【CV论文精读】Adaptive Fusion of Multi-Scale YOLO for Pedestrian Detection基于多尺度自适应融合YOLO的行人检测
Adaptive Fusion of Multi-Scale YOLO for Pedestrian Detection
0.论文摘要和作者信息
摘要
虽然行人检测技术在不断改进,但由于不同规模的行人和遮挡行人模式的不确定性和多样性,行人检测仍然具有挑战性。本研究遵循单次目标检测的通用框架,提出了一种分而治之的方法来解决上述问题。该模型引入了一个分割函数,可以将一幅图像中没有重叠的行人分割成两个子图像。通过使用网络架构,对所有图像和子图像的输出执行多分辨率自适应融合,以生成最终检测结果。本研究对几个具有挑战性的行人检测数据集进行了广泛的评估,最终证明了所提出的模型的有效性。特别是,所提出的模型在来自视觉对象类2012(VOC 2012)、法国计算机科学与自动化研究所和苏黎世瑞士联邦理工学院的数据集上实现了最先进的性能,并在本研究精心设计的三倍宽度VOC 2012实验中获得了最具竞争力的结果。
行人检测,多尺度YOLO,自适应融合
作者信息
Wei-Yen Hsu1,2,3*, Member, IEEE and Wen-Yen Lin1
1Department of Information Management, National Chung Cheng University
2Center for Innovative Research on Aging Society, National Chung Cheng University 3Advanced Institute of Manufacturing with High-tech Innovations, National Chung Cheng University
*Corresponding author: Wei-Yen Hsu (email: [email protected]; [email protected]) This work was supported by the Ministry of Science and Technology, Taiwan, under Grant MOST108-2410-H-194-088-MY3 and the Center for Innovative Research on Aging Society (CIRAS) from The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by Ministry of Education (MOE) in Taiwan, i.e. CYCH-CCU Joint Research Program under Grant CYCH-CCU-2021-07.
1.研究背景
在实际应用中,经常会出现不同比例、遮挡和特殊纵横比的行人图像,这对行人检测是一个巨大的挑战。大多数最先进的行人检测方法都致力于解决这些问题[1–2]。虽然这些方法可以很好地检测不同尺度和不同遮挡问题的行人,但当图像具有特殊的纵横比时,它们通常表现不佳。调整输入图像的大小是所有检测算法在检测过程中必须执行的第一步。然而,对于具有特殊长宽比的图像,在调整大小后,这类图像中的大多数行人都被大大压缩,甚至消失。检测器可能被其检测窗口中的信息误导,这导致应该检测的行人丢失。如图1所示,(a)是样本图像,(b)显示宽度是原始长度三倍的图像,(c-d)显示调整到固定大小的图像。该图清楚地表明,图像中的行人可能会被过度压缩,甚至在图像调整大小后消失。此外,与背景颜色相似的行人很可能在检测过程中被遗漏。因此,本研究探索了解决此类行人检测问题的方法。
