SAP HANA性能优化(5)——查询优化器(SQL Optimizer)
一、SQL查询主要组件
这些组件主要包括会话(Session),SQL前端(SQL Frontend), SQL优化器(SQL Optimizer)和执行计划(Execution Plan)、SQL计划缓存(SQL Plan Cache)。
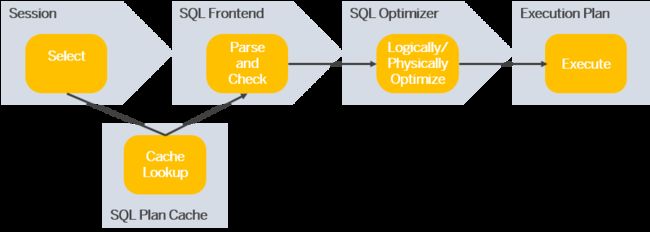
以下是对这些组件的概述:
会话层(Session):这是处理SQL查询的第一层,类似于API,可以创建具有不同属性的会话。这些会话后续用于创建新的事务和工作线程。
这是查询开始的地方,有点像接待处。当我们使用不同的客户端工作时,会创建具有不同属性的会话,就像不同的工作空间一样。
SQL前端(SQL Frontend):这是SQL语句的解析和检查发生的地方。在这里,语句被转换成编译器可以理解的形式,然后进行语法和语义的检查。如果SQL语句有错误,将会触发错误并导致语句执行失败。
这个环节主要是对我们的查询做初步的检查和理解,就像一个翻译员,确保我们的查询语法正确,语义明确。
查询优化器(SQL Optimizer):这是一个经过语言转换的基础对象,它的主要任务是优化查询,以提升运行速度并保证数据完整性。它首先应用一套逻辑重写规则来改进性能,然后进行成本枚举,以估算不同方案的成本。
这个环节的任务是找出执行查询的最好方式,就像我们的策略规划师,他会考虑多种可能的执行方案,然后选择一个最合适的。
执行器(Execution Plan):优化完成后,会创建执行计划并将其发送到执行引擎。SAP HANA有两种执行引擎,行引擎和列引擎。行引擎是一个通用的处理引擎,列引擎是SAP HANA特有的,以列为单位处理数据。
这个环节就是真正去执行我们的查询,它会根据优化器给出的方案,将任务分配给两种不同的引擎,行引擎和列引擎,来完成实际的工作。
SQL计划缓存(SQL Plan Cache):这是存储查询计划的地方,旨在最小化查询的编译时间。它的底层是监视视图M_SQL_PLAN_CACHE,这是一个大表,主键包括用户、会话、模式、语句等。搜索特定的缓存条目或保证查询有缓存命中,需要输入正确的键值。管理SQL计划缓存需要在缓存存储大小和频繁的缓存命中之间取得平衡。
这是一个存储查询方案的空间,如果我们的查询经常用到,就可以把它存起来,下次就可以直接用,不用再重新计划,就像我们的小秘书一样,帮我们记住了一些常用的东西,方便我们下次直接用。
今天主要聊一聊优化器。
二、SQLScript优化器
SQLScript优化器规则:SAP HANA的SQLScript优化器通常遵循四种规则来提高查询的效率和性能。
常量传播:这个规则关注于评估和折叠常量SQL表达式,并将这个计算出的值通过整个值链进行传播。
存储过程展平:这个规则是将被调用的SQLScript过程的主体展开到调用它的SQLScript过程的主体中,降低复杂性。
SQL语句内联:基于依赖性分析,优化器决定是否应当将语句内联或并行执行。如果语句间有依赖关系,优化器会将它们重塑为一个内联的单一语句,从而从SQL查询优化器中获取额外的好处,如基于成本的优化。如果查询间没有依赖关系,这些查询将会并行执行。
控制流简化:这个规则涉及到死代码消除。优化器会移除那些在SQLScript过程中,生成的结果永远不会被使用的语句,和那些在常量传播后,条件评估为假的不可达分支。
官网上举了一个例子对这些规则进行说明:
--这段代码创建了一个名为TAB1的表,并插入数据
CREATE TABLE TAB1 (MATERIAL NVARCHAR(10), FABRIC_ID NVARCHAR(10));
INSERT INTO TAB1 VALUES ('ABC' , 'BI');
INSERT INTO TAB1 VALUES ('CDE' , 'BI2');
INSERT INTO TAB1 VALUES ('CDE' , 'BI');
--这段代码创建了一个名为T_RESULT的表类型
CREATE TYPE T_RESULT AS TABLE (MATERIAL NVARCHAR(10), FABRIC_ID NVARCHAR(10));
/*
创建一个名为P2的存储过程,它有一个输入参数F2,一个输出参数T_RESULT。
存储过程中如果F2等于'TA',则V_F_ID被赋值为'BI'。
然后从TAB1表中选择所有不重复的MATERIAL和FABRIC_ID,要么V_F_ID为空,要么等于FABRIC_ID。
最后从选择的结果中选择所有字段并按MATERIAL排序,结果赋值给T_RESULT。
*/
CREATE PROCEDURE P2(IN F2 NVARCHAR(13), OUT T_RESULT TAB1)
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
IF :F2 = 'TA' THEN
V_F_ID = 'BI';
END IF;
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
END;
/*
创建了一个名为P1的存储过程,它有一个输入参数F1。存储过程中调用了P2存储过程,并将结果赋值给了COMPOSITION。然后从COMPOSITION中选择所有字段并按MATERIAL排序。
*/
CREATE PROCEDURE P1(IN F1 NVARCHAR(13))
AS BEGIN
CALL P2(:F1, :COMPOSITION);
SELECT * FROM :COMPOSITION ORDER BY MATERIAL;
END;
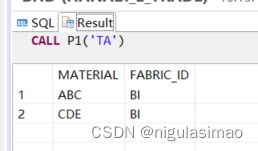
--执行存储过程
CALL P1('TA');
2.1 常量传播(Constant propagation)
在调用P1过程时,输入参数F1的值被指定为'TA'。在SQLScript优化器中,它将所有的F1实例替换为常量值'TA',这就是所谓的"常量传播"。替换后,原来的CALL P2(:F1, :COMPOSITION)变为了CALL P2('TA', :COMPOSITION)。这样可以使得存储过程P1中的SQL代码更加高效,因为不再需要在运行时解析和替换变量F1。
优化前:
AS BEGIN
CALL P2(:F1, :COMPOSITION);
