分组统计查询(学习笔记)
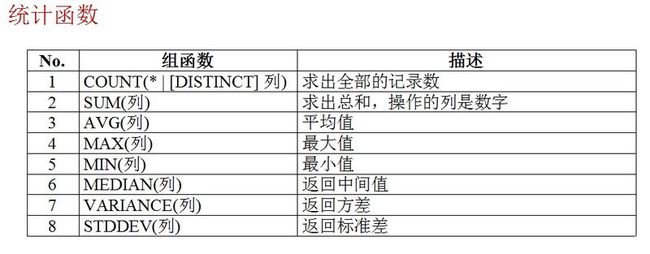
查询出公司每个月支出的工资总和
--查询出公司每个月支出的工资总和
SELECT SUM(sal) FROM emp;
查询出公司的最高工资,最低工资和平均工资
--查询出公司的最高工资,最低工资和平均工资
SELECT MAX(sal),MIN(sal),ROUND(AVG(sal),2) FROM emp;
统计出公司最早雇佣和最晚雇佣的雇佣日期
--统计出公司最早雇佣和最晚雇佣的雇佣日期
SELECT MIN(hiredate) 最早雇佣日期 , MAX(hiredate) 最晚雇佣日期 FROM emp ;
统计公司工资之中中间的工资值
--统计公司工资之中中间的工资值
SELECT MEDIAN(sal) FROM emp ;
验证COUNT(*)、COUNT(字段)、COUNT(DISTINCT 字段)的使用区别
--验证COUNT(*)、COUNT(字段)、COUNT(DISTINCT 字段)的使用区别
SELECT COUNT(*) , COUNT(ename) , COUNT(comm) , COUNT(DISTINCT job) FROM emp ;
分组统计语法
SELECT [DISTINCT] 分组字段 [AS] [列别名] ,... | 统计函数 [AS] [别名] , …. FROM 表名称1 [表别名1] , 表名称2 [表别名2] …. [WHERE 条件(s)]
[GROUP BY 分组字段]
[ORDER BY 排序字段 ASC|DESC] ;
单字段分组统计
统计出每个部门的人数
--统计出每个部门的人数
SELECT COUNT(empno) FROM emp GROUP BY deptno;
统计出每种职位的最低、最高工资
--统计出每种职位的最低、最高工资 SELECT job,MIN(sal) 最低工资,MAX(sal) 最高工资 FROM emp GROUP BY job;
查询出每个部门的名称,部门人数,部门平均工资,平均服务年限
--查询出每个部门的名称,部门人数,部门平均工资,平均服务年限 SELECT d.dname,COUNT(e.empno),ROUND (AVG(e.sal),2),ROUND(AVG (months_between(SYSDATE,e.hiredate)/12),2) FROM emp e,dept d WHERE e.deptno(+)=d.deptno GROUP BY d.dname;
查询出公司各个工资等级雇员的数量、平均工资。
--查询出公司各个工资等级雇员的数量、平均工资。 SELECT s.grade,COUNT(e.empno),ROUND (AVG(e.sal),2) FROM emp e,salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal GROUP BY s.grade;
统计领取佣金与不领取佣金的员工的平均工资,平均入职年限,员工人数
--统计领取佣金与不领取佣金的员工的平均工资,平均入职年限,员工人数--comm是空内容不能直接分组,用集合来完成 SELECT ROUND(AVG(e.sal),2),ROUND(AVG(months_between(SYSDATE,e.hiredate)/12),2),COUNT(e.empno) FROM emp e WHERE e.comm IS NULL UNION SELECT ROUND(AVG(e.sal),2),ROUND(AVG(months_between(SYSDATE,e.hiredate)/12),2),COUNT(e.empno) FROM emp e WHERE e.comm IS NOT NULL;
多字段分组统计
--语法 SELECT [DISTINCT] 分组字段1 [AS] [列别名] , [分组字段2 [AS] [列别名] , …] | 统计函数 [AS] [别名] , …. FROM 表名称1 [表别名1] , 表名称2 [表别名2] …. [WHERE 条件(s)] [GROUP BY 分组字段1 , 分组字段2 , ….] [ORDER BY 排序字段 ASC|DESC] ;
现在要求查询出每个部门的详细信息
--现在要求查询出每个部门的详细信息,部门编号,部门名称,部门位置,部门人数,平均工资,总工资,最高、最低工资 SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal),SUM(sal),MAX(sal),MIN(sal) FROM dept d,emp e WHERE d.deptno=e.deptno(+) GROUP BY d.deptno,d.dname,d.loc;
HAVING子句
使用GROUP BY子句可以实现数据的分组显示,但是在很多时候往往需要对分组之后的数据进行再次的过滤,
而后再通过统计结果进行数据的过滤,而要想实现这样的功能就只能通过HAVING子句完成。
语法:
SELECT [DISTINCT] 分组字段1 [AS] [列别名] , [分组字段2 [AS] [列别名] , …] | 统计函数 [AS] [别名] , …. FROM 表名称1 [表别名1] , 表名称2 [表别名2] …. [WHERE 条件(s)] [GROUP BY 分组字段1 , 分组字段2 , ….] [HAVING 过滤条件(s)] [ORDER BY 排序字段 ASC|DESC] ;
查询出所有平均工资大于2000的职位信息、平均工资、雇员人数
--查询出所有平均工资大于2000的职位信息、平均工资、雇员人数 SELECT e.job,AVG(e.sal),COUNT(e.empno) FROM emp e GROUP BY e.job HAVING AVG(e.sal)>2000;
列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、最高工资。
--列出至少有一个员工的所有部门编号、名称,并统计出这些部门的平均工资、最低工资、最高工资。 SELECT d.deptno,d.dname,AVG(e.sal) avgsal,MIN(e.sal),MAX(e.sal),COUNT(e.empno) 人数 FROM emp e,dept d WHERE e.deptno(+)=d.deptno GROUP BY d.deptno,d.dname HAVING COUNT(e.empno)>0;
显示非销售人员工作名称以及从事同一工作雇员的月工资的总和,
并且要满足从事同一工作的雇员的月工资合计大于$5000,输出结果按月工资的合计升序排列
--显示非销售人员工作名称以及从事同一工作雇员的月工资的总和, --并且要满足从事同一工作的雇员的月工资合计大于$5000,输出结果按月工资的合计升序排列 SELECT e.job,SUM(e.sal) sumsal FROM emp e WHERE e.job<>'SALESMAN' GROUP BY e.job HAVING SUM(e.sal)>5000 ORDER BY sumsal ASC;
HAVING子句是在分组之后使用,主要是为了针对分组的结果进行过滤