http://hi.baidu.com/shichunqi
原 文:http://wrg.upf.edu/WRG/dctos/Middleton-Baeza.pdf
目录
第1章 简介
随着互联网信息量的激增, 为用户提供网上相关信息的检索成为迫切需求。而当你准备在网站上提供这种检索服务的时 候, 你可以选择, 要么利用商业搜索引擎,要么选择开源搜索引擎。对于很多站点, 采用商业搜索引擎, 可能没预期的那么便捷, 你得花钱, 而且呀, 你可能没大站点那样受人家重视。 另一方面,开源搜索引擎也能提供商业搜索引擎的同类功能(部分能够处理大数据量), 同时拥有开源理念带来的好处: 不花钱,可以更主动地来维护软件,也通过二次开发来满足个人的需求。
现今,可以选择的开源产品很多, 而要决定是采用哪个开源产品, 就必须认真考虑每个开源产品的不同的特性。对这些搜索引擎划分的依据可以是开发的编程语 言, 索引文件的存储(倒排文件, 数据库, 还是其他 文件格式), 查询的能力(布尔运算, 模糊查询, 词根替换等等), 排序策略, 支持索引的文件类型, 在线索引能力和增量索引的能力。 其他值得考虑的重要因素是项目的最后更新日期, 当前版本和项目的活跃度。 这些因素之所以重要是因为, 如果一个开源搜索引擎在近期没有更新的话, 那么要满足现在的网站的话, 可能存在很多的缺陷和问题。 利用这些特性就可以给出一个大体上的划分, 同时能够减少待选的开源产品的数目。 最后, 考虑不同负 载的时候搜索引擎的性能, 当信息量增加时, 性能的如何降低的,这些也非常重要。 此时,就要分析数据量和索引时间的对比情况, 索引阶段所用的资源, 和检索阶段的性能。
就目前我们了解的情况, 本文的工作是首创,比较了17个主流搜索引擎, 并 且在不同的文档集合和多种查询类型的情况下,比较了索引和查询的性能。本文的目的是告诉人们遇到某种搜索需求的时候,该如何选择是最合适的开源搜索引擎。
第二章, 介绍信息 检索的基础概念, 第三章, 描述一下本文的搜索引擎, 第四章, 测试实验的实现思路, 第五章前两节, 给出实验的结果。 第五章最后一节, 对结果进行分析。 最后, 第 六章进行总结。第2章 背景
信息检索(IR)是一个较广的领域, 一般符合如下定义: 是对信息项进行数据表示, 存储, 组织和访问的领域。
作为一个较广的领域, 信息检索必须要能够在对信息进行处理后,用户就能够容易地访问到他们关注的信息。 另一个也不失一般性的定义,描述如下:信息检索是从大量数据集合(通常是存放在本地服务 器或者互联网上)中, 查找满足需求的非结构化(文本)数据(文档)集。
核心思想是从可以获取到的数据中,检索出具有相关性的部分来满足用户的信息需求。 为了实现这个目的, 信息检索(IR)系统由几个相互关联的模块组成(图2.1)。通常这些模块含有三个方面的: 索引, 查找和排 序。
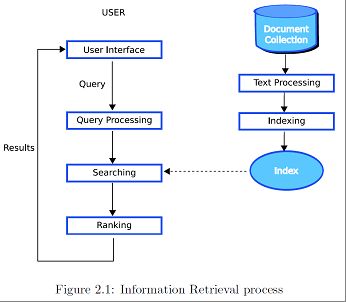
图2.1:信息检索过程
索引:负责表示和组织所有信息, 实现高效的信息访问。
查询:从索引中抽出满足用户需求的信息。
排序:尽管这是非必须的步骤, 但对检索来说非常重要, 启示式地对检索结果尽可能按照满足用户需求的方式排序。
2.1 文档收集要有信息可以检索的话,就要先收集信息,作为索引的入口数据。待收集文档可以是任何类型的数据,只 要能从中抽取出信息来。 这就有很多场景了, 要具体看检索系统的应用背景了。
2.1.1网页抓取在网页搜索的场景中, 网络爬虫是相当必要的。 简单来讲,爬虫是能够在网站间游走, 并且将访问过的页面下载保存下来。 网络爬虫种类很多, 有 些是商业的, 也有开源的。 由于网页是海量的, 所以为了平衡新页面的抓取和已抓取页面的更新, 会采用各种的抓取算法。 同样的, 也有必要考虑被抓网站的带宽情况, 避免把对方网站抓瘫痪了。
2.1.2文本检索大会TREC也有已经生成好的文档集合是被用来做学术研究的。 例如, 文本检索大 会(TREC)就 准备了大小和类型不同的好几类文档集合,每个都是为不同任务设计的。根据对文档不同的研究目的,研究被分成各种项目类型。 例如2007 TREC的项目类型有:
博客组: 目的是展现博客环境中的信息查找的行为规律。
企业组: 分析企业搜索。满足用户查找企业数据来完成某些任务。
基因组: 在特定领域的检索研究(基因数据)。
垃圾组: 对已有的和推荐的垃圾过滤方法进行研究。
利用这些文档集合, TREC也作为一个标准的数据集实例, 被各个小组采用各种方法去处理, 然后基于这相同的实例进行分析得到的不同结果, 来讨论和比较不同检索方法。 所以TREC也提供一组检索任务和查询结果相关性的判断。

Table 2.1, 倒排索引举例, 对 每个出现的词, 都保存了在文档中的位置列表
这样才使得研究不同信息检索(IR)系统的准确率和召回率成为可能。
2.2 索引