 图一。(a)样本图像;(b)宽度为长度三倍的图像;(c,d)在输入图像之前由检测器调整大小的图像。
图一。(a)样本图像;(b)宽度为长度三倍的图像;(c,d)在输入图像之前由检测器调整大小的图像。
虽然深度学习已经广泛应用于行人检测[3,4]、图像识别[5]、地点识别[6]、降维[7]、物体检测[8-10, 49-52]和姿态恢复[11,12],但仍然缺乏针对特殊纵横比图像的检测算法。更具体地说,提出了一种多标签学习方法[3]来联合学习部分检测器,以捕捉部分遮挡模式来处理部分遮挡的条件。引入了多个内置子网络[4],这些子网络从不相交的范围用刻度检测行人。HDWE模型[5]通过集成稀疏约束和改进的RELU算子来设计,以解决来自视觉特征的点击特征预测。通过与VGG-16网络或ResNet-18网络集成,引入了SPE-VLAD层和WT-loss层[6],以形成一种新颖的端到端深度神经网络,该网络可以通过标准的反向传播方法轻松训练。
提出了一种用于降维的无监督深度学习框架LDFA[7]。提出了一种基于集成深度学习的对象检测框架[8]。CoCNN[9]被提出在一个统一的深度模型中融合从低到高层的颜色和视差特征。门控CNN[10]被引入以集成多个卷积层用于对象检测。提出了一种新的姿态恢复方法[11],该方法使用具有多层深度神经网络的非线性映射。提出了一种从轮廓中恢复三维人体姿态的方法[12]。
为了解决特殊长宽比下行人的不确定性和多样性以及遮挡行人模式的问题,本研究使用单阶段目标检测器You only look once(YOLO)v4[13]作为基础,并最初将图像长度和宽度信息导入网络,以缓解调整大小后的图像失真问题。本研究选择[13]作为基础,因为在网络结构中,只有最后一个滤波器的输出大小必须是固定的。因此,图像的长度和宽度信息可以很容易地导入并合并到网络中,以便更有效地使用信息,从而允许原始的深度学习行人检测方法在所有情况下都表现出改进的性能。此外,由于检测图像中的小规模行人和遮挡问题很困难,大多数深度学习都涉及多尺度建模来提高检测结果,包括Faster R-CNN[14]、Yolov3[15]和SSD[16]。虽然这些算法在添加多尺度建模后实现了性能增长,但当遇到具有特殊纵横比的图像时,这个问题无法解决,从而导致后续的检测问题。因此,利用本研究提出的分割函数和多分辨率自适应融合,通过分治法检测出一幅图像,可以解决特殊长宽比图像的行人检测问题,防止图像中行人的变形和失真导致检测性能不佳。
本研究中提出的分割函数的中心思想包括将图像中行人的不相交部分分成两个子图像,以分别从图像中提取特征。随后,使用多分辨率自适应融合来补充和融合样本图像和子图像给出的信息,以实现本研究提出的分而治之行人检测方法。分割函数和多分辨率自适应融合方法存在以下两个缺点:(1)计算量随分割函数生成的子图像数线性增加;以及(2)需要额外的融合时间。然而,将分割的总时间成本控制在不超过原始方法的两倍[13]可以减少行人检测过程中遇到的困难,而不会过度增加时间成本。
