Hadoop2
hadoop2概述
hadoop1和hadoop2的结构比较:

hadoop1中有HDFS和MapReduce.HDFS负责存储,MapReduce负责计算,但是有几个问题需要解决:
1.单点的问题.HDFS的namenode和MapReduce的jobTracker都是单点.单点的缺点就是,这个点一旦奔溃了,整个集群就不能工作了,虽然也有解决方案,但是都不够彻底,最好的解决方案,不会有单点,就得有两个或者更多的点在运行的时候就会有一个点发挥主要作用的,其余的点是用来后备的.一旦有问题的话,他们就会切换.hadoop就是为了解决这种问题.
2.hadoop1中我们的hdfs存储海量数据是按照block来存的,block有大有小,在一个集群中只能规定有一种大小,这种用起来就比较别扭,因为企业的数据源不见得一致,有的数据可能大一些,有的数据可能小一些,在我们hadoop1的hdfs中,随着存储的block的增多,那么namenode的内存压力就会增大,当我们namenode内存装不下block的元数据信息的时候,那么我们的集群就不能用了.namenode所在服务器的内存不够用时,那么集群就不能工作了.
3.mapredcuce所在集群的资源利用率比较低,如果只做mapreduce计算的话,会更低.
在hadoop1中也有相应的解决方案,namenode和jobtracker有单点,但是发生风险的概率相当低,但是对应着都有一定的备份方案,所以一般的时候都没有什么问题.买服务器的时候,买高内存的话,一般问题都不大,真出现节点装不小,再搭一个集群也是没有问题的,mapreduce资源利用率低也不是什么大事,不过我们期待它的资源利用率高一点.hadoop2就是针对hadoop1的一个新的解决方案.
hadoop2的结构:

底层依旧是数据存储,那么在上面一层就没有mapreduce了,有了一个新的yarn,yarn是一个资源管理的框架,上边跑的mapreduce不属于hadoop2的平台,只是在yarn上的一个应用而已.
hadoop计算永远是重点,yarn上可以跑mapreduce,也可以跑其他的一些东西,这些东西都是一些应用,这些应用需要利用这些资源.yarn负责集群的资源管理.
hadoop1中mapreduce负责资源管理和数据处理,在hadoop2上,yarn属于资源管理,数据处理归外边的应用,把hadoop1上的功能给分解了,mapreduce 本身就是一个处理的框架,像一个插件插在yarn上,在yarn上可以跑Batch MapReduce,Interactive Tez,Online Hbase ,Steraming Strom、S4,Graph Graph, In-Memory Spark,Hrc Mpi OpenMpi.
yarn只做资源管理,控制着集群上边的cpu,内存,网路,以及硬盘.里边的那些框架要想运行的话,离不开yarn.
程序在运行时还是需要从hdfs上请求数据,主要的是上边的应用来请求数据,不是yarn,yarn只负责资源管理硬件环境的,hdfs上的数据其实是应用来处理的.hdfs上存放的是数据资源,应用和hdfs上的数据有关系.也可以理解为管理硬件资源,分担了一部分jobtracker的功能.
jobtracker负责资源管理和应用的监控,yarn只做上边的资源管理,应用管理是mapreduce做,功能单一了.
Hadoop2 HDFS的HA和Federation:
HA:解决namenode的单点问题.
namenode会区分状态一种active(激活)状态,standby(准备)状态,在我们namenode运行的时候一个属于active,一个属于standby,对外提供服务是active,standby属于时刻准备的namenode,准备着active状态的namenode宕掉,standby状态的接管,因为是两个namenode,有两个访问地址,所以HA这块对外提供了一个统一的名称,用户不需要关心什么是active,什么是standby,只需要访问这个地址就行了,地址会连正确的active,如果对外运行的地址宕了,机器自己会立即切换到另外一台机器上运行.
