深度学习之反向传播算法的直观理解
深度学习之反向传播算法的直观理解
如何直观地解释 backpropagation 算法?
https://www.zhihu.com/question/27239198
BackPropagation算法是多层神经网络的训练中举足轻重的算法。简单的理解,它的确就是复合函数的链式法则,但其在实际运算中的意义比链式法则要大的多。要回答题主这个问题“如何直观的解释back propagation算法?” 需要先直观理解多层神经网络的训练。机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。深度学习同样也是为了这个目的,只不过此时,样本点不再限定为(x, y)点对,而可以是由向量、矩阵等等组成的广义点对(X,Y)。而此时,(X,Y)之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络来表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。借用网上找到的一幅图[1],来直观描绘一下这种复合关系。
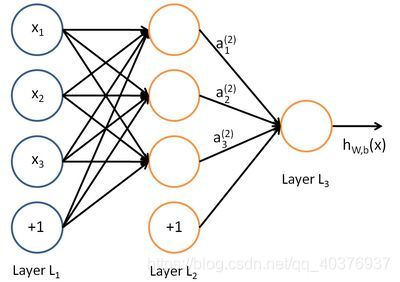
其对应的表达式如下:
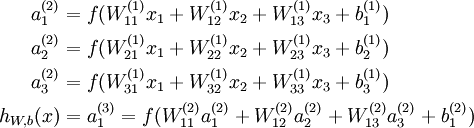
上面式中的Wij就是相邻两层神经元之间的权值,它们就是深度学习需要学习的参数,也就相当于直线拟合y=kx+b中的待求参数k和b。和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用成本函数(cost function),然后,训练目标就是通过调整每一个权值Wij来使得cost达到最小。cost函数也可以看成是由所有待求权值Wij为自变量的复合函数,而且基本上是非凸的,即含有许多局部最小值。但实际中发现,采用我们常用的梯度下降法就可以有效的求解最小化cost函数的问题。梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到cost收敛。那么如何计算梯度呢?假设我们把cost函数表示为, 那么它的梯度向量[2]就等于, 其中表示正交单位向量。为此,我们需求出cost函数H对每一个权值Wij的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。我们以求e=(a+b)(b+1)的偏导[3]为例。它的复合关系画出图可以表示如下: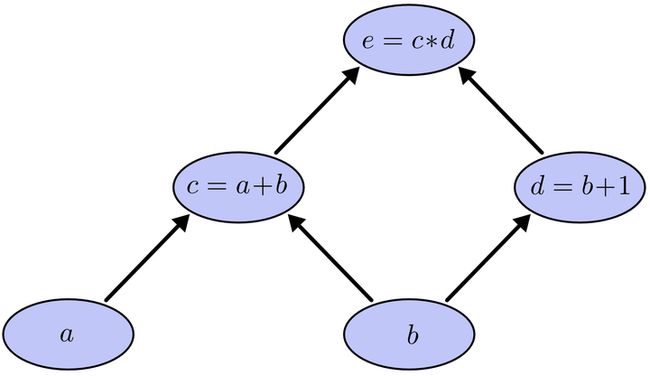 在图中,引入了中间变量c,d。为了求出a=2, b=1时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。
在图中,引入了中间变量c,d。为了求出a=2, b=1时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。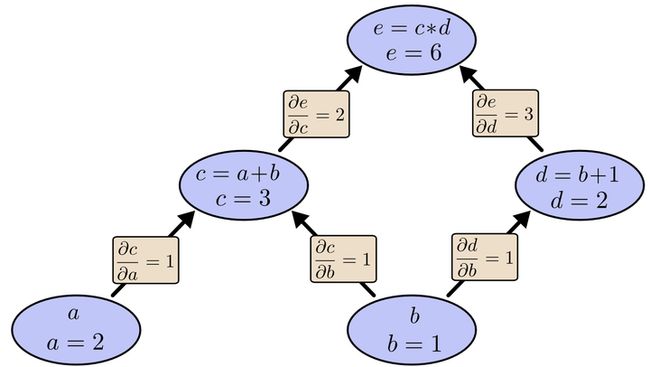 利用链式法则我们知道:以及。链式法则在上图中的意义是什么呢?其实不难发现,的值等于从a到e的路径上的偏导值的乘积,而的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到的值。大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放"些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以"层"为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。