SELECT * FROM :COMPOSITION ORDER BY MATERIAL;
END;优化后:
AS BEGIN
CALL P2('TA', :COMPOSITION);
SELECT * FROM :COMPOSITION ORDER BY MATERIAL;
END;
同样,对于存储过程P2,因为它是由存储过程P1调用的,所以输入参数F2的值也被指定为'TA'。在优化器中,它将所有的F2实例也替换为常量值'TA'。所以,原来的IF :F2 = 'TA' THEN变为了IF 'TA' = 'TA' THEN。这样可以使得存储过程P2中的SQL代码更加高效,因为不再需要在运行时解析和替换变量F2。
优化前
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
IF :F2 = 'TA' THEN
V_F_ID = 'BI';
END IF;
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
END;优化后
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
IF 'TA' = 'TA' THEN
V_F_ID = 'BI';
END IF;
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
END;2.2 存储过程展平(Procedure flattening)
存储过程展平是一种优化技术,它可以将一个被调用的存储过程的主体直接解开并插入到调用该存储过程的地方。这样可以避免存储过程调用的开销,并且有可能进行更多的优化。
在这个例子中,存储过程P2被存储过程P1调用。通过存储过程展平,原来调用P2的语句CALL P2('TA', :COMPOSITION);被替换为P2的主体。同时,输出参数:COMPOSITION也被相应地改为:T_RESULT。
优化前
AS BEGIN
CALL P2('TA', :COMPOSITION);
SELECT * FROM :COMPOSITION :T_RESULT ORDER BY MATERIAL;
END;优化后
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
IF 'TA' = 'TA' THEN
V_F_ID = 'BI';
END IF;
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;这样,存储过程P1的执行就不再需要调用存储过程P2,从而减少了存储过程调用的开销。同时,因为存储过程P2的主体被直接插入到了P1中,所以可能有更多的优化机会。
2.3 控制流简化
这段话描述了控制流简化的优化过程,这是一种通过消除不必要的分支条件来优化代码的方法。
在这个例子中,因为 'TA' = 'TA' 总是为真,所以这个IF语句不会产生任何效果,可以被移除。
优化前
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
IF 'TA' = 'TA' THEN
V_F_ID = 'BI';
END IF;
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;优化后
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
V_F_ID = 'BI';
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;2.4 控制流简化之后,再次进行常量传播
在控制流简化之后,V_F_ID总是被赋予'BI',这是一个固定的常量值。因此,DECLARE V_F_ID的声明语句可以被移除,并且在后续的代码中,V_F_ID可以被替换为'BI'。
优化前
AS BEGIN
DECLARE V_F_ID NVARCHAR(13);
V_F_ID = 'BI';
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE :V_F_ID = '' OR :V_F_ID = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;优化后
AS BEGIN
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE 'BI' = '' OR 'BI' = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;
2.5 SQL语句内联优化
SQL语句内联是一种将多个SQL语句合并为一个单一SQL语句的技术,它可以通过使用WITH子句来实现。这样可以减少数据库查询的次数,提高SQL执行的效率。
在这个例子中,存储过程P1中的三个SQL语句被合并为一个单一的SQL语句。
优化前
AS BEGIN
T_TABLE = SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE 'BI' = '' OR 'BI' = FABRIC_ID;
T_RESULT = SELECT * FROM :T_TABLE ORDER BY MATERIAL;
SELECT * FROM :T_RESULT ORDER BY MATERIAL;
END;优化后
AS BEGIN
WITH "_SYS_T_TABLE_2" AS
(SELECT DISTINCT MATERIAL, FABRIC_ID FROM TAB1
WHERE 'BI' = '' OR 'BI' = FABRIC_ID),
"_SYS_T_RESULT_1" AS
(SELECT * FROM "_SYS_T_TABLE_2" "T_TABLE"
ORDER BY MATERIAL)
SELECT * FROM "_SYS_T_RESULT_1" "COMPOSITION"
ORDER BY MATERIAL;
END;我们可以看到经过一系列的优化(包括常量传播、存储过程展平、控制流简化、再次常量传播和SQL语句内联)之后,原来的CALL P1('TA')命令最终被重新编译和优化。
参考文档:hana优化官方文档