HA的自动failover
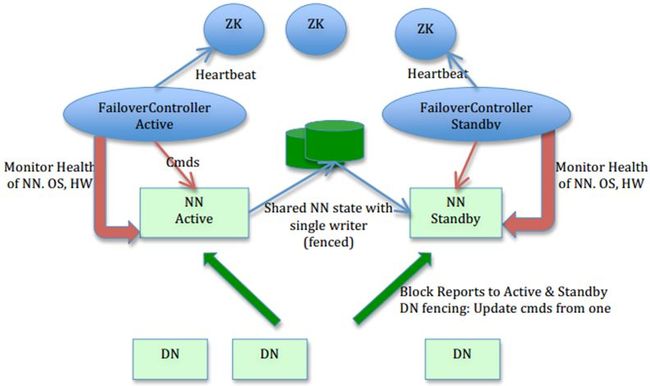
利用共享存储来在两个NN间同步edits信息。
以前的HDFS是share nothing but NN,现在NN又share storage,这样其实是转移了单点故障的位置,但中高端的存储设备内部都有各种RAID以及冗余硬件包括电源以及网卡等,比服务器的可靠性还是略有提高。通过NN内部每次元数据变动后的flush操作,加上NFS的close-to-open,数据的一致性得到了保证。社区现在也试图把元数据存储放到BookKeeper上,以去除对共享存储的依赖,Cloudera也提供了Quorum Journal Manager的实现和代码,这篇中文的blog有详尽分析:基于QJM/Qurom Journal Manager/Paxos的HDFS HA原理及代码分析
DataNode(以下简称DN)同时向两个NN汇报块信息。
这是让Standby NN保持集群最新状态的必需步骤,不赘述。
用于监视和控制NN进程的FailoverController进程
显然,我们不能在NN进程内进行心跳等信息同步,最简单的原因,一次FullGC就可以让NN挂起十几分钟,所以,必须要有一个独立的短小精悍的watchdog来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是用ZooKeeper(以下简称ZK)来做同步锁,但用户可以方便的把这个ZooKeeper FailoverController(以下简称ZKFC)替换为其他的HA方案或leader选举方案。
隔离(Fencing)),防止脑裂),就是保证在任何时候只有一个主NN,包括三个方面:
共享存储fencing,确保只有一个NN可以写入edits。
客户端fencing,确保只有一个NN可以响应客户端的请求。
DataNode fencing,确保只有一个NN可以向DN下发命令,譬如删除块,复制块,等等。
两个namenode之间如何进行数据的同步:
1.依赖于硬件linux操作系统的.NFS,网络连接系统 用来数据共享的.
2.还有一个就是依赖于软件层面的,在hadoop上有一个新的节点,journalnode,软件层面上可以提供一个journalnode的集群,使用这个集群可以为我们的namenode提供数据同步做支持.journalnode会接收active的状态,active一旦有变化,journalnode会收到namenode的变化,然后journalnode集群的其他节点都会接收变化,并且standby端会接收通知同步journalnode上的数据.journalnode就是专门用来同步数据的.为什么集群呢?因为如果有一个journalnode宕了,数据也能真的同步过去.
active的数据是journalnode接收的,这集群之间的节点是要做同步的,然后standby就可以从任意一个journalnode上读数据了.journalnode不能代替以前的secondarynode,secondarynode是进行数据合并的,journalnode是进行一个数据的中转的平台,如果往其中的两个journalnode上写成功了,第三台失败了,在journalnode集群这块应该叫没写成功.
