关于多核系统同步互斥的小研究

在多核系统中,会存在多个CPU核竞争同一资源的情形,这就必须有一些机制来保证在竞争中不会出现错误,即同步互斥机制。这里主要针对同步互斥原语之一的自旋锁进行一点分析和记录。上图为一个多核系统的中断部分,很显然中断部分会存在许多竞争相关问题。
自旋锁(Spinlock)
自旋锁是用来在多处理器环境中工作的一种特殊的锁,用于控制共享资源的访问,是一种同步原语。当一个CPU正访问自旋锁保护的临界区时,临界区将被锁上,其他需要访问此临界区的CPU只能忙等待,即所谓的“自旋”,直到前面的CPU已访问完临界区,将临界区解锁。
一般实现上需要定义spinlock的结构以及加解锁的方式,伴随实际应用中出现的问题,spinlock也不断在改进。
下面来分析下几种Spinlock的实现以及改进方法:
1.A simple spinlock
如下所示,为wikipedia中提供的一种最简单spinlock的x86汇编实现方式。分三个操作:
- 定义全局locked变量的值为0;
- 定义spin_lock操作,给累加器ax赋值为1,交换ax和locked变量的值,然后检测ax的值看是否为零,若为零则继续向下执行ret返回,相当于一个获取锁的过程;若不为零则说明锁已被其他执行过程获得,跳转回spin_lock继续执行,如此就形成了一个循环执行的效果,即称之为“自旋”;
- 定义spin_unlock操作,给累加器ax赋值为0,交换ax与locked的值,然后返回,相当于一个解锁的过程。

figure 1
那么问题来了,不是哪家强,而是对于这种spin_lock的实现,有两点疑问需要想明白:
问题一:为什么这样设计的自旋锁操作能够保证多个执行过程对共享资源互斥地访问,或者说某一时刻只能有一个CPU获得锁?
关键就在于xchg指令。xchg是一个“原子”的交换指令,何谓“原子”?就是不可分割的意思,可以参考我的另一篇博客:Linux中同步互斥机制研究之原子操作。根据Intel手册的描述,xchg指令在执行的时候会将CPU的LOCK位拉高,导致总线被锁住,使得其他的CPU不能使用总线,直到xchg指令执行结束才将LOCK恢复,释放访问权限,通过这种方式保证了在执行xchg指令的时候只能由一个CPU独享总线。知道了这点再去看代码就明白了,当多个CPU均执行到spin_lock时,它们都想获得共享资源的访问权限,执行到xchg指令的时候,总会有一个CPU率先执行xchg指令(宏观上并行,微观上必然还是有先后顺序),我们姑且称为0号CPU,这时总线被锁住,其他CPU只能默默等待这个CPU执行完xchg指令。之后locked变量的值变为1,0号CPU的ax寄存器值变为0,spin_lock操作返回,程序继续执行,于是0号CPU就进入了临界区域,获得了某些共享资源的访问权限。由于locked变量的值为1,其他CPU执行完xchg指令后,ax寄存器的值仍为1,所以只能jump回spin_lock,不能返回,从而保证在某一时刻只能有一个CPU获得锁。
问题二:既然同一时刻只能有一个CPU获取锁,那么谁应该获取锁?
