) θ^{(n)} θ(n),我们可以通过基于等式2应用形状为 [ H g , W g ] [H_g, W_g] [Hg,Wg]的参数化采样网格,将图像投影到z=0接地平面上。这些采样网格在地平面上生成投影特征图,其中剩余的(看不见的)位置用零填充(图4)。我们连接了一个双通道坐标图[20]来指定接地层位置的X-Y坐标(图2)。连同来自N个摄像机的投影C通道特征图,我们有一个(N × C+2)通道地平面特征图。
3.1.4 Different projection choices
对于多视图聚合,投影有多种选择:我们可以投影RGB图像、要素图或单视图结果(图5)。首先,RGB像素本身包含的信息相对较少,许多信息保留在空间结构中。但是,投影会破坏相邻RGB像素之间的空间关系。因此,这限制了多视图检测器的性能。第二,投影单个视图结果(检测到的脚点)限制了要聚合的信息。事实上,在这种设置中,除了单视图检测结果之外,系统无法访问其他线索。由于单视图结果在遮挡下可能不准确(这是引入多视图的原因),这种设置也会限制整体性能。在本文中,我们建议投影特征图。
与其他选择相比,要素图不仅较少遭受空间结构断裂(因为2D空间信息已经集中到要素图中的单个像素中),而且包含更多信息。如图5所示,经由特征图投影的聚合实现最高的MODA[15]性能。
3.2 Spatial aggregation
在上一节中,我们展示了多视图信息可以通过透视转换和连接以无anchor的方式聚合。剩下的一个问题是如何从空间邻居中聚合信息。
遮挡是由一定区域内的人群产生的。为了处理这些模糊性,人们可以联合考虑某个区域和该区域中的人群,以做出总体明智的决策。以前采用CRFs和平均场推断,但是除了CNN之外还需要设计和操作。在这项工作中,我们提出了一个完全卷积的替代方案,在地平面特征图上具有大核卷积。事实上,郑等人。[47]发现CNN可以模拟CRF的一些行为和特征。还有彭等人。[26]在语义分割方面优于具有大核卷积的CRF。在MVDet中,我们将(N × C+2)通道地平面特征图馈送到具有相对较大感受野的卷积层,以便共同考虑地平面邻居。这里,我们使用三层扩张卷积来具有最小的参数,同时仍然保持较大的接地层感受野。最后一层输出无激活的单通道 [ H g , W g ] [H_g, W_g] [Hg,Wg]行人占用图(POM)
4.算法
4.1 训练
我们将MVDet训练为一个回归问题。给定地面真实行人占用 g \mathbf{g} g,类似于地标检测[2],我们使用高斯核 f ( ⋅ ) f (·) f(⋅)生成“软”地面真实目标 f ( g ) f (g) f(g)。为了训练整个网络,我们使用网络输出 g ^ \hat {\mathbf{g}} g^和“软”目标 f ( g ) f (g) f(g)之间的欧几里德距离(Euclidean distance)为损失函数,
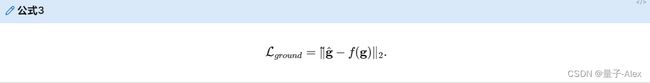
我们还包括来自N个摄像机输入的边界盒回归损失作为另一个监督。单视图头——脚检测也被训练为回归问题。对于单视图检测结果 s ^ h e a d ( n ) \hat {s}^{(n)}_{head} s^head(n) , s ^ f o o t ( n ) \hat {s}^{(n)}_{foot} s^foot(n)和视图 n ∈ { 1 , . . . , N } n ∈ \{1, ..., N \} n∈{1,...,N}中相应的地面实况 s h e a d ( n ) s^{(n)}_{head} shead(n) , s f o o t ( n ) s^{(n)}_{foot} sfoot(n),损失计算如下,

结合接地层损耗 L g r o u n d \mathcal{L}_{ground} Lground和N个单视图损耗 L s i n g l e n \mathcal{L}^{n}_{single} Lsinglen,我们得到用于训练MVDet的总损耗,