以上图为例,节点c接受e发送的12并堆放起来,节点d接受e发送的13并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送21并对堆放起来,节点c向b发送21并堆放起来,节点d向b发送31并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为21+3*1=5, 即顶点e对b的偏导数为5.举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即c→e表示e欠c的钱。以a, b为例,直接计算e对它们俩的偏导相当于a, b各自去讨薪。a向c讨薪,c说e欠我钱,你向他要。于是a又跨过c去找e。b先向c讨薪,同样又转向e,b又向d讨薪,再次转向e。可以看到,追款之路,充满艰辛,而且还有重复,即a, b 都从c转向e。而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
利用链式法则我们知道:以及。链式法则在上图中的意义是什么呢?其实不难发现,的值等于从a到e的路径上的偏导值的乘积,而的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到的值。大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放"些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以"层"为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。以上图为例,节点c接受e发送的12并堆放起来,节点d接受e发送的13并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送21并对堆放起来,节点c向b发送21并堆放起来,节点d向b发送31并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为21+3*1=5, 即顶点e对b的偏导数为5.举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即c→e表示e欠c的钱。以a, b为例,直接计算e对它们俩的偏导相当于a, b各自去讨薪。a向c讨薪,c说e欠我钱,你向他要。于是a又跨过c去找e。b先向c讨薪,同样又转向e,b又向d讨薪,再次转向e。可以看到,追款之路,充满艰辛,而且还有重复,即a, b 都从c转向e。而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
作者:Anonymous
链接:https://www.zhihu.com/question/27239198/answer/89853077
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
通俗理解神经网络BP传播算法
https://zhuanlan.zhihu.com/p/24801814
在学习深度学习相关知识,无疑都是从神经网络开始入手,在神经网络对参数的学习算法bp算法,接触了很多次,每一次查找资料学习,都有着似懂非懂的感觉,这次趁着思路比较清楚,也为了能够让一些像我一样疲于各种查找资料,却依然懵懵懂懂的孩子们理解,参考了梁斌老师的博客BP算法浅谈(Error Back-propagation)(为了验证梁老师的结果和自己是否正确,自己python实现的初始数据和梁老师定义为一样!),进行了梳理和python代码实现,一步一步的帮助大家理解bp算法!
为了方便起见,这里我定义了三层网络,输入层(第0层),隐藏层(第1层),输出层(第二层)。并且每个结点没有偏置(有偏置原理完全一样),激活函数为sigmod函数(不同的激活函数,求导不同),符号说明如下:

对应网络如下:
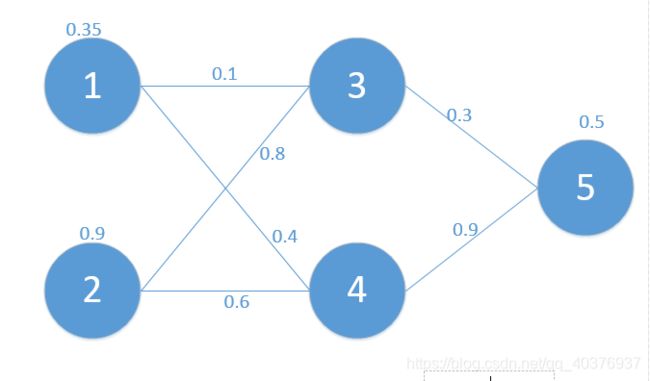
其中对应的矩阵表示如下:
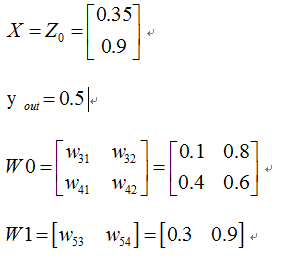
首先我们先走一遍正向传播,公式与相应的数据对应如下:

那么:
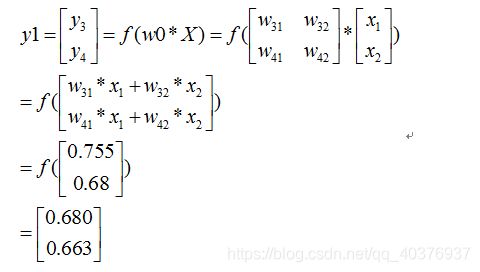
同理可以得到
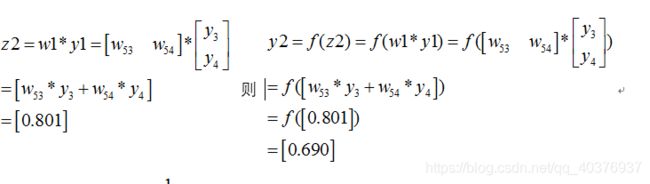
那么最终的损失为
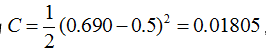
我们当然是希望这个值越小越好。这也是我们为什么要进行训练,调节参数,使得最终的损失最小。这就用到了我们的反向传播算法,实际上反向传播就是梯度下降法中(为什么需要用到梯度下降法,也就是为什么梯度的反方向一定是下降最快的方向,我会再写一篇文章解释,这里假设是对的,关注bp算法)链式法则的使用。
下面我们看如何反向传播
根据公式,我们有:
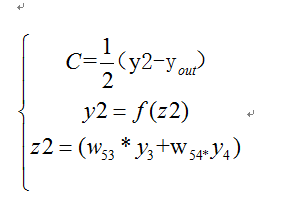
这个时候我们需要求出C对w的偏导,则根据链式法则有
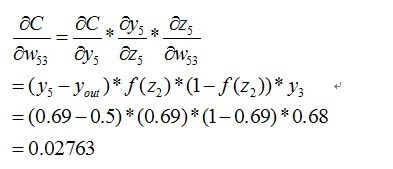
上面插入sigmod函数求导公式:
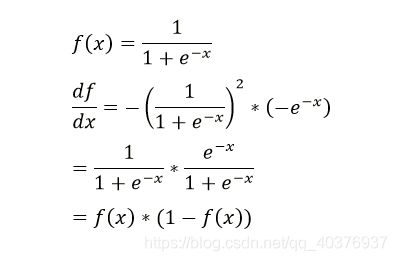
(在这里我们可以看到不同激活函数求导是不同的,所谓的梯度消失,梯度爆炸如果了解bp算法的原理,也是非常容易理解的!)
同理有
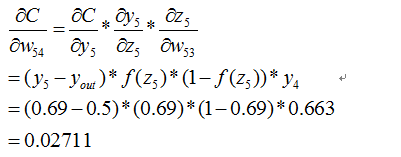
到此我们已经算出了最后一层的参数偏导了.我们继续往前面链式推导:
我们现在还需要求
![]()
下面给出其中的一个推到,其它完全类似

同理可得到其它几个式子:
则最终的结果为:

再按照这个权重参数进行一遍正向传播得出来的Error为0.165
而这个值比原来的0.19要小,则继续迭代,不断修正权值,使得代价函数越来越小,预测值不断逼近0.5.我迭代了100次的结果,Error为5.92944818e-07(已经很小了,说明预测值与真实值非常接近了),最后的权值为:

好了,bp过程可能差不多就是这样了,可能此文需要你以前接触过bp算法,只是还有疑惑,一步步推导后,会有较深的理解。
理解梯度下降
http://liuchengxu.org/blog-cn/posts/dive-into-gradient-decent/
什么是梯度
直接问梯度是什么,可能有些人会不知道怎么回答,下面给出两个选项:
1、梯度是一个数 (没有方向)
2、梯度是一个向量 (有方向)
直接上结论, 梯度是一个有方向的向量, 带着这个概念再来慢慢理解.
导数
导数的几何意义可能很多人都比较熟悉: 当函数定义域和取值都在实数域中的时候,导数可以表示函数曲线上的切线斜率。 除了切线的斜率,导数还表示函数在该点的变化率。

