Unity中的Compute Shader
Unity中的Compute Shader
- 前言
- 一、定义
- 二、创建
- 三、computer代码解析
- 四、c#调用方式
- 五、计算关系
- 六、平台支持
- 七、引用
前言
游戏开发中,dot编程在处理大数量级的运算应用已经越来越广泛了,而GPU本身对大规模数据的并行计算已经越来越强了,因此现在许多游戏处理大量物体的计算可以利用GPU这一特性,加快并发计算速度,Compute Shader就是专门利用这一特性的。
提示:以下是本篇文章正文内容
一、定义
Compute Shader是在GPU上并位于正常渲染管线之外运行的程序。一个Compute Shader是一个着色阶段,完全可用于计算任意信息。虽然它可以进行渲染,但通常用于与绘制三角形和像素没有直接关系的任务。它们可用于大规模并行的 GPGPU(通用图形处理器:General-purpose computing on graphics processing units,简称GPGPU) 算法,或用于加速游戏渲染的某些部分。计算着色器提供内存共享和线程同步功能,允许采用更有效的并行编程方法。
二、创建
在Asset下创建ComputerShader 目录,然后右键Create -> Shader -> Computer Shader

如果创建成功,则生成下面文件:
![]()
打开文件,下面是默认生成的:

三、computer代码解析
类似于常规shader,Compute Shader是项目中的资源文件,文件扩展名为 .compute。它们是以 DirectX 11 样式 HLSL 语言编写的,具有最少数量的 #pragma 编译指令来指示哪些函数将编译为计算着色器内核。
注意:Unity 最初使用 Cg 语言,因此会使用 Unity 某些关键字的名称 (CGPROGRAM) 和文件扩展名 (.cginc)。后续由于一些宏,名字存在冲突,Unity 不再使用CG,但这些名称仍在使用。
#pragma kernel CSMain :声明哪个方法被编译,kernel是内核的意思,这一行即把一个名为CSMain的函数声明为内核,或者称之为核函数。一个Compute Shader中至少要有一个kernel才能够被唤起。可以声明很多方法和内核,类似下面:
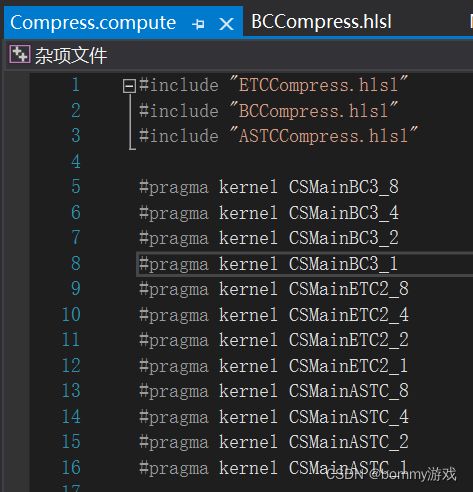
可选择性地在 #pragma kernel 行后面添加要在编译该内核时定义的多个预处理器宏,例如:
# pragma kernel KernelOne SOME_DEFINE DEFINE_WITH_VALUE=1337
# pragma kernel KernelTwo OTHER_DEFINE
···
RWTexture2D中,RW其实是Read和Write的意思,Texture2D就是二维纹理,因此它的意思就是一个可以被Compute Shader读写的二维纹理。一般我们shader通常是只读的,大多使用的是sampler2D,然后通过tex2D函数已经UV坐标访问,但RWTexture2D的访问是直接通过
Result[uint2(0,0)]来访问,值为float4型。
官方文档:RWTexture2D 文档
[numthreads(8,8,1)] 定义了一个线程组(Thread Group)中线程(Thread)总数量,格式:numthreads(tX, tY, tZ),其中tXtYtZ的值即线程的总数量。每个核函数前面我们都需要定义numthreads,否则编译会报错。这里先不细说,后面会详细介绍这个组的概念。
SV_DispatchThreadID一张图片的每个像素坐标
四、c#调用方式
先定义并绑定一个ComputerShader,并定义一个接收的纹理:
private static ComputeShader shader;
private const int TextureSize = 1024;
private RenderTexture tex = RenderTexture.GetTemporary(TextureSize, TextureSize, 0, GraphicsFormat.R32G32B32A32_UInt);
public static void Init()
{
#if !UNITY_EDITOR
shader = AssetBundleManager.Instance.LoadAssetSync("ComputeShader/NewComputeShader.compute");
#else
shader = UnityEditor.AssetDatabase.LoadAssetAtPath("Assets/ComputeShader/NewComputeShader.compute");
#endif
}
运行时调用:
public void Computer(Texture sourceTex, bool isAlpha)
{
if (!SystemInfo.supportsComputeShaders || SystemInfo.copyTextureSupport == CopyTextureSupport.None)
{
return null;
}
int kernelHandle = shader.FindKernel("CSMain");
shader.SetTexture(kernelHandle, "Result", tex, i);
shader.Dispatch(kernelHandle, TextureSize / 8, TextureSize / 8, 1);
}
绑定tex保存结果,在计算玩后,将传回,调用shader.Dispatch生效ComputerShader。
五、计算关系
public void Dispatch(int kernelIndex, int threadGroupsX, int threadGroupsY, int threadGroupsZ);
shader.Dispatch中kernelIndex指定是哪个内核函数,后面的threadGroupsX,threadGroupsY,threadGroupsZ指定了线程组的数量,上面例子中可以看到TextureSize是1024,
threadGroupsX = 1024 / 8,
threadGroupsY = 1024 / 8,
因为一个组也就是[numthreads(8,8,1)],也就是一个组是88个,总纹理大小为10241024,那么组的数量就是(1024 / 8)*(1024 / 8).
核函数:
void KernelFunction(uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID,
uint3 dispatchThreadId : SV_DispatchThreadID,
uint groupIndex : SV_GroupIndex)
{
}
SV_GroupID:这个就非常好理解了,我Dispatch(1024 / 8,1024 / 8,1),也就是定义了一个128 * 128个线程组,SV_GroupID的范围(0, 0, 0) - (128, 128, 0)
SV_GroupIndex:即在每一个线程组元素里,线程的索引,[numthreads(8,8,1)],则索引范围(0, 0, 0) - (8, 8, 0),
SV_DispatchThreadID:这个就是全局唯一的id,可以理解为一张图片的每个像素坐标,算法如下:
假设:
SV_GroupID=(a, b, c)
SV_GroupThreadID=(i, j, k)
numthreads(tX, tY, tZ)
=>
SV_DispatchThreadID=(a * tX + i, b * tY + j, c * tZ + k)
注意的地方,线程组大小并不是随便定义的,比如我有一张64*64的图片,所以我定义dispath(8,8,1),[numthreads(8,8,1)],这是ok的,你会发现我dispath.x*numthread.x是等于64的,也就是图片大小,这样才不会漏掉图片上的像素,但是这也是有限制的并不是无限大,[numthreads(x,x,1)]最大乘积为1024,也就是说最大处理的图片大小就是1024;
考虑到现在大多的纹理都是压缩的,而且大多都是以4 * 4 = 16个像素或者以上组成的block,因此computerShader使用这种线程组的方式同步处理8 * 8个像素,能很好的兼容各种压缩带来的读写速度。
六、平台支持
Unity 中的Compute Shader与 DirectX 11 DirectCompute 技术紧密配合。Compute Shader适用的平台:
- Windows 和 Windows 应用商店,使用 DirectX 11 或 DirectX 12 图形 API 和 Shader Model 5.0 GPU
- macOS 和 iOS,使用 Metal 图形 API
- Android、Linux 和 Windows 平台,Vulkan API
- 现代 OpenGL 平台(Linux 或 Windows 上的 OpenGL 4.3;Android 上的 OpenGL ES 3.1)。请注意,Mac OS X 不支持 OpenGL 4.3
- 现代游戏主机(Sony PS4 和 Microsoft Xbox One)
- 在运行时,可使用 SystemInfo.supportsComputeShaders 来查询是否支持Compute Shader。
七、引用
Unity Compute Shader
OpenGL Compute Shader
更详细推荐:Unity中Compute Shader的基础介绍与使用