其中α是单视图损失权重的超参数。
4.2 测试
MVDet输出图 g ^ \hat g g^。的单通道占用概率我们以0.4的最小概率过滤占用图,然后对建议应用非最大抑制(NMS)。该NMS使用0.5米的欧几里德距离阈值,这与在评估中将该位置建议视为真阳性的阈值相同[3]。
5.数据集
我们在两个多视图行人检测数据集上进行测试(表1)。

Wildtrack数据集包括来自7台摄像机的400个同步帧,覆盖12米乘36米的区域。为了进行注释,接地层被量化为480 × 1440的网格,其中每个网格单元为2.5平方厘米。这7个摄像头以1080 × 1920的分辨率捕捉图像,并以每秒2帧(fps)的速度进行注释。平均而言,Wildtrack数据集中每帧有20个人,场景中的每个位置被3.74个摄像机覆盖。
MultiviewX数据集是为多视图行人检测收集的新合成数据集。我们使用Unity engine[37]来创建场景。至于行人,我们使用PersonX[34]的人体模型。MultiviewX数据集覆盖的区域略小,为16米乘25米。使用相同的2.5平方厘米的网格单元,我们将接地层量化为640 × 1000的网格。MultiviewX数据集中有6个视野重叠的摄像机,每个摄像机输出1080 × 1920分辨率的图像。我们还以2 fps的速度在MultiviewX中为400帧生成注释(与Wildtrack相同)。平均4.41个摄像头覆盖相同的位置。作为一个合成数据集,对于带有免费注释的场景,有各种潜在的配置。在默认设置下,MultiviewX每帧有40个人,使Wildtrack的拥挤程度增加了一倍。如果未指定,MultiviewX将引用此默认设置
6.实验结果
6.1 评估指标
评估指标。在[3]之后,我们使用两个数据集中的前90%帧进行训练,最后10%帧进行测试。我们报告精确度、召回率、MODA和MODP。MODP评估定位精度,而MODA考虑假阳性和假阴性[15]。我们使用MODA作为主要的性能指标,因为它同时考虑了误报和误报。0.5米的阈值用于确定真阳
6.2 实验设置
出于内存使用方面的考虑,我们将1080 × 1920 RGB图像降采样为Hi=720,Wi=1280。我们删除最后两层(全局平均池化;分类输出),并使用扩展卷积代替步进卷积。这导致720 × 1280输入的8 ×下采样。在投影之前,我们将特征图双线性插值为Hf=270,Wf=480的形状。对于4 ×下采样,对于Wildtrack和MultiviewX,接地层网格大小分别设置为Hg=120、Wg=360和Hg=160、Wg=250,其中每个像元代表一个10厘米见方。对于空间聚合,我们使用3个卷积层,具有3 × 3核和1,2,4的膨胀。这将使每个地平面位置(单元)的感受野增加到15 × 15平方单元,或1.5 × 1.5平方米。为了训练MVDet,我们使用动量为0.5、L2归一化为5 × 104的SGD优化器。单视图损失的权重α被设置为1。我们使用单周期学习速率调度器[31],最大学习速率设置为0.1,并在批量大小设置为1的情况下训练10个时期。我们在两个RTX-2080Ti GPU上完成了所有实验。
6.3 实验与实验结果
6.3.1 Method Comparisons
在表2中,我们比较了不同方法中的多视图聚合和空间聚合。对于多视图聚合,以前的方法要么投影单视图检测结果[41,8],要么使用多视图anchor box特征[4,1]。对于空间聚合,研究了聚类[41]、平均场推断[8,1]和CRF[1,29]。为了与以前的方法进行比较,我们为MVDet创建了以下变体。为了比较无anchor点聚合和基于anchor点的方法,我们创建了“MVDet(w/o large kernel)”,它删除了大核卷积。这个变体是作为与DeepMCD[4]的直接比较而创建的,两者都不包括空间聚合。为了比较不同的投影选择(第3.1节),我们包括两种变体,它们要么投影RGB图像像素“MVDet(投影图像)”,要么投影单视图检测结果“MVDet(投影结果)”。“MVDet(w/o large kernel)”也显示了空间聚合的有效性。所有变体都遵循与原始MVDet相同的训练协议。