active状态的namenode如果宕了,可以通过两种方式进行切换,手工和自动切换。
手工切换需要人工干预,不好,自动切换必须依赖于外界,这时候又引入zookeeper集群架构.zookeeper集群和journalnode性质有些相似,但是他们做的事是不一样的。
zookeeper集群是用来实现namenode之间状态切换的。所以这个active状态的namenode和standby状态的namenode也会也zookeeper进行通信,zookeeper的目的是当一个宕了的话,别的还活着,他们之间的状态也是 进行实时同步的,实现状态切换一利用zookeeper集群,二利用外部的一些脚本,也就是说当active和standby进程起来的时候回去zookeeper进行注册,注册之后我们的zookeeper就知道有两个namenode来的,其中一个叫active,一个叫standby,如果active状态的一旦宕了,zookeeper就会接到通知.因为zookeeper是和我们的namenode连接在一起的,如果有一个连接宕掉的话,连接就中断了,连接一旦中断,zookeeper就会感知到有一个节点宕了,根据namenode的状态去做操作。zookeeper本身并没有转换的能力,只是用来判断有一个节点宕了,那么另外一个节点应该变过来。节点状态的变换,还需要我们java程序的处理。也就是说框架内部已经内置了状态的切换的这个命令,命令的触发时间是由zookeeper集群下的。
在hadoop2中zookeeper只是管理、监控namenode的状态的变化。如果没有zookeeper集群就只能手工切换
federation:
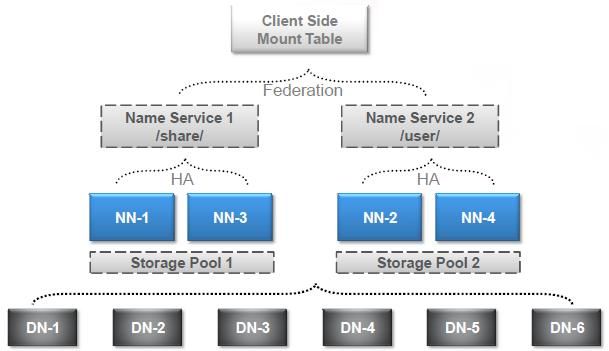
解决问题:如果一个集群的内存不够用时,那么这个集群就不能用了,可以启动多个集群。
新建集群的时候,一个namenode对应5个datanode,再新建一个集群的时候,对应着也是一个namenode对应着5个datanode,这些datanode不能重用,因为datanode节点上跑的是java进程,那么再起java进程的时候就会混淆,假设一个namenode对应这六个datanode,namenode的内存满了,datanode的容量可以是不限制的,上千台都可以,那么再建一个集群的话,一个namenode肯定也对应着这N多的datanode,又浪费了一些机器,其实一些datanode上还没有存满数据呢。
hadoop2的federation的含义是:我可以搭多个集群,数据还是存放在datanode上的,namenode不共享,datanode共享。
namenode内存满了,自身已经都不够了,所以他没法共享。datanode有有十台机器,每个有1T的硬盘,在原的集群中,1T的硬盘差不多快用完了,但是你的服务器不只是能放1T,可以放多台服务器,我可以放多块硬盘,可以扩展到几百个T都没问题,所以硬件机器是可以共用的。这样起码我们的CPU,主板,内存这些资源不需要再次投资了,只需要往上增加硬盘就可以了。
federation是为了解决我们的namenode单节点内存不足,造成我们的集群不能用问题。
datanode的节点利用率也提高了。两套集群其实是两套HDFS了,元数据其实是不一样的,datanode上面放的数据是有标记的,标记数据是属于哪个集群的.一般100万个文件,在namenode这边代表1G的内存。这和两个集群的区别就是datanode共享。
多个namenode有联系吗:
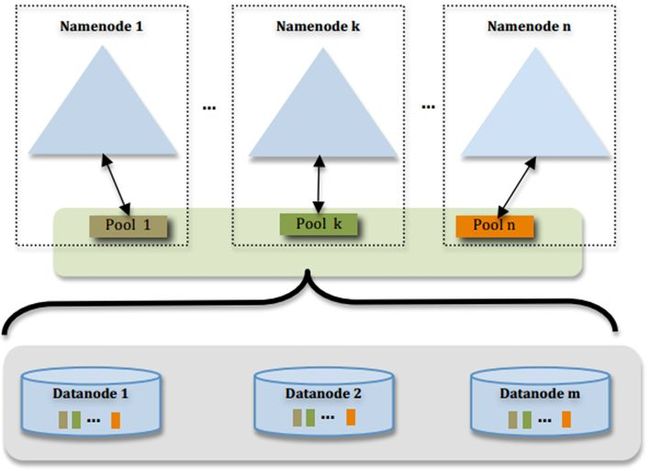
多个NN共用一个集群里DN上的存储资源,每个NN都可以单独对外提供服务
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况
如果需要在客户端方便的访问若干个NN上的资源,可以使用客户端挂载表,把不同的目录映射到不同的NN,但NN上必须存在相应的目录
这样设计的好处大致有:
改动最小,向前兼容 现有的NN无需任何配置改动. 如果现有的客户端只连某台NN的话,代码和配置也无需改动。
分离命名空间管理和块存储管理 提供良好扩展性的同时允许其他文件系统或应用直接使用块存储池 统一的块存储管理保证了资源利用率 可以只通过防火墙配置达到一定的文件访问隔离,而无需使用复杂的Kerberos认证
客户端挂载表 通过路径自动对应NN 使Federation的配置改动对应用透明
