【论文精读】RetNet
摘要
Transformer是大型语言模型的主流架构。然而,transformer的训练并行性是以低效的推理为代价,这使得transformer对部署不友好。不断增长的序列长度会增加GPU内存消耗和延迟,并降低推理速度。许多算法都在继续开发下一代架构,旨在保持训练并行性和transformer的竞争性能,同时具有高效的 O ( 1 ) O(1) O(1)推理复杂度。但同时实现上述目标是具有挑战性的,即所谓的不可能三角形(如下图)。

本文提出的算法同时具备低成本的推理、高效的长序列建模、与transformer相当的性能,并同时进行并行模型训练。引入了一种Multi-Scale Retention机制来替代多头注意力,该机制有三种计算范式,即并行、循环和chunkwise循环表示。
-
并行表示使训练并行性能够充分利用GPU设备
-
递归表示能够在内存和计算方面有效地进行O(1)推理。这样可以显著降低部署成本和延迟
-
块递归表示可以进行高效的长序列建模。并行编码每个局部块以提高计算速度,同时反复编码全局块以节省GPU内存
框架
Retention
给定输入序列 { x i } i = 1 ∣ x ∣ \{{x_i}\}^{|x|}_{i=1} {xi}i=1∣x∣,经过embedding层得到词嵌入向量 [ x 1 , … , x ∣ x ∣ ] ∈ R ∣ x ∣ × d [x_1,\dots,x_{|x|}]\in \Reals^{|x|\times d} [x1,…,x∣x∣]∈R∣x∣×d, d d d为词嵌入维度。对词嵌入向量 X ∈ R ∣ x ∣ × d X\in\Reals^{|x|\times d} X∈R∣x∣×d中的时间步 n n n的向量 X n ∈ R 1 × d X_n\in\Reals^{1\times d} Xn∈R1×d乘以权值 w v ∈ R d × d w_v\in \Reals ^ {d \times d} wv∈Rd×d得到 v n ∈ R 1 × d v_n\in\Reals^{1\times d} vn∈R1×d:
v n = X n ⋅ w v v_n=X_n\cdot w_v vn=Xn⋅wv
乘以可学习权值 W Q ∈ R d × d W_Q\in \Reals ^ {d \times d} WQ∈Rd×d、 W K ∈ R d × d W_K\in \Reals ^ {d \times d} WK∈Rd×d得到query、key向量 Q ∈ R ∣ x ∣ × d Q\in \Reals ^ {|x| \times d} Q∈R∣x∣×d、 K ∈ R ∣ x ∣ × d K\in \Reals ^ {|x| \times d} K∈R∣x∣×d:
Q = X W Q , K = X W K Q=XW_Q,K=XW_K Q=XWQ,K=XWK
假设上述计算为序列建模问题,通过状态转移迭代计算,状态 s n ∈ R d × d s_n\in\Reals^{d\times d} sn∈Rd×d将 v n v_n vn映射为 o n o_n on向量,则有:
s n = A s n − 1 + K n T v n s_n=As_{n-1}+K^T_nv_n sn=Asn−1+KnTvn
o n = Q n s n = Q n ( A s n − 1 + K n T v n ) = Q n ( A ( A s n − 2 + K n − 1 T v n − 1 ) + K n T v n ) = Q n ( A 2 s n − 2 + A 1 K n − 1 T v n − 1 + A 0 K n T v n ) = Q n ( A 2 ( A s n − 3 + K n − 2 T v n − 2 ) + A 1 K n − 1 T v n − 1 + A 0 K n T v n ) = Q n ( A 3 s n − 3 + A 2 K n − 2 T v n − 2 + A 1 K n − 1 T v n − 1 + A 0 K n T v n ) o_n =Q_ns_n \\ =Q_n(As_{n-1}+K^T_nv_n) \\ =Q_n(A(As_{n-2}+K^T_{n-1}v_{n-1})+K^T_nv_n) \\ =Q_n(A^2s_{n-2}+A^1K^T_{n-1}v_{n-1}+A^0K^T_nv_n) \\ =Q_n(A^2(As_{n-3}+K^T_{n-2}v_{n-2})+A^1K^T_{n-1}v_{n-1}+A^0K^T_nv_n) \\ =Q_n(A^3s_{n-3}+A^2K^T_{n-2}v_{n-2}+A^1K^T_{n-1}v_{n-1}+A^0K^T_nv_n) on=Qnsn=Qn(Asn−1+KnTvn)=Qn(A(Asn−2+Kn−1Tvn−1)+KnTvn)=Qn(A2sn−2+A1Kn−1Tvn−1+A0KnTvn)=Qn(A2(Asn−3+Kn−2Tvn−2)+A1Kn−1Tvn−1+A0KnTvn)=Qn(A3sn−3+A2Kn−2Tvn−2+A1Kn−1Tvn−1+A0KnTvn)