对于这个问题,上述实现方式的答案是:随机!并没有使用任何方式去控制获取锁的先后顺序。这样的设计固然能够保证独占式地获取锁,而且所有的CPU最终都能够获得锁,但是在实际应用中会引出另一个问题。假设CPU C已经获取了锁,还没有释放,这时CPU A尝试获取锁失败,自旋等待,过了好久CPU B也来尝试获取锁,结果仍然失败、自旋等待,此时CPU C释放锁,由于获取锁的随机性,CPU B获取了锁,而CPU A仍然要等待。理论上因为A是先来的,很有可能A执行的任务比B重要,需要先获取锁,结果B后来反而先获取了锁,A需要再等待一段时间才能执行,如果足够倒霉有可能长时间处于自旋等待状态,甚至造成程序的逻辑错误。这就是自旋锁中的“公平性”问题,事实上,没有什么系统使用这种方式实现自旋锁。
2.Ticket spinlock
针对“公平性”问题,很自然的想法就是所有CPU都应遵守一定的秩序,first come first serverd 就是一种不错的策略。依照这种想法就需要保存CPU获取锁的先后顺序,于是就有了Ticket spinlock:
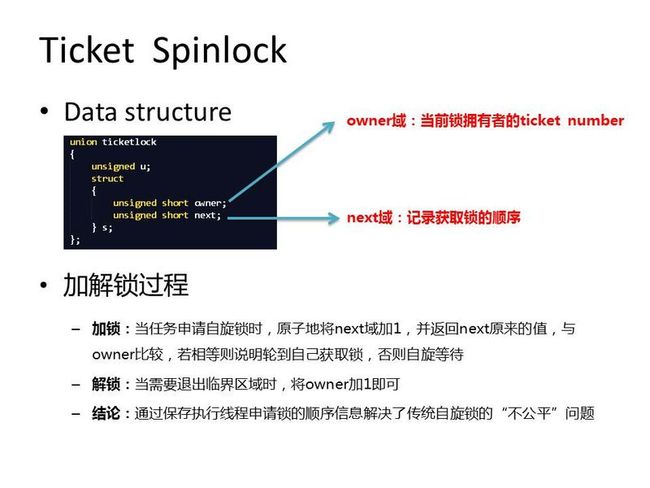
figure 2
具体实现可以参考locklessinc.com中提供的代码,我在这里没有贴全,捡重要的说。在使用ticket lock时,owner和next域都需要初始化为0,第一次获取锁的时候,next域被原子地加一,并返回next原来的值(为0),由于owner的值也为0,所以线程得到锁,返回继续执行,否则就会一直执行cpu_relax。解锁过程也很简单,barrier是内存屏障,保证barrier后的操作不会在barrier之前进行(这个涉及到memory reordering的内容),之后将owner加1,这样顺序上第二到达的线程就会从ticket_lock中返回继续向下执行,对于后面来的线程依此类推。
#define barrier() asm volatile("": : :"memory")
#define cpu_relax() asm volatile("pause\n": : :"memory")
static inline void ticket_lock(ticketlock *t) { unsigned short me = atomic_xadd(&t->s.next, 1); while (t->s.owner!= me) cpu_relax(); } static inline void ticket_unlock(ticketlock *t) { barrier(); t->s.owner++; }
ticket spinlock解决了“公平性”问题,而且实现上也不复杂,所以很多系统中均采用ticket spinlock来控制共享资源的访问,比如Linux和Rtems。然而ticket spinlock也有自身的缺陷,在并发性很高的系统中可能存在问题,下面来看另一种自旋锁。
3.MCS spinlock
MCS spinlock是Mellor-Crummey & Scott 在paper《Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors》中提出的,目的在于解决ticket lock中频繁的缓存不命中问题。在高并发的系统中单纯ticket spinlock可能并不能满足性能上的要求,原因在于使用ticket spinlock时,所有执行线程均会在一个全局的“锁变量”上自旋,造成频繁的缓存不命中现象从而降低系统性能。
我们知道CPU的每个核都有自己的cache,当CPU处理数据时会首先从cache中查找,若cache中没有才去内存中取,所以,如果让每次需要处理的数据尽可能地保存在cache中,就能够大幅提高系统的性能,因为从内存中读的时钟周期至少是从cache中读的几倍甚至几百倍。由于ticket lock使用的是全局锁变量,因此每当锁变量的值被修改后,所有CPU核的缓存将变为无效,而为了保证数据的一致性,又必须进行频繁的缓存同步操作,导致系统性能下降。
MCS Spinlock在使用时,创建的是局部锁变量,每个线程都是在自己的局部锁变量上自旋,避免了频繁修改全局变量而引发的缓存不匹配问题。
 figure 3
figure 3
下面是MCS spinlock的实现,加解锁操作的第一个参数为指向全局锁变量的指针,而第二个参数为指向本地申请的锁变量的指针。在获取锁的操作中由于使用的是局部变量,所以最多只会使得执行当前线程的CPU的cache 失效。
#ifndef _SPINLOCK_MCS #define _SPINLOCK_MCS
#define cmpxchg(P, O, N) __sync_val_compare_and_swap((P), (O), (N))
#define barrier() asm volatile("": : :"memory")
#define cpu_relax() asm volatile("pause\n": : :"memory")
static inline void *xchg_64(void *ptr, void *x) { __asm__ __volatile__("xchgq %0,%1" :"=r" ((unsigned long long) x) :"m" (*(volatile long long *)ptr), "0" ((unsigned long long) x) :"memory"); return x; } typedef struct mcs_lock_t mcs_lock_t; struct mcs_lock_t { mcs_lock_t *next; int spin; }; typedef struct mcs_lock_t *mcs_lock; static inline void lock_mcs(mcs_lock *m, mcs_lock_t *me) { mcs_lock_t *tail; me->next = NULL; me->spin = 0; tail = xchg_64(m, me); /* No one there? */