要实现对大文档集合的高效率的检索, 就需要重新组织数据, 存储到特定的设计好的数据结构中。 这就是索引, 它使 得快速检索文档集合变得容易, 简单来说, 就是减少两两比较的次数。在文本检索中, 最常用的数据结构是倒排索引(见表2.1), 它包含一个 词典, 词典包含了所有在文档中出现的词汇。 同时, 词典中每个单词映射了一个位置列表, 列出这个单词在哪些文档中出现了, 以及出现的位置信息。 当然不同应用对应的需求的类型也不同, 在一些应用中, 会将文档自身给出来,而不仅仅是位置信息,这依然是一种倒排索引。
索引存储需要的空间和文档集合的大小成正比关系, 有些方法可以用来减少和优化存储需要的空间。 通常来说, 一个词 典需要的存储空间不大, 但是位置列表的存储需要极大的空间。 另外, 一个搜索引擎的功能也决定着存储空间的大小,这就需要在提供哪些功能和存储空间之间进行平衡。 例如,为了给出用户检索词周围的文本片段, 有些索引存储了文档的全文,而另外一些索 引则不提供文本片段, 这样需要的存储空间就较少。 一些索引对位置列表进行压缩, (例如采用段地址, 将文本切成段,使得多个实例都被划分到较少的段中, 而索引地址就指向这些段), 但是这种方式的代价是要精确地获取单词的位置时, 需要额外开销(在本文的例子中需要顺序扫描目标段)。
在索引之前, 有个 几预处理需要完成,其中最常见的是停用词消减,和词根替换。
有些词在文档中出现的极为频繁, 但是对检索而言,它们的相关性却很小(例如, 在英文中, “a”, “an”, “be”, “for”)[对应到中文, “的”, “是”,“这”, “那”等 ]。 它们被称为停 用词, 不同的应用和不同的语言,有着不同的停用词表。 所以停用词消减成为一种常做的预处理,从文本中除去这些停用词,不索引它们,这就大大减少了倒排索 引的大小。
另一个叫词根替换, 这 也很常见, 除了用户检索的词外, 出现在文本当中的这个词的变体形式, 例如复数和过去式,也希望能够被匹配。 为了解决这个问题,一些索引采用获取词根的算法, 在查询的时候用词根来进行替换。 词根一般是不带词缀的部分。例如“connect”是“connected”“connecting”“connection”“connections”的词根。
预处理也好, 索引 结构也好,在影响存储空间的同时,也会影响索引的时间开销。之前提过, 根据不用的应用需求, 建索引过程中可能要在时间开销作出牺牲, 以便获得一个更省空间的索引存储。 当然, 索引的特性 也会影响查询, 在本文后面会有说明。
开源搜索引擎的比较(二)
利用倒排索引, 查询会变得相当的快捷, 基本上,查询的主要步骤是:
1. 词典查找, 查询词会被切分成一组单词,然后在在词典上找索引。 这个过程可以通过对词典排序, 而变得很迅速。
2. 检索是否存在, 如果在词典中定位到词了, 就在找对应的位置列表,看是否存在文档。
3. 结果处理, 为了得到查询词的结果, 需要对找到的结果列表进行再处理。
根据查询词的类型(布尔型的, 近似匹配, 使用通配符)不同, 操作会不一样, 而且意味着需要对结果做额外处理。 例如, 布 尔型查询是最常见的, 是由一组查询词(原子的)通过布尔运算(与,或,非)来进行组合, 以便查到的文档满足这些运算条件。
利用倒排索引可以解决这类查询, 唯一要做的处理只是合并各个查询词的位置列表, 然后按照布尔条件要求来选择满足条件的位置。 另一方面, 单词组 合和近似查找这两个查询类型的处理相对困难, 需要对结果进行复杂的处 理。 单词组合是指一组词汇以特定的模式在文档中出现。 而近似查找则是一种相对弱的关联关系的处理, 单词可能相距一定的距离, 但是依然满足出现的顺序。 对于这些查询, 有必要对结果按照单词的位置进行排列, 然后再对结果位置列表进行模式匹配。
在查询完索引之后, 需 要对结果按照用户需求进行排序。 这个排序阶段是可选的, 不是必须的。 但是对于网页搜索的场景来说, 这个阶段非常重要。 影 响排序的因素除了查询的结果文档是否匹配查询词外,还有很多其他附加因素。 例如, 在 某些应用下, 文档的大小会暗示文档的重要程度。 在网页搜索场景, 另 一个因素是检索的页面是否“流行”(例如综合考虑网页的入链和出链,页面已经存在的时间等等)。 查询词命中的位置(例如是在标题里面命中呢, 还是正文里面命中), 等。
2.4 检索评估
为了分析一个检索系统的质量, 需要研究由系统返回的结果是否和输入的查询词匹配。这可以如此来实现, 给定一个查询词和一组文档, 文档可以划分为与查询词相关的部分和不相关的部分。然后与由检索系统返回的结果相比较。
为了形式化表示质量,有几组定义好的质量评价指标可用。本文只关 心准确率和召回率以及两者之间的关系。 给定一个查询词q和文档集合I, 用R来表示相关的文档。 用A来表示搜索引擎检索到的文档集合, 当提交了查询词q之后, Ra表示由系统检索到的,并且相关的文档。 我们定义如下:
召回率:检索系统返回的结果中,与q相关的部分与所有相关的文档的比值。
Recall = |Ra|/|R|.