其中 A ∈ R d × d A\in\Reals^{d\times d} A∈Rd×d为位置嵌入矩阵, Q n ∈ R 1 × d Q_n\in \Reals ^ {1 \times d} Qn∈R1×d、 K n ∈ R 1 × d K_n\in\Reals^{1\times d} Kn∈R1×d为时间步 n n n的query、key投影向量。因为 A 0 A^0 A0为单位阵,假设初始状态 s 0 s_0 s0为全0矩阵,则有:
s 1 = A s 0 + K 1 T v 1 = K 1 T v 1 s_1=As_0+K^T_1v_1=K^T_1v_1 s1=As0+K1Tv1=K1Tv1
则:
o n = Q n ( A 3 s n − 3 + A 2 K n − 2 T v n − 2 + A 1 K n − 1 T v n − 1 + A 0 K n T v n ) = Q n ( A n − ( n − 3 ) s n − 3 + A n − ( n − 2 ) K n − 2 T v n − 2 + A n − ( n − 1 ) K n − 1 T v n − 1 + A n − n K n T v n ) o_n= Q_n(A^3s_{n-3}+A^2K^T_{n-2}v_{n-2}+A^1K^T_{n-1}v_{n-1}+A^0K^T_nv_n) \\ =Q_n(A^{n-(n-3)}s_{n-3}+A^{n-(n-2)}K^T_{n-2}v_{n-2}+A^{n-(n-1)}K^T_{n-1}v_{n-1}+A^{n-n}K^T_nv_n) on=Qn(A3sn−3+A2Kn−2Tvn−2+A1Kn−1Tvn−1+A0KnTvn)=Qn(An−(n−3)sn−3+An−(n−2)Kn−2Tvn−2+An−(n−1)Kn−1Tvn−1+An−nKnTvn)
归纳得:
o n = Q n ( A n − 1 K 1 T v 1 + A n − 2 K 2 T v 2 + ⋯ + A n − ( n − 2 ) K n − 2 T v n − 2 + A n − ( n − 1 ) K n − 1 T v n − 1 + A n − n K n T v n ) = ∑ m = 1 n Q n A n − m K m T v m o_n= Q_n(A^{n-1}K^T_{1}v_{1}+A^{n-2}K^T_{2}v_{2}+\dots+A^{n-(n-2)}K^T_{n-2}v_{n-2}+A^{n-(n-1)}K^T_{n-1}v_{n-1}+A^{n-n}K^T_nv_n) \\ =\sum^{n}_{m=1}Q_nA^{n-m}K^T_mv_m on=Qn(An−1K1Tv1+An−2K2Tv2+⋯+An−(n−2)Kn−2Tvn−2+An−(n−1)Kn−1Tvn−1+An−nKnTvn)=m=1∑nQnAn−mKmTvm
给定对角化相对位置嵌入矩阵 A = Λ ( γ e i θ ) Λ − 1 A=\Lambda(\gamma e^{i\theta})\Lambda^{-1} A=Λ(γeiθ)Λ−1,其中 γ , θ ∈ R d \gamma ,\theta \in \Reals^d γ,θ∈Rd, Λ \Lambda Λ为可逆矩阵, e i θ = c o s x + i s i n x e^{i\theta}=cos\ x+i \ sin\ x eiθ=cos x+i sin x,因为 θ = [ θ 1 , … , θ d ] \theta=[\theta_1,\dots,\theta_d] θ=[θ1,…,θd],则有:
e i θ = [ c o s θ 1 , s i n θ 2 , … , c o s θ d − 1 , s i n θ d ] e^{i\theta}=[cos\ \theta_1,sin\ \theta_2,\dots,cos\ \theta_{d-1},sin\ \theta_d] eiθ=[cos θ1,sin θ2,…,cos θd−1,sin θd]
γ e i θ \gamma e^{i\theta} γeiθ是对角阵,对角元素的值为对应将 γ \gamma γ和 e i θ e^{i\theta} eiθ转成复数向量相乘再将结果转回实数向量的结果。又因为 Λ \Lambda Λ为可逆矩阵有 Λ − 1 Λ = I \Lambda^{-1}\Lambda=I Λ−1Λ=I,则有:
A n − m = ( Λ ( γ e i θ ) Λ − 1 ) n − m = Λ ( γ e i θ ) Λ − 1 Λ ( γ e i θ ) Λ − 1 … Λ ( γ e i θ ) Λ − 1 Λ ( γ e i θ ) Λ − 1 = Λ ( γ e i θ ) n − m Λ − 1 A^{n-m}=(\Lambda(\gamma e^{i\theta})\Lambda^{-1})^{n-m} \\ =\Lambda(\gamma e^{i\theta})\Lambda^{-1}\Lambda(\gamma e^{i\theta})\Lambda^{-1}\dots\Lambda(\gamma e^{i\theta})\Lambda^{-1}\Lambda(\gamma e^{i\theta})\Lambda^{-1} \\ =\Lambda(\gamma e^{i\theta})^{n-m}\Lambda^{-1} An−m=(Λ(γeiθ)Λ−1)n−m=Λ(γeiθ)Λ−1Λ(γeiθ)Λ−1…Λ(γeiθ)Λ−1Λ(γeiθ)Λ−1=Λ(γeiθ)n−mΛ−1
则有:
o n = ∑ m = 1 n Q n A n − m K m T v m = ∑ m = 1 n Q n ( Λ ( γ e i θ ) n − m Λ − 1 ) K m T v m = ∑ m = 1 n X n W Q Λ ( γ e i θ ) n − m Λ − 1 W K T X m T v m o_n=\sum^{n}_{m=1}Q_nA^{n-m}K^T_mv_m \\ = \sum^{n}_{m=1}Q_n(\Lambda(\gamma e^{i\theta})^{n-m}\Lambda^{-1})K^T_mv_m \\ = \sum^{n}_{m=1}X_nW_Q\Lambda(\gamma e^{i\theta})^{n-m}\Lambda^{-1}W^T_KX^T_mv_m on=m=1∑nQnAn−mKmTvm=m=1∑nQn(Λ(γeiθ)n−mΛ−1)KmTvm=m=1∑nXnWQΛ(γeiθ)n−mΛ−1WKTXmTvm
因为 Λ \Lambda Λ、 W Q W_Q WQ、 W K W_K WK都为可学习向量,故融合得:
o n = ∑ m = 1 n Q n ( γ e i θ ) n − m K m T v m = ∑ m = 1 n Q n ( γ e i θ ) n ( γ e i θ ) − m K m T v m = ∑ m = 1 n Q n ( γ e i θ ) n ( K m ( γ e i θ ) − m ) T v m = ∑ m = 1 n Q n ( γ n e i n θ ) ( K m ( γ − m e i ( − m ) θ ) ) T v m o_n= \sum^{n}_{m=1}Q_n(\gamma e^{i\theta})^{n-m}K^T_mv_m \\ =\sum^{n}_{m=1}Q_n(\gamma e^{i\theta})^n(\gamma e^{i\theta})^{-m}K^T_mv_m \\ =\sum^{n}_{m=1}Q_n(\gamma e^{i\theta})^n(K_m(\gamma e^{i\theta})^{-m})^Tv_m \\ =\sum^{n}_{m=1}Q_n(\gamma^n e^{in\theta})(K_m(\gamma^{-m} e^{i({-m})\theta}))^Tv_m on=m=1∑nQn(γeiθ)n−mKmTvm=m=1∑nQn(γeiθ)n(γeiθ)−mKmTvm=m=1∑nQn(γeiθ)n(Km(γeiθ)−m)Tvm=m=1∑nQn(γneinθ)(Km(γ−mei(−m)θ))Tvm
设 γ \gamma γ为实数常量,则有:
o n = ∑ m = 1 n γ n − m ( Q n e i n θ ) ( K m e i ( − m ) θ ) T v m o_n= \sum^{n}_{m=1}\gamma^{n-m}( Q_ne^{in\theta})(K_me^{i({-m})\theta})^Tv_m on=m=1∑nγn−m(Qneinθ)(Kmei(−m)θ)Tvm
因为 c o s ( − θ ) = c o s θ cos(-\theta)=cos \ \theta cos(−θ)=cos θ、 s i n ( − θ ) = − s i n θ sin(-\theta)=-sin \ \theta sin(−θ)=−sin θ,则:
e i ( − m ) θ = [ c o s − m θ 1 , s i n − m θ 2 , … , c o s − m θ d − 1 , s i n − m θ d ] = [ c o s m θ 1 , − s i n m θ 2 , … , c o s m θ d − 1 , − s i n m θ d ] e^{i({-m})\theta}=[cos\ -m\theta_1,sin\ -m\theta_2,\dots,cos\ -m\theta_{d-1},sin\ -m\theta_d] \\ =[cos\ m\theta_1,-sin\ m\theta_2,\dots,cos\ m\theta_{d-1},-sin\ m\theta_d] ei(−m)θ=[cos −mθ1,sin −mθ2,…,cos −mθd−1,sin −mθd]=[cos mθ1,−sin mθ2,…,cos mθd−1,−sin mθd]