6.3.2 Evaluation of MVDet
6.3.2.1 Comparison against state-of-the-art methods
在表3中,我们比较了MVDet与多种最先进的多视角行人检测方法的性能。由于有些方法没有可用的代码,为了在MultiviewX上进行公平的比较,我们尽可能地重新实现这些方法。在Wildtrack数据集上,MVDet实现了88.2%的MODA,比以前的技术水平提高了+14.1%。在MultiviewX数据集上,MVDet实现了83.9%的MODA,比我们实现的深度遮挡增加了8.7%[1]。MVDet在两个数据集上也实现了最高的MODP和召回率,但在精度方面略落后于深度遮挡。值得一提的是,DeepOcclusion在精度方面优于MVDet,但在召回率落后

这表明他们的CNN-CRF方法在抑制假阳性方面非常好,但有时有错过一些目标的趋势
6.3.2.2 Effectiveness of anchor-free multiview aggregation
即使没有空间聚合,“MVDet(w/o大内核)”在Wildtrack数据集上实现了76.9%的MODA,在MultiviewX数据集上实现了77.2%的MODA。事实上,它在两个数据集上分别略微超过当前最先进水平+2.8%和+2.0%。高性能证明了我们通过特征地图投影进行无anchor聚合的有效性。在第3.1节中,我们假设不准确的anchor box可能会导致不太准确的聚合特征,因此提出了一种无anchor方法。在表3中,我们通过比较基于anchor的DeepMCD[4]和无anchor的“MVDet(w/o大内核)”来证明我们的无anchor方法的有效性,两者都不包括空间聚合。MVDet的变体在Wildtrack数据集上比DeepMCD高9.1%,在MultiviewX数据集上比MODA高7.2%,这表明当anchor box不准确时,无anchor特征地图投影可以成为多视图行人检测中多视图聚合的更好选择。

与MultiviewX数据集上的多视图anchor定框要素相比,要素地图投影带来的改进较少(MultiviewX上的改进为+7.2%,而Wildtrack上的改进为+9.1%)。这是因为MultiviewX数据集有合成人,而Wildtrack捕捉的是真实世界的行人。自然,在现实世界的场景中,人类身高和宽度的差异更大,因为合成人的尺寸非常相似。这表明现实世界数据集Wildtrack的anchor定框平均不太精确。因此,通过要素地图投影进行聚合会对Wildtrack数据集带来更大的改进。
6.3.2.3 Comparison between different projection choices
在3.1节中,我们声称投影特征图是比投影RGB图像或单视图结果更好的选择。投影RGB图像破坏了像素之间的空间关系,单个RGB像素代表的信息很少。因此,在表3中,我们发现“MVDet(项目图像)”导致两个数据集的性能都很差(26.8%和19.5%MODA)。虽然单视图结果对投影的空间模式中断是鲁棒的,但是其中包含的信息是有限的。由于拥挤和遮挡,单视图检测可能会失去许多真正的阳性。因此,像“RCNN&聚类”[41]中那样对这些预测的单视图结果进行聚类被证明是极其困难的(11.3%和18.7%MODA)。用大核卷积“MVDet(项目结果)”替换聚类大大提高了性能(68.2%和73.2%MODA),因为它缓解了形成1大小聚类(只有一个组件的聚类,因为检测在遮挡中缺失)的问题,并且可以以端到端的方式进行训练。尽管如此,检测结果中的受限信息阻止了变体的更高性能。

6.3.2.4 Effectiveness of spatial aggregation via large kernel convolution
具有大核卷积的空间聚合在Wildtrack数据集上带来了+11.3%的MODA提升,在MultiviewX数据集上带来了+6.7%的性能提升。相比之下,使用CRF和meanfield推断的空间聚合在两个数据集上分别增加了+6.3%和+5.2%,从DeepMCD到Deep-Occlusion。我们并不断言基于CRF或基于CNN的方法的优越性。我们只是认为,所提出的基于CNN的方法可以有效地聚集空间邻居信息,以解决拥挤或遮挡引起的模糊性,而除了CNN之外,不需要任何设计或操作。如图6所示,大核卷积设法输出更类似于基本事实的结果。