本研究的贡献如下。首先,通过将图像长度和宽度信息整合到网络中,初步缓解了调整大小后的图像失真问题。其次,在神经网络架构中应用分割函数来有效地分割样本图像,以从多个子图像中提取互补信息。第三,将多分辨率自适应融合机制整合到统一架构中。这可以整合来自多个子图像的互补信息,以创建比使用任何单个图像进行行人检测更令人满意的融合方法。最后,实验表明,本研究中提出的方法优于最初的YOLO和几种最先进的方法,因为它显示了VOC 2012 comp4[17]、法国计算机科学与自动化研究所(INRIA)[18]和瑞士苏黎士联邦理工学院(ETH)[19]数据库和VOC 2012测试集(本研究中精心设计的三倍宽度图像测试集)的最佳性能。研究的其余部分组织如下。在第2节中,讨论了关于最新方法的相关工作和文献。在第3节中,介绍了所提出的模型的技术细节。在第4节和第5节中,描述了我们进行的大量实验,并将所提出的方法应用于现有的行人数据集,以证明其可行性和性能。最后,第6节对本研究进行了总结,并为今后的研究提供了方向。
2.相关工作
在过去的几年里,来自不同国家的研究人员一直在寻求改善行人检测[20]。近年来,由于神经网络架构和硬件设备的进步,人们对神经网络产生了兴趣,深度学习也得到了普及。此外,辛顿等人的研究小组。(2012)通过使用深度学习赢得了ImageNet竞赛[21],这促进了深度学习的概念,并影响了许多研究人员专注于这一领域进行许多令人印象深刻的研究,包括Mask R-CNN[22]、DSSD[23]、InsideOutside Net[24]、卷积学习[25]、outline features神经网络[26]、R-CNN[27]、Fast R-CNN[28]、YOLOv1[29]和RetinaNet[30]。[27]中的一个主要缺点是其检测操作极其耗时,因为每个区域建议的分类必须单独执行。此外,由于大多数区域建议重叠,[27]的效率甚至更低。因此,随后的研究人员引入了[28]和[14]。具有卷积神经网络的更快区域(R-CNN)[14]使用区域建议网络(RPNs)直接生成检测框架,这大大提高了检测框架的生成速度,并使其成为R-CNN型算法的基石。此外,RPNs取代了[27,28]中大多数耗时且非神经网络的选择性搜索,从而实现了端到端的神经网络检测。
基于[28],一些学者通过不同的思维模式提出了一种新的结构:内外网络框架[24]。该研究提出了一种包括内部和外部网络的神经网络架构,它使用跳过连接和递归神经网络来检测给定上下文中的对象,其中内外网络框架代表感兴趣的内部和外部区域。外部网络主要用于提取上下文信息,内部网络用于实现多尺度融合。此操作使Inside-Outside net framework能够对图像中的小对象显示出色的检测能力。YOLO[29]的作者提出了一个新的想法。与以前使用R-CNN[27]的算法不同,YOLO不使用区域建议提取,而是直接从图像中生成预测结果,这被称为一阶段方法。该研究[29]首次在深度学习中应用了一阶段模型,该模型将对象检测转化为统一的端到端回归问题。YOLO[29]和R-CNN[27]算法之间的区别通常是具有更高检测速度的单阶段算法。然而,这通常会导致小对象或重叠对象的低检测性能。因此,YOLO、Redmon and Farhadi的原始作者针对这些问题开发了各种改进方法[13,15],本研究将其改编[13]作为一种新的改进方法。另一种单阶段算法被称为单镜头检测(SSD)[16],大多数后续的单阶段算法都基于这种方法和[29]。例如,[23]是[16]的变体。这些方法通常在可以执行下一个检测动作之前,直接将具有各种纵横比的图像调整到固定大小。因此,具有不同纵横比的图像通常不会显示出令人满意的结果。本研究引入了一个简单有效的框架,利用长度和宽度信息传输到网络,从而允许网络对每个图像做出最合适的调整。此外,该框架结合样本图像和分割子图像提供的特征信息,通过多分辨率自适应融合获得最终结果。该方法使网络能够很好地获得不同长宽比和尺度的行人检测图像。