derivative(来自维基百科)
导数的物理意义表示函数在这一点的 (瞬时) 变化率。
偏导数
既然谈到偏导数,那就至少涉及到两个自变量,以两个自变量为例,z=f(x,y) . 从导数到偏导数,也就是从曲线来到了曲面. 曲线上的一点,其切线只有一条。但是曲面的一点,切线有无数条。
因为曲面上的每一点都有无穷多条切线,描述这种函数的导数相当困难。偏导数就是选择其中一条切线,并求出它的斜率。通常,最感兴趣的是垂直于 y 轴(平行于 xOz 平面)的切线,以及垂直于 x 轴(平行于 yOz 平面)的切线。
(来自维基百科)
一个多变量函数的偏导数是它关于其中一个变量的导数,而保持其他变量恒定(相对于全导数,在其中所有变量都允许变化)。
偏导数的物理意义表示函数沿着坐标轴正方向上的变化率。
方向导数
方向导数是偏导数的概念的推广, 偏导数研究的是指定方向 (坐标轴方向) 的变化率,到了方向导数,研究哪个方向可就不一定了。
一个标量场在某点沿着某个向量方向上的方向导数,描绘了该点附近标量场沿着该向量方向变动时的瞬时变化率。这个向量方向可以是任一方向。
方向导数的物理意义表示函数在某点沿着某一特定方向上的变化率。
梯度
说完方向导数,终于要谈到梯度了。
在一个数量场中,函数在给定点处沿不同的方向,其方向导数一般是不相同的。那么沿着哪一个方向其方向导数最大,其最大值为多少,这是我们所关心的,为此引进一个很重要的概念: 梯度。
假设函数在其一点 p0 处,那么它沿哪一方向函数值增加的速度能够最快?
摘自 梯度 维基百科:
在向量微积分中,标量场的梯度是一个向量场。标量场中某一点的梯度指向在这点标量场增长最快的方向(当然要比较的话必须固定方向的长度),梯度的绝对值是长度为1的方向中函数最大的增加率。以另一观点来看,由多变数的泰勒展开式可知,从欧几里得空间 Rn到 R 的函数的梯度是在 Rn 某一点最佳的线性近似。在这个意义上,梯度是雅可比矩阵的一个特殊情况。
在单变量的实值函数的情况,梯度只是导数,或者,对于一个线性函数,也就是线的斜率。
梯度一词有时用于斜度,也就是一个曲面沿着给定方向的倾斜程度。可以通过取向量梯度和所研究的方向的内积来得到斜度。梯度的数值有时也被称为梯度。
为什么沿着梯度方向函数增长最快
下面对为什么沿着梯度的方向函数增长最快进行证明:
证明准备
方向导数定义:

方向导数公式:

梯度公式:

从方向导数与梯度进行证明


总结
概念 物理意义
导数 函数在该点的瞬时变化率
偏导数 函数在坐标轴方向上的变化率
方向导数 函数在某点沿某个特定方向的变化率
梯度 函数在该点沿所有方向变化率最大的那个方向
函数在某一点处的方向导数在其梯度方向上达到最大值,此最大值即梯度的范数。
这就是说,沿梯度方向,函数值增加最快。同样可知,方向导数的最小值在梯度的相反方向取得,此最小值为最大值的相反数,从而沿梯度相反方向函数值的减少最快。更多内容可见:方向导数与梯度。
在机器学习中往往是最小化一个目标函数 L(Θ),理解了上面的内容,便很容易理解在梯度下降法中常见的参数更新公式:
Θ=Θ−γ∂L∂Θ
γ 在机器学习中常被称为学习率 ( learning rate ), 也就是上面梯度下降法中的步长。
通过算出目标函数的梯度(算出对于所有参数的偏导数)并在其反方向更新完参数 Θ ,在此过程完成后也便是达到了函数值减少最快的效果,那么在经过迭代以后目标函数即可很快地到达一个极小值。如果该函数是凸函数,该极小值也便是全局最小值,此时梯度下降法可保证收敛到全局最优解。
概念上大概理解了梯度下降,下一步便是写点代码来理解一下了,毕竟上面所述还是有些过于理论,有时间我会从代码实现与分析中进一步理解梯度下降, 敬请期待。