复数形式为:
e i ( − m ) θ = [ c o s m θ 1 − s i n m θ 2 , … , c o s m θ d − 1 − s i n m θ d ] e^{i({-m})\theta}= [cos\ m\theta_1-sin\ m\theta_2,\dots,cos\ m\theta_{d-1}-sin\ m\theta_d] ei(−m)θ=[cos mθ1−sin mθ2,…,cos mθd−1−sin mθd]
因为:
e i m θ = [ c o s m θ 1 + s i n m θ 2 , … , c o s m θ d − 1 + s i n m θ d ] e^{im\theta}= [cos\ m\theta_1+sin\ m\theta_2,\dots,cos\ m\theta_{d-1}+sin\ m\theta_d] eimθ=[cos mθ1+sin mθ2,…,cos mθd−1+sin mθd]
即 e i ( − m ) θ e^{i({-m})\theta} ei(−m)θ为 e i m θ e^{im\theta} eimθ的共轭。故得:
o n = ∑ m = 1 n γ n − m ( Q n e i n θ ) ( K m e i m θ ) † v m o_n= \sum^{n}_{m=1}\gamma^{n-m}( Q_ne^{in\theta})(K_me^{im\theta})^\dag v_m on=m=1∑nγn−m(Qneinθ)(Kmeimθ)†vm
Retention的并行训练表示
单个时间步 n n n得输出为:
o n = ∑ m = 1 n γ n − m ( Q n e i n θ ) ( K m e i m θ ) † v m o_n= \sum^{n}_{m=1}\gamma^{n-m}( Q_ne^{in\theta})(K_me^{im\theta})^\dag v_m on=m=1∑nγn−m(Qneinθ)(Kmeimθ)†vm
转换为矩阵的并行表示为:
Q = ( X W Q ) ⊙ Θ , K = ( X W K ) ⊙ Θ ˉ , V = X W V Q=(XW_Q)\odot\Theta,K=(XW_K)\odot\=\Theta,V=XW_V Q=(XWQ)⊙Θ,K=(XWK)⊙Θˉ,V=XWV
Θ n = e i n θ , D n m = { γ n − m , n ≥ m 0 , n < m \Theta_n=e^{in\theta},D_{nm}=\begin{cases} \gamma^{n-m}, \ n \geq m \\ 0, \ n
R e t e n t i o n ( X ) = ( Q K T ⊙ D ) V Retention(X)=(QK^T\odot D)V Retention(X)=(QKT⊙D)V
其中 V , Q , K , Θ ∈ R ∣ x ∣ × d V,Q,K,\Theta\in \Reals^{|x| \times d} V,Q,K,Θ∈R∣x∣×d, D ∈ R ∣ x ∣ × ∣ x ∣ D \in \Reals^{|x| \times |x|} D∈R∣x∣×∣x∣为下三角阵, ⊙ \odot ⊙为点乘。该并行表示能够有效地使用gpu训练模型。
Θ , Θ ˜ \Theta,\~\Theta Θ,Θ˜为相对位置嵌入,其通过向量旋转将相对位置信息编码到 Q Q Q和 K K K矩阵的每个向量中。
D D D为因果遮蔽,可作为过去位置的指数衰减加权方案。对于 n < m n
Retention的推理循环表示
因为:
o n = ∑ m = 1 n γ n − m ( Q n e i n θ ) ( K m e i m θ ) † v m = Q n e i n θ ( ∑ m = 1 n γ n − m ( K m e i m θ ) † v m ) = Q n e i n θ ( γ n − n ( K n e i n θ ) † v n + ∑ m = 1 n − 1 γ n − m ( K m e i m θ ) † v m ) = Q n e i n θ ( ( K n e i n θ ) † v n + γ n − ( n − 1 ) ( K n − 1 e i ( n − 1 ) θ ) † v n − 1 + ∑ m = 1 n − 2 γ n − m ( K m e i m θ ) † v m ) = Q n e i n θ ( ( K n e i n θ ) † v n + γ ( ( K n − 1 e i ( n − 1 ) θ ) † v n − 1 + ∑ m = 1 n − 2 γ n − m − 1 ( K m e i m θ ) † v m ) ) o_n= \sum^{n}_{m=1}\gamma^{n-m}( Q_ne^{in\theta})(K_me^{im\theta})^\dag v_m \\ =Q_ne^{in\theta}(\sum^{n}_{m=1}\gamma^{n-m}(K_me^{im\theta})^\dag v_m) \\ =Q_ne^{in\theta}(\gamma^{n-n}(K_ne^{in\theta})^\dag v_n+\sum^{n-1}_{m=1}\gamma^{n-m}(K_me^{im\theta})^\dag v_m) \\ =Q_ne^{in\theta}((K_ne^{in\theta})^\dag v_n+\gamma^{n-(n-1)}(K_{n-1}e^{i(n-1)\theta})^\dag v_{n-1}+\sum^{n-2}_{m=1}\gamma^{n-m}(K_me^{im\theta})^\dag v_m) \\ =Q_ne^{in\theta}((K_ne^{in\theta})^\dag v_n+\gamma((K_{n-1}e^{i(n-1)\theta})^\dag v_{n-1}+\sum^{n-2}_{m=1}\gamma^{n-m-1}(K_me^{im\theta})^\dag v_m)) on=m=1∑nγn−m(Qneinθ)(Kmeimθ)†vm=Qneinθ(m=1∑nγn−m(Kmeimθ)†vm)=Qneinθ(γn−n(Kneinθ)†vn+m=1∑n−1γn−m(Kmeimθ)†vm)=Qneinθ((Kneinθ)†vn+γn−(n−1)(Kn−1ei(n−1)θ)†vn−1+m=1∑n−2γn−m(Kmeimθ)†vm)=Qneinθ((Kneinθ)†vn+γ((Kn−1ei(n−1)θ)†vn−1+m=1∑n−2γn−m−1(Kmeimθ)†vm))
令:
Q n = Q n e i n θ Q_n=Q_ne^{in\theta} Qn=Qneinθ
S n − 1 = ( K n − 1 e i ( n − 1 ) θ ) † v n − 1 + ∑ m = 1 n − 2 γ n − m − 1 ( K m e i m θ ) † v m S_{n-1}=(K_{n-1}e^{i(n-1)\theta})^\dag v_{n-1}+\sum^{n-2}_{m=1}\gamma^{n-m-1}(K_me^{im\theta})^\dag v_m Sn−1=(Kn−1ei(n−1)θ)†vn−1+m=1∑n−2γn−m−1(Kmeimθ)†vm
K n T V n = ( K n e i n θ ) † v n K^T_nV_n=(K_ne^{in\theta})^\dag v_n KnTVn=(Kneinθ)†vn
则有循环表示:
S n = γ S n − 1 + K n T V n S_n=\gamma S_{n-1}+K^T_nV_n Sn=γSn−1+KnTVn
R e t e n t i o n ( X n ) = Q n S n , n = 1 , … , ∣ x ∣ Retention(X_n)=Q_nS_n, \ n=1,\dots,|x| Retention(Xn)=QnSn, n=1,…,∣x∣
即为下图过程,先计算 K n K_n Kn和 V n V_n Vn相乘然后一直累加到状态矩阵 S n S_n Sn 上,最后再和 Q n Q_n Qn 相乘,这有利于推理。

Chunkwise递归表示
并行表征和循环表征的混合形式可以加速训练,将输入序列划分为若干小块。块内按照并行表示进行计算。跨块信息则按照循环表示进行传递。令 B B B表示块长度,通过以下方式计算第 i i i个分块 x [ i ] = [ x ( i − 1 ) B + 1 , … , x i B ] x_{[i]}=[x_{(i-1)B+1},\dots,x_{iB}] x[i]=[x(i−1)B+1,…,xiB]的retention输出:
Q [ i ] = Q B i : B ( i + 1 ) , K [ i ] = K B i : B ( i + 1 ) , V [ i ] = V B i : B ( i + 1 ) Q_{[i]}=Q_{Bi:B(i+1)},K_{[i]}=K_{Bi:B(i+1)},V_{[i]}=V_{Bi:B(i+1)} Q[i]=QBi:B(i+1),K[i]=KBi:B(i+1),V[i]=VBi:B(i+1)
R i = K [ i ] T ( V [ i ] ⊙ ζ ) + γ B R i − 1 , ζ i j = γ B − i − 1 R_i=K^T_{[i]}(V_{[i]}\odot\zeta)+\gamma^BR_{i-1},\zeta_{ij}=\gamma^{B-i-1} Ri=K[i]T(V[i]⊙ζ)+γBRi−1,ζij=γB−i−1