3.提出的网络结构
3.1 概述
本研究中提出的网络架构是基于YOLOv4[13]的新框架。它首先考虑图像中的宽度和高度信息,相应地调整信息的大小,并将其发送到检测网络。随后,通过分割非重叠区域并将其发送到网络以获得要获取的整个图像和子图像的特征信息,从而获得子图像。最后,采用多分辨率自适应融合实现最终融合和输出。在本研究中,不同分辨率的特征信息被整合以获得测试结果。
3.2 提出模型的网络结构
图2简要描述了所提出的模型的网络架构。该模型首先使用resize with ratio函数自动调整网络的超参数,使图像在调整大小后保持原来的纵横比,以适应不同纵横比的图像。随后,图像被发送到卷积神经网络(CNN)模型,以获得整个图像的特征图。特征图被映射回样本图像,以使用该信息来识别样本图像上行人不相交的分割点。此外,利用分割函数将样本图像分割成不同大小的子图像。类似于用于获得整个图像的特征图的步骤,子图像被发送到CNN模型以获得子图像的特征图。最后,利用多分辨率自适应融合技术对每幅图像中的行人检测信息进行整合,并输出最终结果。通过整合具有多分辨率的行人检测信息,本研究中提出的模型可以在给定图像中精确地框住不同比例的行人。
 图二。所提出方法的流水线。从输入到网络中的图像,首先使用卷积神经网络(CNN)模型提取特征图,以获得整个图像的特征信息。随后,在输出结果之前添加分割函数;根据整个图像的特征图上的信息,识别样本图像上与行人不重叠的点,以分割图像。分割后的图像被发送到CNN模型以提取相应的特征图。最后,通过多分辨率自适应融合对样本图像和子图像生成的几个特征图进行融合,以加强图像行人检测的特征描述,最后生成输出(图中左下角)。
图二。所提出方法的流水线。从输入到网络中的图像,首先使用卷积神经网络(CNN)模型提取特征图,以获得整个图像的特征信息。随后,在输出结果之前添加分割函数;根据整个图像的特征图上的信息,识别样本图像上与行人不重叠的点,以分割图像。分割后的图像被发送到CNN模型以提取相应的特征图。最后,通过多分辨率自适应融合对样本图像和子图像生成的几个特征图进行融合,以加强图像行人检测的特征描述,最后生成输出(图中左下角)。
3.3 比例调整
因为每个图像具有不同的纵横比,所以将它们压缩到相同的纵横比本质上不是最佳方法,因为这可能导致图像中的行人变形或失真,从而导致后续的检测错误或失败。如图1所示,一些后续错误可能是由纵横比非常不同的图像引起的。因此,为了缓解调整大小带来的问题,本研究简单地在调整大小期间添加来自样本图像的纵横比信息,以允许网络相应地调整并在调整大小后保留原始比率。最初,[13]支持手动调整输入层的超参数所需的灵活性,本研究将手动调整的超参数过程转化为可以通过一些简单的计算自适应调整的超参数。
3.4 分隔函数
本文提出的分割函数主要包括两个步骤。第一步过滤整个图像的特征图中的行人帧,第二步将样本图像分割成子图像。将分割功能添加到模型中的主要考虑是,如果网络仅依赖于整个图像的特征图给出的信息进行检测,它可能会由于非最大抑制(NMS)[31]操作而抑制一些重叠的行人。其他研究人员也提到过这个问题[32]。此外,行人可能会被过度框住。例如,如果比率超过图像的某个比率,该方法的第二步可能无法识别与行人不相交的部分,或者帧本身可能产生错误的结果。因此,本研究首先在第一步中添加了一些过滤条件来过滤掉大型行人帧。此外,为了避免过滤掉可能包含行人的帧,本研究简单地增加了分类置信度的筛选条件,以减少假阳性的发生。本研究确定当前选择的行人框架是一个离群值,离群值确定(OD),在z分数的基础上,

