写的太通透了!大模型自省式 RAG 与 LangGraph 的实践!
本文讲解了自省式 RAG 的基础原理以及基于 LangGraph 的实践演示

自省式 RAG 与 LangGraph
重要链接
-
关于 Self-RAG 和 CRAG 的教程手册
-
演示视频
研究背景
由于大多数大型语言模型(LLMs)通常只针对大量公共数据进行周期性训练,它们往往缺少最新信息或不能接触到无法用于训练的私有数据。检索增强生成(RAG)模式恰好解决了这个问题,它通过将大型语言模型连接到外部数据源上(我们有相关的视频系列以及[博客文章](https://blog.langchain.dev/deconstructing-rag/)进行了介绍)。
RAG的基本流程涉及到解析用户查询、检索相关文档,并将这些文档供给大型语言模型,以此产生一个建立在相关上下文之上的答案。
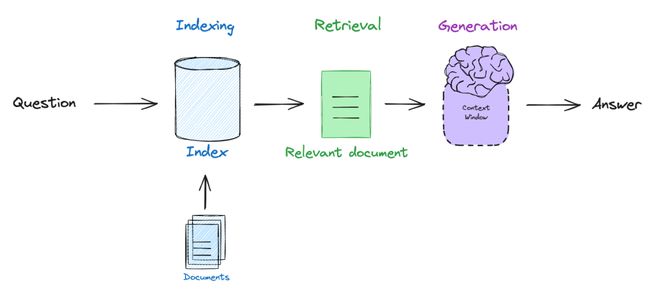
基础 RAG 流程示意图
自省式 RAG
实际操作中,实现 RAG 需要对上述步骤进行逻辑分析:比如,我们需要知道什么时候进行检索(基于问题和索引的构成)、何时改写问题以提升检索效率,或者何时抛弃无关的检索结果并重新检索。因此提出了自省式 RAG(详见论文)这一概念,自省式 RAG 利用大型语言模型自我校正检索质量不佳或生成内容不够优质的问题。
如上所展示的基础 RAG 流程,实质上是一种链式过程:大型语言模型根据检索到的文档来决定生成的内容。有些 RAG 运作模式采用的是路由机制,大型语言模型会根据提出的问题选择不同的检索器。但是自省式 RAG 通常需要某种反馈机制,比如重新生成问题或重新检索文档。
这时候,状态机制作为第三种认知架构(详见认知架构博客),因其能够支持循环操作而非常适用:状态机可定义一系列步骤(例如检索、评估文档、改写问题)并设置它们的转换逻辑;比如,如果我们检索到的文档无关,我们可以重新改写问题再进行检索。

利用认知架构实施 RAG 的示意图
利用 LangGraph 实现自省式 RAG
我们最近发布了 LangGraph,这是一个简单的大型语言模型状态机实现工具。这为设计各种不同的RAG 流程提供了极大的灵活性,并支持在 RAG 中进行所谓“流程工程”,即在具体的决策点(如:评估文档)和循环(比如:重新检索)中进行特定操作。
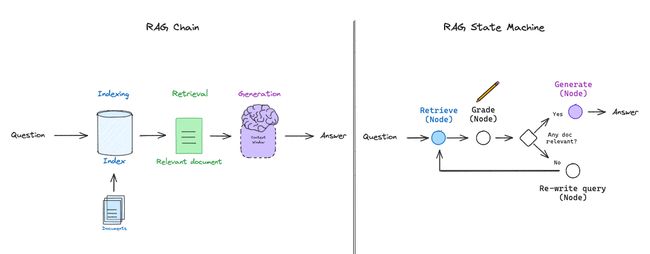
状态机让我们得以设计出更复杂的 RAG “流”
为了展现 LangGraph 的灵活性,我们利用它来实现了两篇引人入胜、前沿的自省式 RAG 论文,CRAG 和 Self-RAG 中提出的思想。
纠正式 RAG (CRAG)
纠正式 RAG(CRAG)在其论文中提出了以下鲜明的理念:
-
引入一种轻量级检索评估工具,用以对查询返回的文档进行整体质量评估,并为每项文档打分。
-
当检索的结果不明确或与用户的查询不够相关时,启用基于网络的文档检索来补充上下文。
-
执行知识细化:把检索的文档分成“知识条”,对每条进行评分,过滤出无关的内容。