图6。通过大核卷积实现空间聚合的有效性。与“MVDet(w/o大内核)”相比,MVDet输出的占用概率更接近地面事实,尤其是在突出显示的区域。
对于空间聚合,所提出的大核卷积和CRF对MultiviewX数据集的改进较小。如表1所示,即使MultiviewX数据集中的摄像机较少,但MultiviewX数据集中的每个接地层位置平均被更多的摄像机覆盖。对于MultiviewX数据集,每个位置平均被4.41个摄像机(视野)覆盖,而在Wildtrack中为3.74个。更多的摄像机覆盖通常会引入更多的信息并减少模糊度,这也限制了通过空间聚合解决模糊度的性能提升。

6.3.2.5 Influence of different crowdedness and occlusion levels
作为一个合成数据集,MultiviewX有多种可用配置。在图7(左)中,我们显示了在多个拥挤级别下的摄像机视图。随着场景拥挤程度的增加,遮挡也会增加。在图7中(右),我们展示了MVDet在多级遮挡下的性能。随着拥挤和遮挡的增加(更加困难),MVDet和MVDet“MVDet(w/o大内核)”的MODA都降低。此外,由于任务更具挑战性,以及严重的遮挡也会影响空间邻居,空间聚合的性能提升也会下降。

图7。不同拥挤配置下的MultiviewX数据集(左),以及相应的MVDet性能(右)
6.3.2.6 Influence of single view detection loss
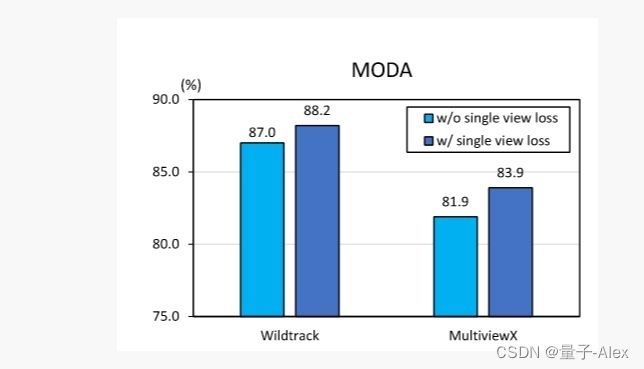
在MVDet的默认设置中,对于等式5中的综合损失。α被设定为1。在图8中,我们研究消除单视图损失的影响。在没有单视图检测损失的情况下,我们发现两个数据集的性能损失分别为-1.2%和-2.0%,这两个数据集仍然非常有竞争力。事实上,我们认为单视图足部检测损失不会进一步有利于系统,因为足部点已经在地平面上被监控。另一方面,头部点检测丢失会产生异构监控,从而进一步提高系统性能。如第3.1节和第4.4节所述,不太精确的边界框注释会限制Wildtrack数据集上单视图损失的性能增益。
7 研究结论
在本文中,我们研究了拥挤场景中的行人检测,通过结合多个摄像机视图。具体来说,我们专注于通过多视图聚合和空间聚合来解决由遮挡引起的模糊性,这是多视图行人检测的两个核心方面。对于多视图聚合,我们通过组合投影的特征图来采用无anchor的方法,而不是以前方法中基于anchor的方法。对于空间聚合,不同于以前除了CNN之外还需要设计和操作的方法,我们在完全卷积方法中应用大内核。提出的系统MVDet在Wildtrack数据集上实现了88.2%的MODA,比以前的最先进技术高出14.1%。在MultiviewX(一种用于多视图行人检测的新合成数据集)上,MVDet也取得了极具竞争力的结果。我们相信,建议的MVDet可以作为多视角行人检测的强大基线,鼓励相关领域的进一步研究。