其中 Z h Z_h Zh和 Z w Z_w Zw是输入图像中所有帧的高度和宽度的z分数,C是帧是否包含行人的概率。在该方程中,b的可调超参数被用作帧是否包含行人的概率确定值,并且在转换每个行人帧的z分数之后的值通常落在-5到+5之间。因此,本研究将 z ≥ a z≥a z≥a的z分数基准值设置为异常值,其中a也是可调超参数。较大的A表示算法对异常值的容忍度较高。虽然 Z ≤ A Z≤A Z≤A可以视为异常值,但研究合理地声称,图像中出现小规模行人的概率更大。这一事实已在[20]中描述,因此本研究保留了 Z ≤ a Z≤a Z≤a的行人框架。未被过滤掉的行人帧被传递到第二阶段,用于分割成子图像。
分割可以简单地看作是分割样本图像的过程。本研究断言,当整个图像表现出较差的检测性能时,可以应用分治法,该方法涉及检测样本图像的一部分并将它们组合起来。当分割前的样本图像被放入CNN模型时,整个图像缩小得更多。尽管整个图像的特征图包含完整的行人信息,但是小的区域数据为整个图像产生的信息量不太明显,这只能代表低分辨率的特征图。然而,对于CNN模型中的分割图像,子图像的收缩发生得较少。虽然子图像只包含整个图像的一小部分,但信息量比整个图像丰富,因此它是一个高分辨率的特征图。该模型从第一阶段的检测结果中识别出最合适的图像分割点。理想情况下,图像中心不包含行人的点被分割成两幅长度和宽度相同的图像。
在本研究中,识别最佳分割点的方法类似于支持向量机最大边距的概念,它必须遵守两个原则:(1)最接近中心和(2)最远离左或右对象帧或边界。具体描述如图3所示。首先,该算法根据特征图识别输入图像水平轴上排除候选帧(蓝色帧)的所有点,并将这些点用作候选分割点。随后,在这些候选分割点中,只保留最靠近图像中心(红线)的点(黑点),这对应于该算法的第一原理。然后,这个黑点延伸到图像的短边,直到它到达最近的对象候选帧或图像边界,作为候选连续点(紫色点)。最后,将这些候选连续点(紫色点)的中点在垂直方向上连接起来,作为该算法的最佳分割线(绿线),这对应于该算法的第二个原理。选择具有最大边距的中点作为分割点的目的是为了避免在先前的检测结果中对象被分割的情况。如果整个图像中没有一点包含行人,则跳过分割阶段,直接输出滤波后的行人帧。
 图三。寻找最佳分割点。通常选择图像中最靠近中心的不包含行人的点作为分割点。
图三。寻找最佳分割点。通常选择图像中最靠近中心的不包含行人的点作为分割点。
3.5 多分辨率自适应融合
这项研究的最后阶段是多分辨率自适应融合。这融合了网络中遇到的所有特征图,包括整个图像的低分辨率特征图和子图像的高分辨率特征图。本研究采用了类似于[31]中的方法来融合来自不同图像的这些特征图,以实现最终的融合步骤。必须调整NMS的阈值。除了调整阈值之外,本研究还考虑了各种NMS方法来融合所提出的模型。除了传统的NMS[31],这项研究还使用了soft-NMS[32],其详细的实验内容在第5节的消融分析中有所描述。最后,由于整个网络过程中出现的所有特征图都被融合,该模型结合了上下文行人检测信息,在图像中各种尺度的行人检测率都很高。
4.实验