(1)1个搜索引擎的数据。 (b)3个搜索引擎的数据。
图2.2:平均准确率/召回率
准确率: 检索系统返回的结果中,与q相关的部分与所有返回的文档的比值。
Precision = |Ra| / |A|
由于单个质量指标自身可能不足以描述检索系统的质量(例如, 一个检索系统要得到100%的召回率, 只要返回所有的文档集合)。 只有通过组合以上指标才能来分析评价。 例如, 为了从趋势图上分析一 个检索系统的质量。 可以在平面图上描出平均的准确率召回率(如图2.2), 然后再来观察这个系统 的准确率和召回率。平面图在比较评价不同的搜索引擎的时候也是有用的。 例如, 图2.2 (b)观察3个搜索引擎的曲线。 我们发现搜索引擎2在低召回率的时候,准确率比其它的搜索引擎要低, 但是随着召回率的增加, 它的准确率比较平缓, 不像其它引擎退化的那么厉害。
另外一个常用标准是在截取部分结果后来统计准确率。 例如,分析返回的结果文档的前五个的准确率。 经常叫为前n值准确率,(P@n), 之所以采用这个标准, 主要用户一般习惯于只 查看返回结果的前n个, 而不是遍历全部的返回结果。
正如上文提到的, 要分析准确率和召回 率,就要对全部文档,分析每个文档和查询词的相关性。 并且需要由领域专家来 分析查询词对应的需求含义。但是有时候,这种分析变得难以实现, 因为整个文档集合会因 为过大而不容易分析, 或者用户的查询词所代表的含义并不清楚。 为了避免类似的问题, TREC大会也提供了一组查询词(或者相关主体)和对应的相关的文档(相关性判断)。 利用每个方向所提供的文档集合,和已经定义好的一组主题,以及使用该数据 的意义, 这些就可以在被研究的检索引擎上进行查询, 然后对返回的相关的结果集合进行分析。
第3章 搜索引擎
开源搜索引擎还挺多的。 在本文中,列出了目前主流的搜索引擎, 并且对它们进行了初步的评价, 以便给出一个总体上的 印象。 初步评价用到的标准包括: 开发现状, 项目活跃度, 最后更新时间。 我们比较了29个搜索引擎项目: ASPSeek, BBDBot, Datapark, ebhath, Eureka, ht://Dig, Indri, ISearch, IXE, Lucene, Managing Gigabytes (MG), MG4J, mnoGoSearch, MPS Information Server, Namazu, Nutch, Omega, OmniFind IBM Yahoo! Ed., OpenFTS, PLWeb, SWISH-E, SWISH++, Terrier, WAIS/ freeWAIS, WebGlimpse, XML Query Engine, XMLSearch, Zebra, 和 Zettair。
基于本文收集到的信息, 可以除去部分项目, 因为它们已经太过时了(最后更新时间要早于2000年)。这些项目不死不活的, 又无法得到更多信息。 因此我们除去了ASPSeek,
BBDBot, ebhath, Eureka, ISearch, MPS Information Server, PLWeb, 和 WAIS/freeWAIS.