CRAG 流程图
在描述流程时,我们对一些步骤进行了简化和调整,方便理解(实际应用时可以进行相应的定制和扩展):
-
我们省略了知识细化这一环节,尽管它代表了一个颇具价值的数据后处理方法,但在本文的流程示例中并不是必要的。
-
如果发现任意一个检索的文档不相关,我们将通过网络搜索来补充检索内容。在这里我们使用 Tavily Search API来进行网络搜索,这既快速又方便。
-
我们还将改写查询语句,以便于网络搜索能提供更优的结果。
-
对于二选一的决策节点,我们用 Pydantic 来确定输出模型,并作为每一次执行大型语言模型的调用过程中运行的 OpenAI 工具函数。这让我们能够根据二选一逻辑确定何种逻辑路径。

CRAG 流程的 LangGraph 实施示意图
我们在教程笔记本中设计了这个方案,并建立了三篇博客文章的索引。在这里,您可以看到当引用其中一篇博客文章中的信息时,CRAG 是如何工作的:我们的逻辑流清晰可见。

相比之下,当我们提出不在博客文章讨论范围内的问题时,流程便会有所不同。在这里您可以看到,系统从网络搜索中检索了补充的文档,用以生成最终的答复。

自 RAG
自 RAG 是一个与之相望的解决方案,论文中提出了许多独到的 RAG 理念。框架中训练大型语言模型生成自我反思的提示符号,用以控制 RAG 流程的各个阶段。下面是提示符号的一览:
-
Retrieve符号决定是否需要根据x(问题)或x(问题)、y(回答)检索D数据块。可能的输出结果有yes, no, continue。 -
ISREL符号针对x问题,判断数据块D是否相关。输入为 (x(问题),d(数据块))。结果为relevant(相关), irrelevant(不相关)。
-
ISSUP符号判断 D 中每个数据块生成的答复是否与之相关。输入包括x,d,y。这个标记也是验证d是否支持y(生成)中的所有需要证实的陈述。可输出fully supported(完全支持), partially supported(部分支持), no support(不支持)。 -
ISUSE符号评估 D 中每个数据块生成的答复是否对x有用。输入x,y对于d在D里。输出是{5, 4, 3, 2, 1}。
论文中的下表为上述信息提供了进一步细节:

Self-RAG 中采用的四种提示符号
以下简图帮助我们理解信息流的运转机制:

Self-RAG 使用的流程简图
我们可以在 LangGraph 中对其进行实现,为了说明需要进行了一些简化和调整(在实际需求中可以进行相应的定制和扩展):
-
如上文所述,我们对每个检索到的文档进行评分。如果发现任何文档相关,我们就进行下一步的生成工作。如果全部文档都不相关,那我们就会改写查询来提出一个更加精确的问题,然后重新进行检索。这一环节可以很容易地结合上述 CRAG 所述的网络搜索补充节点。
-
论文中会针对每一个数据块进行生成,并进行双重评估。但在我们的实现中,只从所有相关文档生成一次内容。然后,我们根据文档检查这次生成的内容(例如,以保护免受错误印象的影响)并根据答案进行评估。这减少了调用大型语言模型的次数,提高了响应速度,并允许在生成答案时综合更多的上下文信息。

LangGraph 实现 Self-RAG 流程示意图
这里展示的示例轨迹强调了主动 RAG 的自我纠正能力。查询的问题是 解释不同类型代理记忆是如何工作的?。在此示例中,所有四个文档都被认为相关,对照文档检查生成答案的环节顺利通过,但生成的答案未被认定完全有用。
之后,如这里所示,循环重新开始,问题稍微改写为:不同类型代理记忆的运作方式如何?。此时,四份文档中有一份因为无关而被筛选出去。之后的生成答案成功通过了所有检查:
不同类型的代理记忆包含感官记忆、短期记忆和长期记忆。感官记忆能够保留短暂的感觉信息。短期记忆则被用于实时学习和构建提示。而长期记忆则让代理人可以在很长的时间里保存和回忆信息,并常常依赖外部的向量存储来实现。
整体流程轨迹清晰可见,可以容易地进行审核:

结语
自省机制可以显著提升 RAG 的功能,允许改正检索和生成过程中的质量问题。几篇最新的 RAG 论文都着重讨论了这一主题,但要将这些理念实际应用起来有着不小的难度。本文展示了如何利用 LangGraph 进行“流程工程化”地实施自反式 RAG。我们还提供了实施两篇引人注目的论文 —— Self-RAG 和 CRAG 中的理念的详细指导。
今天的内容就到这里,如果老铁觉得还行,可以来一波三连,感谢!
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远.
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程