本章首先选择了实验中常用的三个数据集来评估行人检测性能:来自PASCAL VOC 2012 comp4[17]、INRIA[18]和ETH[19]的数据集。此外,本研究将PASCAL VOC 2012测试集中具有地面真相的5138幅图像水平扩展到图像长度的三倍,使它们成为具有特殊纵横比的图像。这些特殊的图像可以用来验证本研究中提出的模型可以在不同纵横比的图像中获得优异的性能。
4.1 实验准备
本研究中的实验均基于[13]开发的新网络架构,如图2所示,其中上下文中的公共对象(COCO)trainval[33]用于根据[13]的标准配置进行训练。我们使用随机梯度下降来训练我们的模型。训练的batch size为16,accumulate为4,momentum为0.92,weight decay为0.00045。该实验基于64位操作系统Windows 10 Professional。深度学习框架是Pytorch,GPU是GeForce RTX 2080ti。实验使用地面上的官方指标,即平均精度(AP)和对数平均错误率,其定义如下:

其中,真阳性(TP)是正确识别为阳性样本的阳性样本的数量,假阳性(FP)是错误识别为阳性样本的阴性样本的数量,假阴性(FN)是错误识别为阴性样本的阳性样本的数量。本实验中使用的pascal voc2012[17]的数据集遵循上述AP计算方法,而INRIA[18]和ETH[19]的数据集遵循标准评估指标。在 [ 1 0 − 2 , 1 0 0 ] [10^{−2}, 10^0] [10−2,100]中对每个图像的假阳性对对数MR进行平均(表示为MR)。

4.2 实施细节
所提出的模型框架中的某些超参数必须手动设置,并且这些超参数是在仔细的实验下创建的,以确保该方法在实际环境中能够获得满意的结果。分割功能的第一阶段是离群值过滤。经过实验调整后,本研究将异常值容限参数a设置为4,分类置信度阈值b设置为0.5。使用更中性的角度来过滤≥4的行人框架。最后,在多分辨率期间自适应融合,因为该算法主要基于NMS[31]算法的一个变体,所以必须调整NMS阈值才能达到融合效果,该参数设置为0.5。
4.3 数据集
本研究简要描述了表一中使用的开放数据集,详细描述如下。

4.3.1 PASCAL VOC 2012
Pascal voc 2012[17]包括16,135幅图像,其中5138幅图像具有地面真相。数据集分为20种类型,描述如下:人、鸟、猫、牛、狗、马、羊、飞机、自行车、船、公共汽车、汽车、摩托车、火车、瓶子、椅子、餐桌、盆栽、沙发、电视/显示器。本研究涉及行人检测,因此实验中提到的AP评价指标仅用于评价行人的准确性。5138幅地面真实图像中共包含7330名行人;因此,每个图像平均有1.43个行人。对于剩余的没有标注正确答案的图像,要使用这些图像来评估算法的质量,必须将结果上传到PASCAL VOC评估服务器以获得AP。必须上传到评估服务器以获得AP的部分数据集被称为voc 2012 comp4,具有地面真实的5138幅图像被称为voc 2012。
4.3.2 INRIA
INRIA人数据集[18]分为训练集和测试集。训练集包括614个阳性样本和1218个阴性样本,测试集包括288个阴性样本图像。本研究仅评估了测试集中的288幅图像,并遵循标准评估指标。
4.3.3 ETH
ETH行人数据集[19]分为训练集和测试集。训练集包括853幅图像,而测试集包括来自三个视频剪辑的1804幅图像,其中包含14,167名行人。
4.4 与SOTA的比较
4.4.1 VOC2012 COMP4
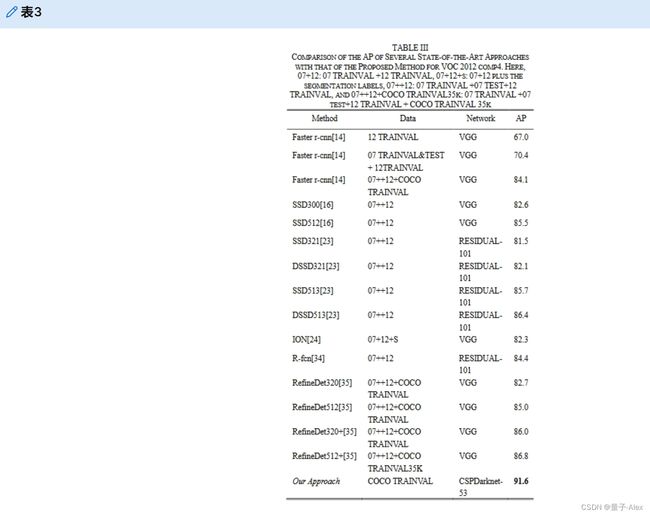