另外, 也有项目由于其它原因 被丢弃了。 例如尽管MG项目是该领域一个相当重要的工作, 但是由于从1999后就再没有更新过。另外Nutch项目也被忽略了,因为它只是Lucene项目的一次调用。 因此我们只分析Lucene项目。 最后, XML Query引擎和Zebra引擎也被忽略了, 因为这两个项目是专注 于结构化数据(XML),而不是半结构数据(HTML)的。
因此, 剩下来, 本文要覆盖的当前的项目是: Datapark, ht://Dig, Indri, IXE, Lucene, MG4J, mno-GoSearch, Namazu, OmniFind, OpenFTS, Omega, SWISH-E, SWISH++, Terrier, WebGlimpse (Glimpse), XMLSearch, and Zettair。 但是,经过很初步的测试, 就最小的数据集合而言, 本文发现, Datapark, mnoGoSearch, Namazu, OpenFTS, 和 Glimpse的建索引的时间开销是其余项目的建索引时间开销的3到6倍。 因此我们也将它们 排除在外了。
3.1 特征
前面提到, 每个搜索引擎都可以依据它们实现的特性,以及在不同场景下的表现来进行划分。 本文通过分析这些搜索引擎的功能以及内在特性, 给定了13个常用特征来描述划分这些搜索引擎。
存储方式: 索引的存储方式, 要么是用数据库存储或者仅采用文件结构存储。
增量索引: 是否支持向已有的索引 追加新的文件集合, 而不用重新生成整个索引。
结果摘要: 是否支持对结果提取摘 要信息。
结果模板: 部分引擎支持模板来提 前结果信息。
停用词表: 建索引的时候,开放停 用词表接口,可以通过增减高频词,来去掉这些高频词。
文件类型: 索引可以解析的文件的 类型。最常用的类型是HTML。
词根替换: 索引和检索是否支持词 根替换。
模糊查找: 是否支持模糊查找, 而不要精确匹配。
结果排序: 根据不同的标准对结果 进行排序。
排序策略: 在提供查询结果的时 候,采用的排序策略。
搜索类型: 是否支持查询词的组合 操作。
编程语言: 建索引实现的编程语 言。 这个信息在对项目进行扩展或者继承的时候会相当有用。
版权信息: 指明允许使用和二次开 发的条件。
在表3.2中列出了每个搜索引擎的特征信息。 为了决定采用哪个搜索引擎, 有必要将所有特征来整体分析, 并且要补充上性能评估 的信息。
简单描述一下将要分析的每个搜索引擎, 主要有谁在哪里开发的, 和项目赖以著称的特征。
ht://Dig, 提供一组工具可以索引和搜索一个站点。 提供有一个命令行工具和CGI界面来执行搜索。尽管已经有了更新的版本了, 但是根据项目的网站, 3.1.6版是最快的版本了。
IXE Toolkit, 是模块化C++类集合, 有一组工具完成索引和查询。Tiscali(来自意大 利)提供有商业版本, 同时提供了一个非商业版本仅用于科学研究。
Indri, 是基于Lemur的搜索引擎。Lemur是用来研究语言模型和信息检索的工具。这个项目是马萨诸塞大学和CMU的合作项目的产物。
Lucene, 是Apache 软件基金会的一个文本搜索引擎库。 由于它是一个库, 所以很多项目基于这个库, 例如Nutch项目。在目前, 它 捆绑自带的最简单的应用是索引文档集合。
MG4J(管理前兆数据Java语言)是针对大文本集合的一个全文 索引工具。由米兰大学开发。他们提供了通用的字符串和位级别的I/O的优化的类库作为副产物。
Omega, 基于Xapian的应用。Xapian是开源的统计信息检索库, 由C++开 发, 但是被移植到了(Perl Python php, Java, Tcl, C#)等多种语言。
IBM Omnifind Yahoo! Edition, 非常适合内网 搜索的搜索软件。 他结合了基于Lucene索引的内网搜索,和利用Yahoo 实现的外网搜索。