federation两个集群多个namenode的联系是:datanode节点是共享的。没有journalnode和zookeeper的事,journalnode和zookeeper是属于HA的范围。
想要访问两个不同的HDFS的时候,因为是两个不同的集群,所以要分开去写。
federation是多个HDFS集群,在多个集群中每一个集群内部可以自己搭建HA环境,多个HA组成一个federation,这个federation可以不是HA,只要保证他们是两个不同的集群就可以了。
federation和两个hadoop集群的区别:是否共享datanode集群。
HA的自动fallover:使用HA之后,可以自动进行状态的切换。
我们的namenode 一个是active,一个是standby,两个namenode之间是共享数据的,我们的zookeeper集群实现了他们之间状态的监管,在运行的过程中,我们应该怎么样让他们的状态不同而进行切换呢?这要通过工具FalloverController,它是用来切换的,所以我们在配置自动切换的时候配置zookeeper集群,还要配置FailloverController。FailloverController是用来监控各个节点的状态的。如果有问题,就会发送通知,根据内部的判断来做出决策。
namenode就是只做HDFS存放元数据的,状态切换或者状态监控不归namenode管,得需要第三方来做,
FailoverController是属于zookeeper的,zookeeper集群是 管理状态的,Namenode启动之后会在zookeeper注册状态。注册之后,节点一旦宕了,zookeeper得知道,但是zookeeper是通过FailoverController来监管他们的,
FailoverController是HDFS里边的一个进程,进程就是用来监控状态的变化的。
active和standby两个namenode数据共享是通过NFS或者是journalnode集群
YARN的结构:
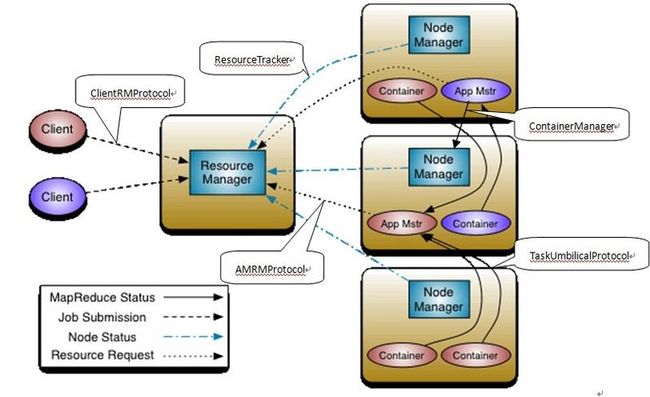
主从式结构,
主节点:ResourceManager ,管理节点的,
从节点:NodeManager,各个执行任务节点上的一个管家,管理资源
客户端是和ResourceManager打交道的,我们把我们的MapReduce程序或者是Storm程序发给ResourceManager,ResourceManager就会把我们的这个程序放到NodeManager去执行,我们的程序要想在NodeManager上执行的话,必须符合yarn平台的规范,也就是说我们的这个程序在MapReduce或者是Storm的程序里必须也是主从式的结构,意味着会有一个主节点叫JobTracker,Jobtracker要符合yarn上边的这个规范,ResourceManager上边的这个规范叫做ApplicationMaster,MapReduce的JobTracekr就承担了ApplicationMaster的这个角色,起来之后再去申请资源。
Client将代码提交上去,在ResourceManager申请资源,就会对应的运行一个这种应用的主节点叫做ApplicationMaster, ApplicationMaster是主节点,要运行额时候需要和ResourceManager申请资源,ResourceManager就会根据机器资源的情况给分配一个Container,ApplicationMaster就会和Container组成一个运行的机制。里边的ApplicationMaster依然是主节点,其他的Continer依然是从节点,对应到MapReduce,ApplicationMaster就是JobTracker,其余Continer就是TaskTracker,只是JobTracker和TaskTracker要在yurn上运行,必须符合yarn上的规范。
yarn是一个统称,是一个平台,上边包括ResourceManager和NodeManager,ResourceManager是单点的,NodeManager有很多点。
ApplicationMaster简单的理解就是随机选的。
ResourceManager和NodeManager分布在不同的节点上。
在yarn上,ResourceManager也是一个单点,如果Resourcemanager挂了,那么集群也就废了。