R e t e n t i o n ( X [ i ] ) = ( Q [ i ] K [ i ] T ⊙ D ) V [ i ] ⏟ I n n e r − C h u n k + ( Q [ i ] R i − 1 ) ⊙ ξ ⏟ C r o s s − C h u n k , ξ i j = γ i + 1 Retention(X_{[i]})=\underbrace{(Q_{[i]}K^T_{[i]}\odot D)V_{[i]}}_{Inner-Chunk}+\underbrace{(Q_{[i]}R_{i-1})\odot \xi}_{Cross-Chunk},\xi_{ij}=\gamma^{i+1} Retention(X[i])=Inner−Chunk (Q[i]K[i]T⊙D)V[i]+Cross−Chunk (Q[i]Ri−1)⊙ξ,ξij=γi+1
Gated Multi-Scale Retention
Multi-Scale Retention(MSR)每层中可以使用 h = d m o d e l / d h = d_{model}/d h=dmodel/d个Retention head,其中 d d d是head的维度,每个head使用不同的参数矩阵 W Q , W K , W V ∈ R d × d W_Q, W_K, W_V ∈ \Reals^{ d×d} WQ,WK,WV∈Rd×d。为每个head分配不同的 γ \gamma γ,不同层之间 γ \gamma γ相同。此外,添加swish gate来增加保留层的非线性。给定输入 X X X,将单一层定义为:
γ = 1 − 2 − 5 − a r a n g e ( 0 , h ) ∈ R h \gamma=1-2^{-5-arange(0,h)} \in \Reals^h γ=1−2−5−arange(0,h)∈Rh
h e a d i = R e t e n t i o n ( X , γ i ) head_i=Retention(X,\gamma_i) headi=Retention(X,γi)
Y = G r o u p N o r m h ( C o n c a t ( h e a d 1 , … , h e a d h ) ) Y=GroupNorm_h(Concat(head_1,\dots,head_h)) Y=GroupNormh(Concat(head1,…,headh))
M S R ( X ) = ( s w i s h ( X W G ) ⊙ Y ) W O MSR(X)=(swish(XW_G)\odot Y)W_O MSR(X)=(swish(XWG)⊙Y)WO
W G , W O ∈ R d m o d e l × d m o d e l W_G,W_O\in\Reals^{d_{model}\times d_{model}} WG,WO∈Rdmodel×dmodel为可学习参数,head使用多个 γ \gamma γ尺度,这将导致不同的方差,故用GroupNorm对每个头的输出分别标准化。整体流程如如下伪代码。

Retention Score 标准化
可以利用GroupNorm的尺度不变性来提高rentention层的数值精度。因为 G r o u p N o r m ( α ∗ h e a d i ) = G r o u p N o r m ( h e a d i ) GroupNorm(\alpha* head_i)=GroupNorm(head_i) GroupNorm(α∗headi)=GroupNorm(headi),在GroupNorm内乘以标量值不会影响输出和反向梯度。故对并行表示中的三个归一化因子,将 Q K T QK^T QKT标准化为 Q K T / d QK^T/ \sqrt d QKT/d ,将 D D D替换为 D ˜ n m = D n m / ∑ i = 1 n D n i \~D_{nm}=D_{nm}/ \sqrt{\textstyle\sum^n_{i=1}D_{ni}} D˜nm=Dnm/∑i=1nDni 。令 R = Q K T ⊙ D R=QK^T \odot D R=QKT⊙D表示Retention Score,将其标准化为 R ˜ n m = R n m / m a x ( ∣ ∑ i = 1 n R n i ∣ , 1 ) \~R_{nm}=R_{nm}/max(|\textstyle\sum^n_{i=1}R_{ni}|,1) R˜nm=Rnm/max(∣∑i=1nRni∣,1),则rentention输出变为 R e t e n t i o n ( X ) = R ˜ V Retention(X)=\~RV Retention(X)=R˜V。由于尺度不变性,上述技巧不会影响最终结果,同时能稳定前向和后向传递的数值流。
Retention 网络总体结构
