DirectX?OpenGL?CUDA?Stream?OpenCL?
如题,这些名词是时下最时髦的东东,特别最后三个,与“大规模并行计算”“GPGPU”联系十分紧密,但是这些IT大佬们随着自己高兴就随便弄一个标准或者SDK,完全不管我们这些码工的死活。弄得我们要天天赶时髦学习这些不知道明天会不会过时的东西,真是“白发三千丈,缘愁似个长”。最近ATi的DX11和Windows7同步上市,声势不可谓不强,各大媒体网站的评测也铺天盖地。在“泡泡网”上看到一篇文章,写的非常好,不敢独享,将其精华摘取留念~
原文地址:http://www.pcpop.com/doc/0/442/442339.shtml
第一章 让游戏运行效率更高!DirectX 11全面解析
HD5800最大的特性就是首次对DirectX 11 API提供完美支持,这套新一代图形引擎将在2009年10月份与Windows 7同时发布,届时也会提供单独的DirectX升级包供Vista安装。因此本文很有必要对DX11的新特性进行全面分析,并与上一代的 DX10/10.1做一些对比。
第一章/第一节 革命性的DirectX 10回顾在过去的十几年时间里,DirectX已经稳步成为微软Windows平台上进行游戏开发首选API。每一代DirectX都带来对新的图形硬件特性的支持,每次版本变更都能帮助游戏开发者们迈出惊人的一步。就拿近几年来说,DX9、DX9C、DX10及相关显卡的发布都带来了令人惊讶的游戏画面,给与玩家无与伦比的游戏体验。尤其是DX10发布后,以Crysis为代表的FPS游戏画面达到了巅峰,显卡实时渲染出来的人物及风景效果足以媲美照片、CG动画甚至是电影,让人叹为观止!
但DX10也不是完美无暇的,其缺陷也很明显,那就是运行效率比较低。当游戏开启DX10模式后,性能下降幅度非常夸张,以至于第一代DX10显卡GeForce 8800和Radeon HD2900都无法在特效全开的情况下流畅运行当时的任何一款DX10游戏!
以两年前发布的DX10代表作Crysis来说,其画面堪称完美,但时至今日依然没有任何一款单核心显卡能在VeryHigh模式下流畅它!即便是顶级的双核心显卡运行起来也很吃力,是因为GPU的发展速度太慢吗?不是的,两年时间显卡的性能已经提高了3-4倍,GPU的发展脚步并没有放缓,问题归根到底还是DX10运行效率较差所致。
下面就先来回顾一下DX10的主要特性:
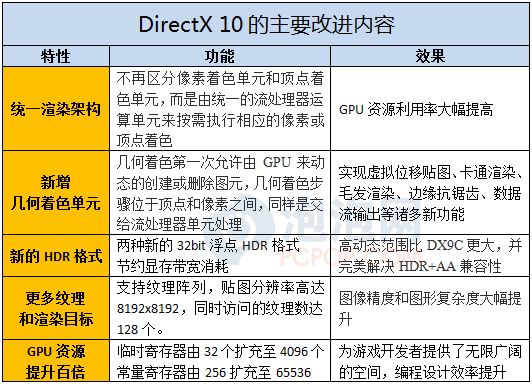
统一渲染架构让GPU运算单元的利用率更高,但新加入的几何着色器却加重了流处理器的负担,超级复杂的画面场景也给流处理器造成了更大的压力。因此在这几年内,纵使GPU的流处理器数量大增2-3倍、频率也稳步提升,但依然不够用。