if (!tail) return; /* Someone there, need to link in */ tail->next = me; /* Make sure we do the above setting of next. */ barrier(); /* Spin on my spin variable */
while (!me->spin) cpu_relax(); return; } static inline void unlock_mcs(mcs_lock *m, mcs_lock_t *me) { /* No successor yet? */
if (!me->next) { /* Try to atomically unlock */
if (cmpxchg(m, me, NULL) == me) return; /* Wait for successor to appear */
while (!me->next) cpu_relax(); } /* Unlock next one */ me->next->spin = 1; } static inline int trylock_mcs(mcs_lock *m, mcs_lock_t *me) { mcs_lock_t *tail; me->next = NULL; me->spin = 0; /* Try to lock */ tail = cmpxchg(m, NULL, &me); /* No one was there - can quickly return */
if (!tail) return 0; return 1; // Busy
} #endif
4.K42 spinlock
K42是IBM的一个开源的研究性操作系统项目,里面提供了另一种Spinlock的实现方式,K42 spinlock在实现上与MCS spinlock类似,这里不再赘述,不同之处在于MCS spinlock使用的是local变量作为是否等待的标志而k42 spinlock中使用的是一个链表结构,这样,就可以避免传递额外的参数。
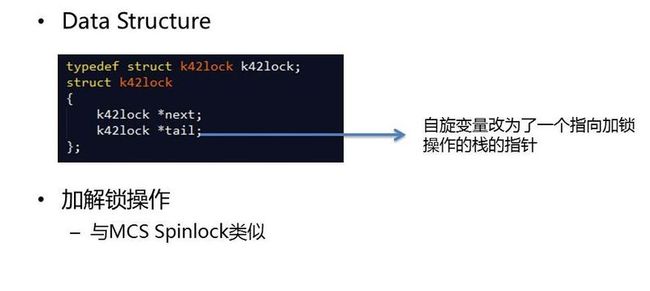
figure 4
实现代码如下:
static inline void k42_lock(k42lock *l) { k42lock me; k42lock *pred, *succ; me.next = NULL; barrier(); pred = xchg_64(&l->tail, &me); if (pred) { me.tail = (void *) 1; barrier(); pred->next = &me; barrier(); while (me.tail) cpu_relax(); } succ = me.next; if (!succ) { barrier(); l->next = NULL; if (cmpxchg(&l->tail, &me, &l->next) != &me) { while (!me.next) cpu_relax(); l->next = me.next; } } else { l->next = succ; } } static inline void k42_unlock(k42lock *l) { k42lock *succ = l->next; barrier(); if (!succ) { if (cmpxchg(&l->tail, &l->next, NULL) == (void *) &l->next) return; while (!l->next) cpu_relax(); succ = l->next; } succ->tail = NULL; } static inline int k42_trylock(k42lock *l) { if (!cmpxchg(&l->tail, NULL, &l->next)) return 0; return 1; // Busy
}
5.性能
博主在自己的虚拟机上对这几种自旋锁进行了简单的性能测试,通过逐渐增加线程数来观察spinlock的加解锁性能,在测试程序中执行16000000对加解锁操作,计算加解锁之间的时间间隔(均以秒为单位)。测试程序分别创建1个、2个、4个线程,逐渐增加线程数来观察spinlock的加解锁性能,对相同的临界代码段分别调用不同类型的自旋锁,执行三次取平均值。如下图所示为测试程序流程:

figure 5
结果如下图所示,在4核的虚拟机上分别以1、2、4线程运行,测试加解锁的时间,右图则是MCS论文中的原图,可以看出楼主的图是其一个子集,趋势基本符合,如果能够搭建NUMA系统进行后续性能测试工作,相信能对这些锁的性能有一个更全面的认知。

figure 6
参考资料
在工作中碰到了许多和同步互斥相关的问题,有很多都只是一知半解,才有了系统学习一下的冲动,遂成本文,后续有空可能还会写两篇关于同步互斥的文章。从网上找到了许多高质量的内容,感谢这些分享,坚信互联网的核心就是 sharing & learning,若有什么不准确的地方,欢迎指正。
[1]. http://locklessinc.com/articles/locks/
[2]. 何登成的技术博客
[3]. K42 github: https://github.com/jimix/k42
[4]. http://en.wikipedia.org/wiki/Spinlock
[5]. http://lwn.net/Articles/267968/