对于 L L L层retnet,将MSR和FFN堆叠起来构建模型。形式上,输入序列 { x i } i = 1 ∣ x ∣ \{ {x_i}\}^{|x|}_{i=1} {xi}i=1∣x∣通过词嵌入层转换为向量。使用打包的嵌入 X 0 = [ x 1 , … , x ∣ x ∣ ] ∈ R ∣ x ∣ × d X^0 = [x_1, \dots, x_{|x|}] ∈\Reals^{ |x|×d} X0=[x1,…,x∣x∣]∈R∣x∣×d作为输入并计算模型输出 X L X^L XL:
Y l = M S R ( L N ( X l ) ) + X l Y^l=MSR(LN(X^l))+X^l Yl=MSR(LN(Xl))+Xl
X l + 1 = F F N ( L N ( Y l ) ) + Y l X^{l+1}=FFN(LN(Y^l))+Y^l Xl+1=FFN(LN(Yl))+Yl
其中 L N ( ⋅ ) LN(\cdot) LN(⋅)使LayerNorm, F F N ( X ) = g e l u ( X W 1 ) W 2 FFN(X)=gelu(XW_1)W_2 FFN(X)=gelu(XW1)W2, W 1 , W 2 W_1,W_2 W1,W2为参数矩阵。
训练
采用并行表示和Chunkwise递归表示训练。序列或块内的并行化可有效地利用gpu来加速计算。chunkwise递归对于长序列训练特别有用,在计算量和内存消耗方面都很高效。
推理
在推理过程中使用递归表示,可拟合自回归解码, O ( 1 ) O(1) O(1)复杂性度降低了内存和推理延迟。
实验
参数分配
论文重新分配MSR和FFN中的参数以进行公平的比较。在Transformers中,自注意力机制大约有 4 d 2 4d^2 4d2个参数,其中 W Q , W K , W V , W O ∈ R d × d W_Q,W_K,W_V,W_O\in \Reals^{d \times d} WQ,WK,WV,WO∈Rd×d。FFN中有 8 d 2 8d^2 8d2个参数,中间维度为 4 d 4d 4d。RetNet中的rentention有 8 d 2 8d^2 8d2个参数,其中 W Q , W K ∈ R d × d W_Q,W_K\in \Reals^{d \times d} WQ,WK∈Rd×d, W G , W V ∈ R d × 2 d W_G,W_V\in \Reals^{d \times 2d} WG,WV∈Rd×2d, W O ∈ R 2 d × d W_O\in \Reals^{2d \times d} WO∈R2d×d。 V V V的头部维度是 Q , K Q,K Q,K的两倍。加宽的维度通过 W O W_O WO投影回 d d d。为了保持参数数量与Transformer相同,RetNet中FFN的中间维度为 2 d 2d 2d。同时,论文在实验中将头维度设置为256,即queries和keys为256,values为512。在不同模型大小之间保持 γ \gamma γ 相同,其中 γ = 1 − e l i n s p a c e ( l o g 1 / 32 , l o g 1 / 512 , h ) ∈ R h \gamma=1-e^{linspace(log1/32,log1/512,h)}\in \Reals^h γ=1−elinspace(log1/32,log1/512,h)∈Rh。

上图显示了不同尺度模型的训练配置,从零开始训练各种大小的语言模型(即1.3B, 2.7B和6.7B)。 训练语料库是从ThePile,C4和TheStack的精选的数据集,开头附加标记来表示序列的开始。训练batch size为4M token,最大长度为2048,用100B个token训练模型,即25k步。使用AdamW优化器 β 1 = 0.9 β1 = 0.9 β1=0.9, β 2 = 0.98 β2 = 0.98 β2=0.98,权重衰减设置为0.05。 预热步骤为375步,学习率呈线性衰减。参数按照DeepNet进行初始化,以保证训练的稳定性。

上图为更详细的训练配置。
对比试验

上图显示了transformer和retnet的各项性能对比,对于7B参数的模型和8k的输入序列长度,可以看到相比于transformer,retnet实现了8.4倍的吞吐量,节省了3.4倍的显存占用,降低了15.6倍的推理延迟。右图可见随着模型参数的增大,retnet具有更小的预测困惑度。

上图为RetNet与过往骨干网络的对比,可以看到算法同时实现了以往算法无法同时实现的训练并行化、推理低代价、长序列线性存储复杂度。

上图实验对比了基于Transformer和RetNet的语言模型验证集的困惑度。给出了三种模型尺寸的缩放曲线,即1.3B、2.7B和6.7B,RetNet与transformer取得了相当的结果。除性能外,RetNet训练在实验中相当稳定。实验结果表明,在大型语言模型方面,RetNet是Transformer的有力竞争对手。从经验上看,当模型大小大于2B时,RetNet的性能开始超过Transformer。