本研究将提出的模型与YOLO的原始版本(YOLOv3[15]和YOLOv4[13])进行了比较。在VOC 2012 comp4[17]获得优于原始方法的结果后,本研究中提出的模型与当前最先进的方法进行了比较,包括更快的r-cnn[14]、SSD[16]、反卷积SSD[23]、ION[24]、R-fcn[34]和RefineDet[35]。表II和表III列出了详细结果,本研究提出的模型在voc 2012 comp4中表现出色。

4.4.2 VOC2012
本研究在Pascal voc 2012[17]至voc 2012中分离出5138幅具有地面实况的图像。为了证明本研究提出的模型在检测具有特殊纵横比的图像中的行人方面是有效的,本研究首先将VOC 2012中的图像水平串联成三倍长度的图像,并将地面真实图像扩展3倍。因此,原来的7330幅地面实况图像在水平拼接后变成了7330 × 3=21,990名行人。图4显示了水平链接的三倍长度VOC2012图像。图像底部的行人较小,此类图像的行人检测难度较高。这种图像对于一些深度学习网络来说是困难的,因为它们包括小规模的行人和大的纵横比。随后,本研究将提出的模型与最初的YOLO方法进行了比较。详细结果见表四和图5。


根据实验结果,这项研究提出的AP优于最初的YOLO方法(图5)。此外,表四表明,提出的模型在各种阈值下提供了最佳性能。为了进一步证明这一拟议模型的性能,本研究将其与几种最先进的方法进行了比较,包括Faster R-CNN[14]、SSD[16]、Mask RCNN[22]、RetinaNet[30]、RefineDet[35]和RFBNet[36],方法是将它们应用于VOC 2012图像。结果显示,我们的方法优于所有最先进的方法,如表五所示。

4.4.3 INRIA
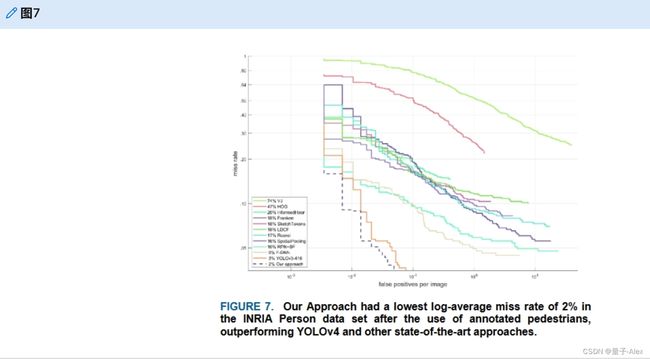
这项研究使用INRIA个人数据集[18]来评估提出的模型,方法是将其与YOLOv4[13]和几种最先进的方法进行比较,即定向梯度直方图[18]、VJ[37]、InformedHaar[38]、局部去相关通道特征[39]、Franken[40]、Roerei[41]、SketchTokens[42]、空间池化[43]、RPN+增强森林[44]和森林深度神经网络[45]。如图6所示,这项研究中提出的模型仅遗漏了6%的INRIA个人数据集[18],并且优于所有其他方法。

虽然该数据集在行人检测领域有着悠久的历史,但一些学者认为原始INRIA人数据集提供的一些行人注释是缺失的。因此,[46]为数据集提出了一种新的注释,对所有高度大于25像素的行人进行了注释,并将注释的行人总数从589个增加到878个。因此,本研究使用新的注释来评估提出的模型。图7中对这种新注释的实验结果显示,本研究中提出的方法获得了最佳结果,并将失误率降低到2%。
4.4.4 ETH
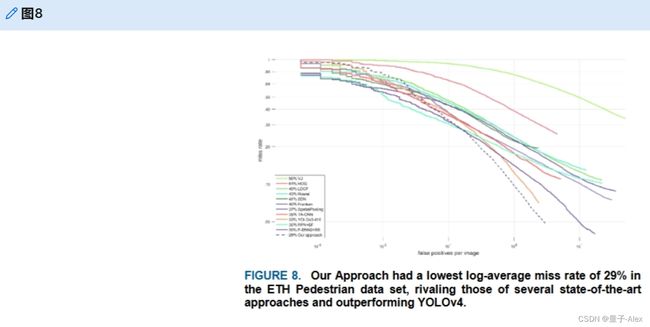
本研究通过使用ETH个人数据集[19]评估了提出的模型,并与YOLOv4[13]和几种最先进的方法进行了比较,即[18]、[37]、[39]、[40]、[41]、[43]、[44]、SDN[47]和task-assistant-CNN-CNN[48]。图8表明,这项研究中提出的模型在ETH个人数据集[19]中仅遗漏了29%,优于所有其他方法。
4.5 LIMITATIONS