SWISH-E(简单网页索引系统—增强版), 是开源的索引和检索引擎。是Kevin Hughes 开发的SWISH的增强版。
SWISH++是基于SWISH-E的索引和检索工具。尽管经过C++全部重写, 但是 没有实现SWISH-E的全部功能。
Terrier(太字节检索), 由苏格兰的格拉斯哥大学开发的,模块化的平台,能够快速的构架互联网, 内网, 和 桌面的搜索引擎。 它附带了索引,查询和评估标准TREC集合的功能。
XMLSearch, C++开发的索引和检索的一组类。利用文本操作(相等,前缀,后缀,分段)来扩展了查询能力。 Barcino(来自智利)提供了一个商 业版, 同时也有个供学术研究的非商业版。
Zettair,(先前称为Lucy), 由皇家墨尔本理工大学的搜索引擎小组开发的文本检索引擎。主要特征是能够处理超大量的文本。
史春奇,
搜索工程师,
中科院计算所毕业,
开源搜索引擎的比较(三)
3.2 评估
正如先前提到, 每个搜索引擎都有多个特征来区分它自己。 要对这些引擎做个对比的话, 本文期望有一个较好的质量评估流程来给用户一个客观的的打分, 以便区分这些搜索引擎的效果。 如何选择最好的搜索引擎, 这个问题的解决依赖于每个用户的特定需求和相应搜索引擎的主要目标。例如, 评估可以从易用性的角度入手, 每个引擎的方便程度如何, 拿来就能用? 对它二次开发的难度有多大?这基本上由搜索引擎 的主要特征来决定。 例如, Lucene只想做一个索引和检索的API, 但如果你想利用Lucene的特性来做你的前端的话, 你就需要关注对应的下游项目Nutch。 另外一种可能是 分析公共的特性,例如索引和检索的性能,这些特征可能很适合分析,但是要注意的是,你必须仔细分析, 因为这不是唯一特征。 因此,本文的比较基于如下可以计量的参数(索引时间, 索引大小, 资源消耗, 查询时间, 准确率, 召回率等)。 最后,我们提供几个用例和每个用例的可替代方案。
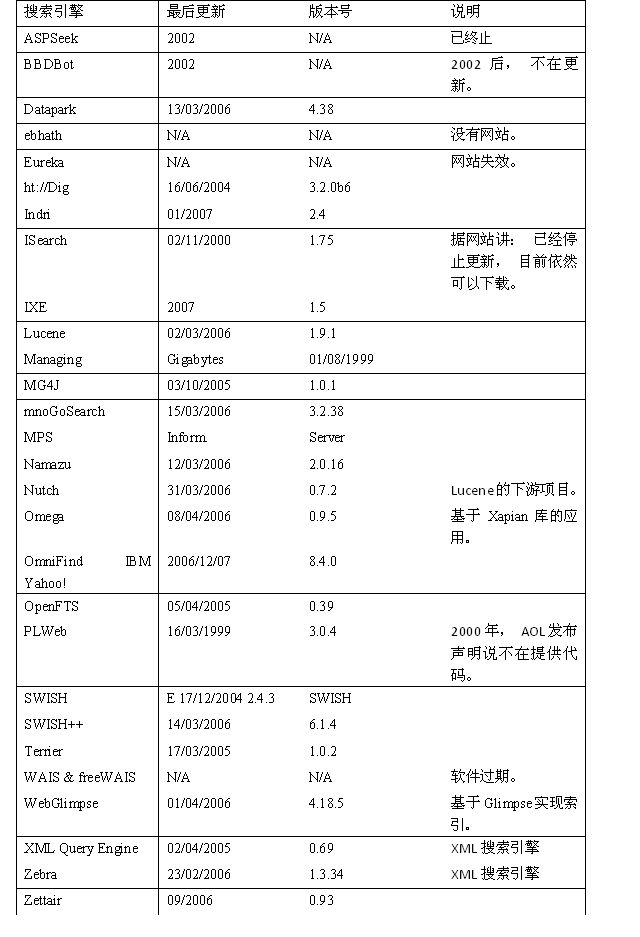
表3.1:可用的开源搜索引擎的基本特性。
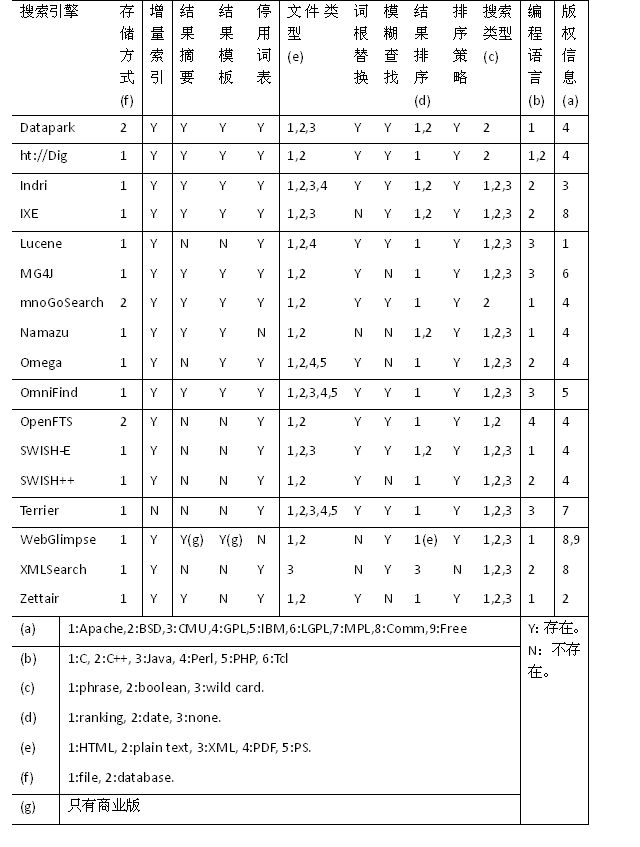
表3.2:分析开源搜索引擎的主要特点。
第4章 比较方法
本文的目的是在不同的场景下比较开源搜索引擎的性能(例如, 使用不同大小的文档集合), 然后用共同的标准去评估他们。 为了完成这项工作, 将采用如下步骤。
1. 获取HTML文档集合。
2. 确定用来监控搜索引擎性能的工具。
3. 安装和配置每个搜索引擎。
4. 索引每个文档集合
5. 处理和分析索引结果
6. 进行查询
7. 分析查询结果。
4.1 文档收集
为了比较不同的搜索引擎的性能, 有必要选择几个大小不同的文档集合, 从小于1G的文本,到2.5G或者3G的文本。 另外一个 是文本的类型考虑, 常用于搜索引擎分析的文本类型是HTML。 要收集3G的HTML数据, 一种方法是抓取一个在线网站作为数据集合,但由于本文关注于索引的能力和性能, 所以还是就用本地数据。
选择了一个TREC-4的文本集合, 这 个集合有许多文件, 分别对应到华尔街时报, 美联社, 洛杉矶时报,等等。 每个文件都是SGML的格式。 需要先 解析数据, 生成HTML的文档,每个大约是500kB的样子。 最后这 个数据集分成了3个 不同大小的组, 一个750MB(1,549个文档) ,一个1.6GB(3,193)个文档, 另外一个2.7GB(5,572个文档)。
最后, 进一步使用 了WT10g TREC 网页(WebTREC)的数据进行比较。 这 个集合包含了1,692,096个文档。 划分成5117个文件。 总大小是10.2GB。 这个文档集合 又被分成不同大小的组(2.4GB, 4.8GB, 7.2GB, 10.2GB), 被分别用来测试对应的索引时间。 查询的测试是基于整个WT10g的数据集的。
4.2 测试比较