上图进一步比较了不同上下文长度的语言建模结果。使用2048个文本块作为评估数据,并仅计算最后128个单词的困惑度。实验结果表明,RetNet在不同上下文长度下的性能优于Transformer。此外,RetNet可以利用更长的上下文来获得更好的结果。

上图为retnet在下游任务用6.7B模型评估了零样本和少样本学习。数据集包括HellaSwag(HS)、BoolQ、COPA、PIQA、Winograd、Winogrande和StoryCloze (SC)。准确率数字与图5所示的语言建模困惑度一致。RetNet在零样本和上下文学习上与Transformer取得了相当的性能。
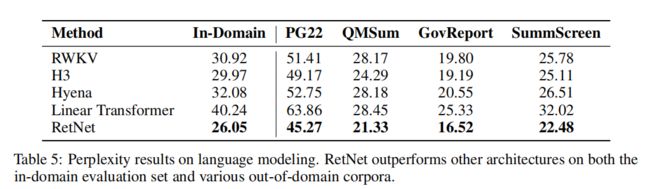
上图为将RetNet与各种高效的Transformer变体进行了比较,实验在域内验证集和其他域外语料库上计算困惑度,包括Project Gutenberg 2019-2022(PG22),QMSum, GovReport,SummScreen数据集。总的来说,RetNet在不同数据集上的表现优于之前的方法。RetNet不仅在领域内语料上取得了较好的评测结果,而且在多个域外数据集上也获得了较低的困惑度。
此外,比较方法的训练和推理效率,设d表示隐藏维度,n表示序列长度。
-
在训练方面,RWKV的token混合复杂度是 O ( d n ) O(dn) O(dn),而Hyena的复杂度是 O ( d n l o g n ) O(dn log n) O(dnlogn)。上述两种方法通过使用元素操作符来权衡建模容量来减少训练FLOPS。与 Retnet相比,分块循环表示复杂度是 O ( d n ( b + h ) ) O(dn(b + h)) O(dn(b+h)),通常设置块大小b = 512, 头尺寸h = 256。对于较大的模型大小(即较大的d)或序列长度,额外的b + h的影响可以忽略不计。因此,RetNet训练在不牺牲建模性能的情况下非常高效。
-
推理方面,在比较的高效架构中,Hyena具有与Transformer相同的复杂度 O ( n ) O(n) O(n),而其他架构为 O ( 1 ) O(1) O(1)。
训练成本

上图比较了Transformer和RetNet的训练速度和内存消耗,训练序列长度为8192。还将其与FlashAttention进行了比较,该方法通过重新计算和核融合提高了速度并减少了GPU内存IO。使用chunkwise递归表示留存率,块大小设置为512。
实验结果表明,RetNet在训练过程中比transformer具有更高的内存效率和吞吐量。即使与FlashAttention相比,RetNet在速度和内存成本上仍然具有竞争力。此外,在不依赖特定内核的情况下,很容易在其他平台上高效地训练RetNet。RetNet具有通过高级实现(如内核融合)进一步降低成本的潜力。
推理成本

上图在推理期间比较Transformer和RetNet的内存成本、吞吐量和延迟。transformer用解码过的KV标记缓存,RetNet使用循环表 示推理。观察到RetNet在推理成本方面优于Transformer。
内存成本:由于KV缓存,Transformer的内存成本呈线性增长。相比之下 ,RetNet的内存消耗即使对于长序列也保持一致,只需更少的GPU内存t。RetNet的额外内存消耗几乎可以忽略不计(即大约3%),而模型权重占97%。
吞吐量:随着译码长度的增加,Transformer的吞吐量下降。相比之下,RetNet通过利用保留的循环表示,在解码过程中具有更高的长度不变的吞吐量。
延迟:随着输入的增加,transformer的延迟增长得很快。相比之下,RetNet的解码延迟优于transformer,并在不同的批大小和输入长度上保持几乎相同。
消融实验

swish gate和GroupNorm:行2、3显示swish gate和GroupNorm两个组件提高RetNet的最终性能。实验表明swish gate模块是增强非线性和改善模型性能的关键。GroupNorm平衡了多头输出的方差,提高了训练稳定性和语言建模结果。
多尺度衰减:Gated Multi-Scale Retention使用不同的 γ \gamma γ作为保留头的衰减率。行4显示衰减机制和使用多个衰减率都可以提高语言建模的性能。
head尺寸:head维度暗示了隐藏状态的记忆容量。在消融研究中,将默认头部维度从256减少到64,即query和key为64,value为128,隐藏层维度不变。行5表明,head尺寸越大,性能越好。
reference
Yutao, S. , Li, D. , Shaohan, H. , Shuming, M. , Yuqing, Xia. , Jilong, X. , Jianyong, W. , & Furu, W. . (2023). Retentive Network: A Successor to Transformer for Large Language Models.