小周带你正确理解Prompt-engineering,RAG,fine-tuning工程化的地位和意义
有人会说:"小周,几天不见这么拉了,现在别说算法了,连code都不讲了,整上方法论了。"
我并没有拉!而且方法论很重要,尤其工程化的时候,你总得知道每种技术到底适合干啥,其实主要是现实中,我在项目里发现大家对这块其实并不是分的很清楚。
所以我来给大家捋一捋,因为这毕竟直接取决于你设计的解决方案是否能真正解决问题

如上图所示,OpenAI把对于优化LLM返回结果分为两个方向,一个方向是横坐标系的对LLM 模型本身的优化,另一个是对你提供的Context的优化
-
在对LLM本身的优化上没啥可弄的,最后就只能走到Fine-tuning这一条路
-
在对本身的Context进行优化的方式,我们一般起手式是先prompt-engineering
-
prompt-engineering不好使了,我们会借助RAG来实现额外的能力和知识
我们先来把几个概念再捋一下
prompt-engineering

上图就是一个不清晰的prompt的典型,没有清晰的system message定义,得到的回应也是特别的随机,并且没有清晰的format

优化上面的prompt,从几个维度入手:
-
首先肯定是要指令变得更清晰
-
其次用COT的方式提问让它拆解复杂的任务
-
顺便告诉LLM你要什么样输出的回答格式

再进阶就要上few_shot了,告诉LLM,你想要的答案是长啥样的,甚至风格
我上面说的看起来好像都很日常,但是你真的了解prompt-engineering吗?
Prompt-engineering的一个最重要的隐藏功能就是超级测试工具,当你的项目涉及到非常复杂的推理场景,尤其是多步推理能力的时候,COT就是你最好的测试工具
Tips: 在我们给project挑选模型底座的时候,除了去看一些所谓的测试结果以外,很大一部分工作时要做COT+fewshot的测试例,尤其是COT,比如写50到100个COT的问题,观察list里的LLMs,究竟谁的回答更靠谱,更有逻辑,尤其是复杂推理场景,相信我,这一步都过不去的LLM,你就没有必要再考虑后面的RAG和FT了(这篇文章看到这,其实读者就你大赚特赚了,省了你多少精力!)
继续说,prompt-engineer它调用毕竟还是基座模型的能力,你要想让模型输出一些训练数据中没有的知识,甚至都不在互联网上可查询的知识,或者这个模型的所有说话方式都不适合你的应用场景,那你怎么办?
一般这个时候大家都会说我们可以fine-tuning也可以RAG,这两个方法都能解决这些问题,如果你也是相同的想法,坦白说看这篇文章你又赚到了,这俩不但不是同一个东西,解决的问题也不一样

诚然,我们在很多时候都会认为像上图一样,RAG也好,FT也好都能让LLM产生新的记忆,我们可以把RAG认为是短期记忆,FT产生的是长期记忆,某种程度看起来没错。
这里需要纠正的是FT产生的,我们不能认为它是长期记忆,微调无法让LLM学习知识,而是学习了行为模式,或者叫学习了结构,这块如果要讲理论,比较复杂,拆开讲要讲3篇, 后面看看有时间可以开个新坑,大家目前简单理解这几句话即可
我们来逐一解决上文提到的问题,无非是两个:
-
新知识
-
表达方式
RAG
新知识你就用RAG来做就可以了(当然也可以拿agent来做,我这里不讲agent)
评估一个RAG系统的好坏,我们一般分为4大维度
-
第一个 真实性
-
第二个 精确性
-
第三个 回答的关联性
-
第四个 召回率
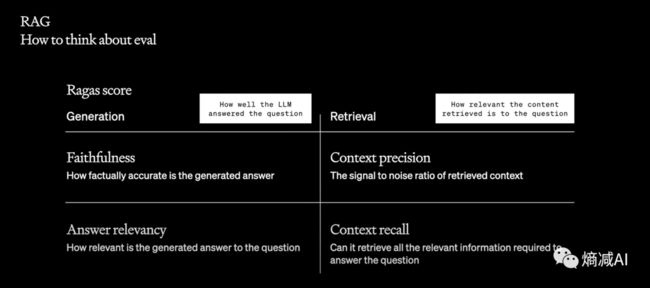
有读者说,你这几个指标看着都还行,像那么回事,那我们怎么来做量化呢?下面链接,拿走不谢

explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines (github.com)