我们在文档集合上运行了5个个实验。 前3个个实验是基于解析好的文档集合(TREC-4)。 而后两个个实验是基于WT10g WebTREC的数据集的。 第一个实验, 记录 每个搜索引擎的索引数据的时间开销和资源开销。 第二个实验,将第一个索引测试的优胜者作为候选集, 进行查询测试, 并且记录查询时间开销和针对不同数据集来分析性能。 第三个测试比较增量索引的时间开销。 所有的索引流程是在同一个电脑上依次执行 的。 第四个测试比较针对有能力索引全部文档的搜索引擎, 在WT10g WebTREC的不同大小的数据集上统计索引时间开销。 最后, 第 五个实验使用WT10g的全部数据,并且采用一组查询词来分析查询时间开销,准确率和召回率。
4.3引擎安装
所用计算机主要性能: 奔腾四3.2GHz处理器, 2G内存, SATA硬盘, 运行Debian Linux(内核2.6.15)。 为了分析每个搜索引擎在索引过程中的资源开销, 必须要有监控工具。 目 前有几种资源监控工具可供选择, 例如“Load Monitor”和“QOS”。 但对于本文的工作, 只 要一个简单的监控就能完成。 因此我们只是实现了一个后台进程来记录每个 进程在一段时间内的CPU和内存的开销。毕竟, 这些信息解析出来后很容易用Gnuplot来制图。
史春奇,
搜索工程师,
中科院计算所毕业,
开源搜索引擎的比较(四)
这个索引测试记录每个搜索引擎在索引过程中的时间开销和资源开销(CPU, 内存占用, 索引磁盘占用)。 在 每个测试阶段之后, 都会分析时间开销, 只有时间开销合理的搜索引擎才被用来进行下一轮更大数据集的测试。 本文根据之前的观测, 主观地定义合理的时间开销是不超过最快搜索引擎时间开销的20倍。
索引时间
图5.1, 本文图形化的比 较了能够索引全部文档集合(占用合理的时间开销)的搜索引擎性能。 在第3章提到, 本文忽略了Datapark, Glimpse, mnoGoSearch, Namazu, 和 OpenFTS搜索引擎, 因为它们基于750MB的数据的索引时间开销要花费77到320分钟, 和其他搜索 引擎相比, 它们是在太差劲了。 根据观测可以发现, 所有采用数据库作为索引存储的搜索引擎的索引时间开销都会比其他搜索引擎要大非常多。
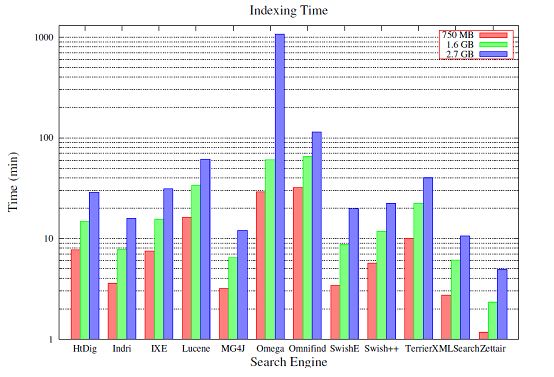
图5.1 不同文档大小(750MB, 1.6GB, 2.7GB)的索引时间开销比较。
对于750MB数据集合, 搜索引 擎建索引的时间开销是1~32分钟。 而对于1.6GB的数据集合, 时间开销是2分钟~1个小时。 最后2.7GB的数据建索引的时间开销是5分钟~1小时, 但是Omega相当例外,大数据的索引时间开销要达到17小时50分钟。
内存和CPU开 销
利用第4章提到的监控工具, 本 文分析索引阶段的搜索引擎的运行。 记录内存开销占总内存的比例。 据观察, CPU开销在索引阶段几乎是一个常数, 差不多都是100%的CPU。 同时, 观察到6种不同的内存使用情况。 类型有保存不变(C), 线性变化(L), 阶梯变化(S),和组合情况:线性再阶梯变化(L-S), 线性再保持 不变(L-C), 阶梯变化再保持不变(S-C)。 ht://Dig, Lucene, 和 XMLSearch在建索引过程中有稳定的内存占用。 MG4J, Omega, Swish-E, and Zettair表现为线性的增长。Swish++则是像阶梯变化, 例如开始占用了一些内存, 然后保存一段时间不变, 之后再占用更多的内存。Indri则是线性增长, 然 后忽然释放全部已经占用的空间, 然后又开始线性增长。 Terrier则是开始是阶梯状的使用内存, 然后忽然释放部分空间, 再变成稳定地使用内存,这样一直到索引结束。 最后Omega是一个线性的增长, 当 到了1.6GB的 时候, 开始保存不变。
索引存储空间占用
在表5.2中列出了能够在合理的时间开销内索引全部文档集合的搜索引擎的索引的大小。 据观察分为3个组, 索引只占 数据集合大小的25%~35%的一组, 还有一组是50%~55%, 最后一组甚至超过100%的数据集合大小。
