机器学习---规则学习(一阶规则学习、归纳逻辑程序设计)
1. 一阶规则学习
“一阶”的目的:描述一类物体的性质、相互关系,比如利用一阶关系来挑“ 更好的”瓜,但实际应用
中很难量化颜色、 …、敲声的属性值。一般情况下可以省略全称量词。
![]()
命题逻辑:属性-值数据
色泽程度:乌黑>青绿>q浅白;“根蒂弯度”:蜷缩>稍蜷>硬挺;“更好”:好瓜>坏瓜

关系型数据一阶逻辑:

序贯覆盖生成规则集:能否引入新变量?能否使用否定文字?能否允许递归?能否引入函数嵌套?
自顶向下学习单条规则,候选文字需考虑所有可能的选项:

规则生长的评判标准为FOIL增益: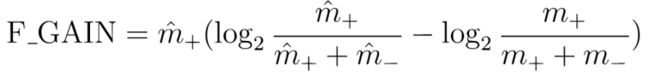
2. 归纳逻辑程序设计
目标:完备地学习一阶规则(Horn子句);仍然以序贯覆盖方法学习规则集,一般采用自底向上
策略学习单条规则。不需要列举所有可能的候选规则;对目标概念的搜索维持在样例附近的局部区
域;自顶向下策略的搜索空间对于规则长度呈指数级增长。
2.1 最小一般泛化(LGG) [Plotkin, 1970]:
“泛化”:将覆盖率低的规则变换为覆盖率高的规则;“一般”:覆盖率尽可能高;“最小”:变换时对原
规则的改动尽可能小。
寻找两条规则LGG的步骤:
①找出两条规则中涉及相同谓词的文字
②考察谓词后括号里的项:LGG(t,t)=t;LGG(s,t),s≠t;s, t不是谓词相同的项,则LGG(s,t)=V,V为
任意未出现过的变量;s, t为谓词相同的项,递归考察其括号内的项
③删除没有相同谓词出现的文字

其他基于LGG的ILP算法:考虑否定文字,不同的初始化选择,多条特殊规则,考虑所有背景知识
(RLGG) [Plotkin, 1971] …
2.2 演绎与归纳
“……猜想是很不好的习惯,它有害于作逻辑的推理。你所以觉得奇怪,是因为你没有了解我的思
路,没有注意到 往往能推断出大事来的那些细小 问题(the small facts upon which large
inferences may depend)。举例来说吧,我开始时曾说你哥哥的行为很不谨慎。请看这只表,不
仅下面边缘上有凹痕两处,整个表的上面还有无数的伤痕,这是因为惯于把表放在有钱币、钥匙一
类硬东西的衣袋里的缘故。对一只价值五十多镑的表这样不经心,说他生活不检点,总不算是过
吧!……。”
歇洛克·福尔摩斯 演绎法研究(The science of deduction)——《四签名》

演绎:归结原理

归纳:逆归结
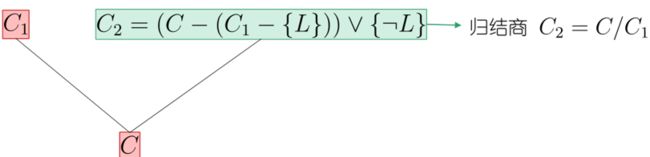
如何考虑带变量的逻辑表达式?
置换:用项替换变量:
θ={1/X,2/Y},C=色泽更深(X,Y)^敲声更沉(X,Y)
C'=Cθ=色泽更深(1,2)^敲声更沉(1,2)
复合置换:θoλ;逆置换:θ-1
合一:通过置换让两个表达式相等:
A=色泽更深(1,X),θ={2/X,1/Y},Aθ=Bθ=色泽更深(1,2),B=色泽更深(Y,2)
最一般合一置换(MGU):任意一个合一置换都是MGU的复合置换
色泽更深(1,Y),色泽更深(X,Y),θ1={1/X}MGU;θ2={1/X,2/Y};θ3={Z/X,1/Z}
都是θ1与其他置换的复合
一阶归结:当![]() ,
,![]()
一阶逆归结:![]()
比如:
找一个不在归结项C1中的L1使![]() ,令
,令![]()
存在一个解:![]()
使得![]()
四种完备的逆归结操作:
吸收: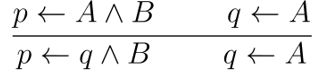 辨识:
辨识: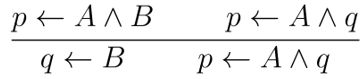
内构: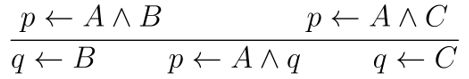 互构:
互构: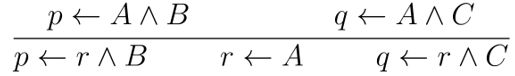
吸收: 辨识:


内构
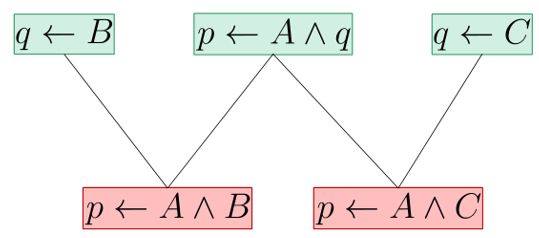

互构:
逆归结中出现的q(M,N)是什么?
q(1,S)←纹理更清(1,S)q(1,T)←敲声更沉(1,T).
日晒更多?更新鲜?更甜?......
之前ILP甚至可以通过谓词发明进行递归规则学习[Muggleton andLin,2013]
 自动发明得到的a(X,Y)即是楼梯的梯级
自动发明得到的a(X,Y)即是楼梯的梯级
目标概念:“楼梯” 
常用工具:
WEKA中的JRIP(http://weka.sourceforge.net/doc.dev/weka/classifiers/rules/JRip.html)
ILP的集大成工具ALEPH(http://www.cs.ox.ac.uk/activities/machlearn/Aleph/aleph.html)
相对最小一般泛化:GOLEM(http://www.doc.ic.ac.uk/~shm/golem.html)
逆演绎:Progol(http://www.doc.ic.ac.uk/~shm/progol.html)
开源Prolog环境:YAP(http://www.dcc.fc.up.pt/~vsc/Yap/)
SWI-Prolog(http://www.swi-prolog.org/)