通过regas这个项目调用openai就能自动为你的RAG系统这几个参数来打分,根据分数高低来调整你的RAG系统
另外可能有读者说以前做过RAG,不就是拿向量数据库来做匹配吗!但是这个其实已经很落伍了,比较先进的架构是同时拿多个RAG方式来提取多个RAG答案,一起汇总,然后经过re-ranking系统来排出top_k, 最后跟着prompt一起给到LLM
可选的RAG方式除了向量库做余弦匹配以外,也流行直接拿text-to-sql,或者直接拿标量搜索去取企业里的准确数据
你加的越多,就越准确,但是你整体LLM流程就越慢


,需要balance
另外在向量库的选择和document切分这块能玩的花活儿也很多,某种程度上决定了你RAG系统的上限(留个坑,以后讲)
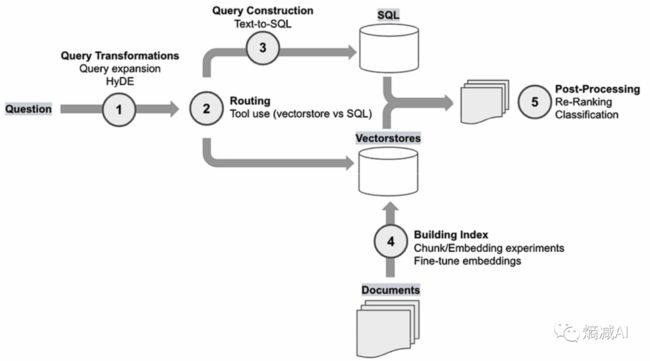

如上图所示,RAG答案丰富度,对模型的test 效果有一定的正相关关系
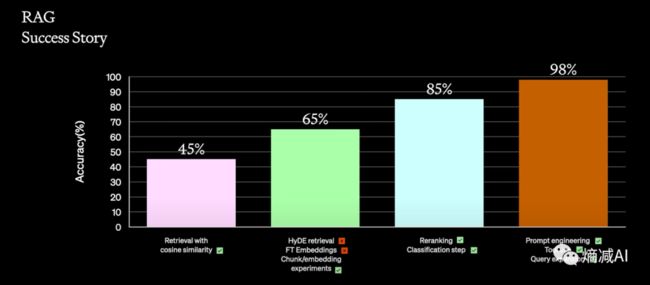
RAG上加的feature越多,也和你RAG系统的准确度成正相关
Fine-tuning
下图把Fine-tuning能干啥,不擅长干啥写的已经很清楚了,所以读者们今后别再假设通过FT能给你模型增加新知识了,这条路是走不通的(当然可能也有人是把追加预训练和FT给搞混了,这俩可不是一个东西)

相反
-
如果你要强化你预训练里面的知识的能力,比如专门针对代码的FT
-
如果你要做情感陪伴的时候,想让模型以某种不好描述的态度对你说话的时候
-
如果你想让你模型能读懂特别复杂的指令,你又不想写很复杂的prompt的时候
那么选Fine-tuning,没错的
下面这两幅图很好的举例了FT前后的output对比


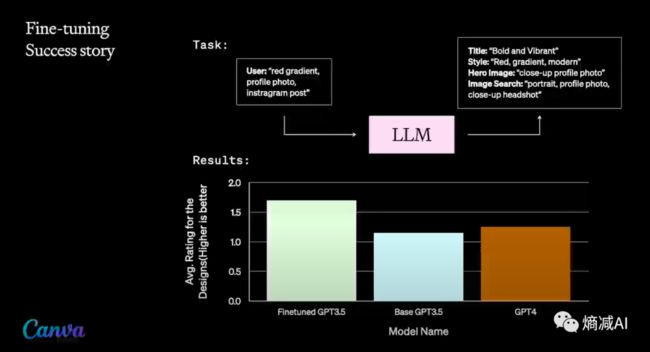
从某种意义上说,对特定任务的Fine-tuning会给小参数模型以超过大参数模型的能力,如下图所举的例子
Canva(做设计的公司)通过对GPT-3.5进行 FT,能得到超过GPT-4的能力
prompt-engineering,RAG,fine-tuning,这几个东西各自有各自的用途和场景,也能混用,但是不能平行着用,读完了我这篇文章,相信读者们应该很好的理解了他们的各司其职,最好的方法肯定还是混着用
比如Scale AI他们就给出过几种能力叠加以后的准确率相关性

本文完