本文也测试了增量索引的时间开销, 增量大小设置成初始大小的1%, 5%和10%。 基于1.6GB的数据集, 每个增量的文档都是原来集合里面所没有出现过的。 比较ht://Dig, Indri, IXE, Swish-E, 和 Swish++。 图5.2 给出了它们的增量索引时间开销的比较。
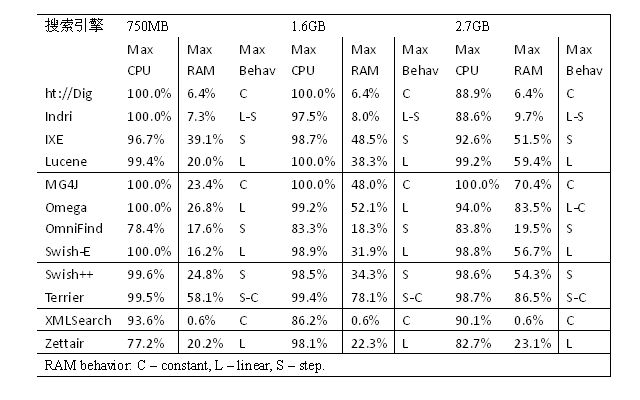
表5.1:最大的CPU和内存使用率,内存变化,每个搜索引擎的索引(数据集750MB,1.6GB和2.7GB)。
5.1.2 索引WT10g的分组。
另外一个实验是在WebTREC(WT10g)数据集合上完成的, 统计不同的分组的建索引的时间开销。 关注了两组搜索引擎:具有索引原文件格式的能力的搜索引擎(每个文件包含一组记录包含原 始的HTML页 面)。 另外一组不能理解文件格式,需要解析数据集合, 并且抽出每个HTML页面。Indri, MG4J, Terrier, 和 Zettair是能够直接索引WT10g文件, 不需要任何修改。ht://Dig, IXE1, Lucene, Swish-E, 和 Swish++需要解析数据。XMLSearch没有包含在这次的观测 内, 因为它没有对结果做Rank。
首先,我们在WT10g数据集合(10.2G)上测试了通过上一阶段测试的搜索引擎。只有Indri, IXE, MG4J, Terrier, 和 Zettair能够索引整个数据 集合,并且时间开销也只是线性地增长(和它们在上一阶段测试的时间相比)。 其他的搜索引擎的时间开销会暴涨或者由于内存不足而出现崩溃。 ht://Dig 和 Lucene花费了7倍的预期建索引的时间, 并且超过了20倍最快的搜索引擎(Zettair)的时间开销。而Swish-E和Swish++由于内存不足而崩溃了。基于上述结果, 本文考察了各个分组(2.4G,4.8G, 7.2G和10.2G)的建索引时间。 在图5.3给出了能够索引整个数据集的搜索引擎建索引的时间开销。 可以看出, 这些搜索引擎的时间开销是成线性正比增长的。

表5.2:每个搜索引擎的索引大小,数据分组(750MB, 1.6GB, 和2.7GB.) 。
5.2 查询
查询实验是基于一组必须有结果的查询词, 然后再比较搜索引擎检索的结果的准确级别。 真正的准确结果在查询词和数据集给定之后,也就被定义好了。 为了得到待查的查询词, 本文考察了三种方法。
1. 利用查询日志来找到真实查询词。
2. 基于数据集的内容来生成查询词。
3. 采用预定义的查询词, 而且这些词和数据集的内容非常相关。

图5.2:增量索引的时间开销
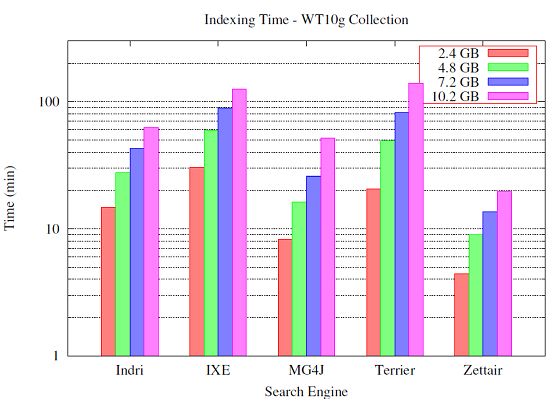
图5.3:WT10g数据集的索引时间。
第一种方法,使用查询日志,似乎很有吸引力,因为这是一种逼近现实情况的方式来测试搜索引擎。这种方 法的问题是,要保证相关性,就要求数据集和查询日志具有一定相关性, 例如,我们要去拿一些抓取到的网页和一组能够覆盖这些网页的查询日志。由于在以前的实验 中, 本文使用了TREC-4的数据集,这个数据集是基于一组新闻文档的。没有和这些文档相关的日志文件。因此本文采用的方法是 利用文档包含的关键词和词的分布而随机生成的查询词(5.2.1里面有详细描述)。 最 后,更完整的测试环境可以利用一组预定义好的查询词, 并且这些词是和文 档集合相关的。 这些词可以用到第二组实验中,这个实验中用到了TREC大会提供的评估用的WT10g的数据集。 这个方法看上去是可控情况下最完整和最接近真实情况的。
根据上述理由, 本文在TREC-4数据集的实验中, 采 用一组随机生成的查询词。而测试WT10g TREC的数据时,就用已经提供的一组主题和查询词。

图5.4:WT10g数据集上的平均准确率/召回率。
5.2.1 TREC-4数据集的查询实验