如果作为输入图像水平方向上的候选帧的特征图都是重叠的,则将不执行分割功能。如表七所示,所提议的方法将以更简单的方式工作。

5.消融分析
本部分主要研究了本研究中提出的模型的不同组成部分和参数配置的有效性和合理性。本章中的所有实验都是在VOC 2012或VOC 2012 comp4中进行的,它们手动将图像连接成三倍长度。与上一节不同,本节详细比较了各种模块组件对所提出模型的性能。
5.1 分割函数
对于所提出的模型,该模块位于分割功能的第一步(过滤异常值)。此步骤减少了非行人被识别为行人的情况。如果跳过这一步,测试结果会很差。为了证明该模块可以提高检测结果,本研究在表VI中列出了在有和没有过滤异常值的情况下获得的检测结果。研究结果表明,使用过滤的离群值模块可以有效地提高检测精度。

在本研究中,使用一个称为分割函数的模块将样本图像分成两部分,通过分而治之的概念,解决了小尺度行人和图像特殊长宽比导致的行人检测性能低的问题。因此,为了证明该模块可以改善检测结果,本研究比较了通过仅使用整个图像、分割图像的特征以及整个图像和分割图像的融合特征而获得的检测结果,如表VII所示。

5.2 多分辨率自适应融合
最后阶段通过多分辨率自适应融合融合整个网络中的所有特征图,整合所有分辨率的行人检测信息,实现了一种改进的方法,而不是简单地使用任何单一图像进行行人检测。因此,为了达到融合效果,本研究使用类似于NMS[31]的特征图来融合网络。为了选择合适的NMS算法,本研究考虑了两种常用的NMS算法:NMS[31]和软NMS[32]。在VOC2012中从这两种算法获得的结果列于表VIII。在VOC2012中,通过添加建议的模型和软NMS L生成的AP最高(91.8),使用软NMS G生成的AP产生了与原始NMS方法相似的结果(91.6)。然而,输出行人帧表明,当使用较少的输出帧时,所提出的具有NMS的模型获得了与其他两种NMS算法几乎相同的AP。一般来说,虽然使用软NMS L和软NMS G可以改善AP,但它们降低了抑制效果,并且需要更多的计算时间。最重要的是,这可能导致在同一位置输出许多行人帧。因此,在综合了表VIII中的视觉数据后,NMS[31]仍然被选为组合各种分辨率特征的算法。

5.3 推理时间
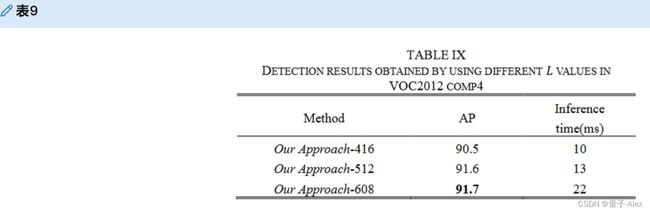
因为本研究中提出的模型是基于[13]的,所以保留了[13]中可以调整图像输入的长边最大超参数。本研究中的非特异性项目与[13]中的项目相似,其中默认的长边最大值为512,本节列出了表IX中提出的方法的完整推断时间。
6.总结
本研究提出了一种新的行人检测模型,该模型遵循分而治之的概念。除了将图像比例信息结合到深度学习中,还有效整合了网络中各种分辨率的行人检测特征,从特殊长宽比和小尺度行人出发解决行人检测问题。实验结果表明,该模型在流行的行人数据集中提供了良好的检测结果,并在本研究中手动和水平扩展了三倍长度的图像。与现有的方法和YOLO方法相比,对于具有特殊长宽比和小尺度的行人,所提出的方法在平均精度和对数平均失误率方面取得了良好的性能,这对于行人检测的主题仍然具有挑战性。尽管有这些优点,我们的方法仍然有一些缺点。一些超参数需要人工选择,分割函数的操作导致推理时间略有增加。在未来的工作中,这两个问题将通过进一步提出一种可以自动选择超参数的方法和一种比分割功能更好甚至没有分割功能来加速操作的机制来考虑。最后,本研究提出的机制可以扩展到应用于其他CNN架构或检测各种对象,以进一步改善和增强深度学习检测算法的性能。