查询实验用到了三个文档集合, 选择了在建索引实验中有较好性能表现的搜索引擎(例如ht://Dig, Indri, IXE, Lucene, MG4J, Swish-E, Swish++, Terrier,XMLSearch, 和 Zettair)。 测试包含了一 个词和两个词的查询词,这些查询词来自从每个集合文档生成的一个词典。然后分析每个搜索引擎的查询时间, 以及检索百分比(译者: 检索覆盖率)。 检索百分比是某个搜索引擎检索到的文档数量与全部搜索引擎检索到文档全集总数的比值。 为了生成查询词, 本文随机地从词典里面选择1或者2个词,要求这些词在所有的文档里面都出现了, 但是不是停用词,并且考虑如下几种词的分布情况。
1. 词的原始分布(幂定律)。
2. 5%的最常用词的归一化分布。
3. 30%的最稀少的词的归一化分布。
每个数据集合所用的查询词要考虑词典以及词在这个数据集的分布情况。 每个数据集的词频都符合齐夫定律。 (译者:齐夫定律是由哈佛大学教授G.K.Zipf在1935年对文献词频研究的结论:一篇较长的文章中每个词出现的频次从高到低进行递减排列,其数量关系特征 呈双曲线分布。)

图5.5:平均查询时间(2.7 GB数据集)。
查询时间和检索百分比
在生成了1个单词和2个单词的查询词之后(每组包含100个查询词), 就能够考察每个集合的平均查询时间和检索百分比了。 对于2个单词的查询, 本文考察了每个单词的匹配情况(使用“或”布尔逻辑)。 在图5.5 本文给出了在2.7G数据集上的平均检索时间的比较图。
查询结果表明能够胜任查询阶段 的搜索引擎在每个词组的查询时间开销都差不多。 平均而言, 提交1个单词和2个单词的查询时间大约是1:1.5或者1:2的样子, 是一个线性的增长。 最快的搜索引擎是Indri, IXE, Lucene, 和 XMLSearch。 然后是MG4J和Zettair。 它们的检索百分 比也非常的相近, 但是在数据集增大并且采用30%的低频查询词的时候, 检索百分比骤降。
内存开销
在检索阶段, 本文观察到4种内存开销变化, Indri, IXE, Lucene, MG4J, Terrier, 和 Zettair的内存开销比较稳定(1%-2%的内存开销)和检索的数据集的大小无关。 XMLSearch的内存开销最小并且比较稳定, 但是它的内存开销和数据集的大小相关(0.6%, 0.8%和1.1%,分别对应到三个数据集)。Swish++的内存开销分别对应到三个数据集是线性增加到2.5%, 3.5%,和4.5%。Swish-E 和 ht://Dig的内存开销相对较大,有一个稳定的突出曲线。Swish-E用了10.5%的内存, 而ht://Dig用了14.4%的内存。
5.2.2 准确率和召回率的比较
利用基于WT10g生成的索引,可以分析每个搜索引擎的准确率和召回率。 本文用了在TREC-2001Web会议中主题相关的课题中使用的50个主题(利用只有标题含有的查询词), 已经知道了这些词的相关性判断。 为了每个搜索引擎有一个共同的应用场景, 本文没有使用任何词根替换, 或者查询词的停用词过滤等预处理,并且在多个单词之间使用“或”布尔逻辑。
最后, 对结果的处理使用了trec_eval软 件, 它可以用来对结果进行标准的NIST(国家标准局和技术研究所)的评估, 并且它是免费的。 程序会告诉你查询的常规信息(例如,相关文档的数量)以及准确率和召回率的统计。本文关注插值平均准确率/召 回率比值和不同水平的准确率。 平均准确率/召回率比值可以用于考察查询,进而比较搜索引擎的检索 性能。 另外, 本文也比较了不同截断的准确率, 以便跟踪在不同阈值的检索表现。
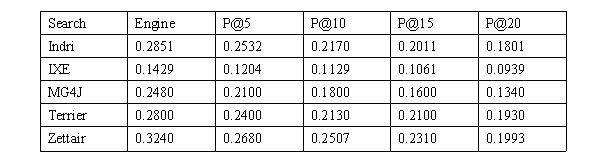
表5.3 WT10g数据集上检索结果的质量。
史春奇,
搜索工程师,
中科院计算所毕业,
你可能也喜欢
 2014年6月最新微博段子语录汇编——中国大妈
2014年6月最新微博段子语录汇编——中国大妈