第一章/第二节 过渡性的DirectX 10.1回顾
DX10带来了众多绚丽无比的新特效,“滥用”各种特效导致GPU不堪重负。而GPU自身的发展受到诸多因素的制约,如果制造工艺跟不上的话运算能力很难取得突破。因此,必须通过不断改进架构运算效率来进一步提升3D图形性能。在DX10之后,微软也开始将重心集中在如何提升算法和效率上面,而不是一味的加入新特效或提高模型复杂度。
此后微软发布了DX10.1 API,对DX10进行了小修小补,DX10.1主要更新内容有:
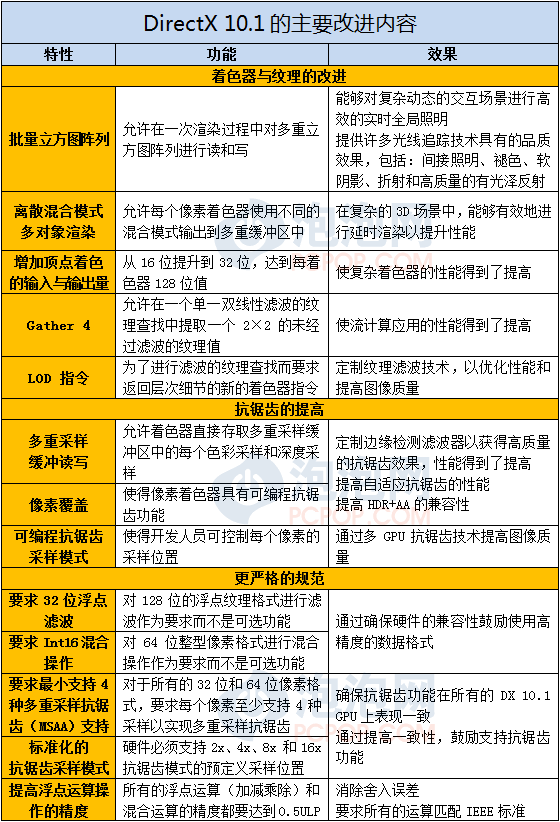
DX10.1的更新内容虽然不少,但相比DX10没有什么革命性的改进,大部分内容都是提高GPU的资源利用率、将一些可选标准列为必须,其实不少项目DX10显卡通过修改驱动就能实现。因此DX10.1没能得到游戏开发商足够多的重视,并没有像当年的DX9C那样迅速成为主流。
ATi从HD3000系列开始,也就是第二代DX10显卡中,就全面提供了对DX10.1 API的支持。而对手nVidia则对于DX10.1比较抵触,第二代GF9系列和第三代GTX200系列都不支持DX10.1,并且宣称“DX10.1并非必须,DX10也能部分实现”之类的言论。《刺客信条》这款原本支持DX10.1的游戏也迫于压力在新版本中取消了支持。但是,nVidia前几天刚刚发布的GT220显卡却非常低调的对DX10.1提供了支持。在DX11时代即将来临之际,nVidia没有将抵制DX10.1的策略进行到底,而选择了妥协,真是令人费解。
至少,nVidia用实际行动证明了,DX10.1虽然改进有限,但也并不是没用。实际上,DX10.1只不过是微软的一个试水石,其目的非常明确,那就是尽可能的提高DX10的渲染效能,达到节约GPU资源的目的,而DX11正是基于这种设计理念而来的。
第一章/第三节 全新的DirectX 11诞生,为高效率游戏而生
从游戏画面逼真度来看,短期内恐怕没有哪款游戏能够达到Crysis的高度,但是这款依靠暴力模型、着色技术和诸多特效堆积而成的游戏,对显卡的要求之高令人叹为观止,至今都没有哪颗GPU敢打包票说能在最高特效下面流畅运行。也就是说Cryengine 3是丝毫没有考虑现有GPU的性能而开发的一款超级引擎。
以高效率著称的虚幻引擎缔造者Tim Sweeney称,想要把现有游戏模型复杂度提高数十倍是很容易的事情(比如CG模型和影视渲染),但同样的你也需要数十倍与现有主机机能的显卡才能流畅运行,比如三路甚至四路顶级系统,而这种系统的市场占有率连1%都不到,独孤求败的Crysis还卖不过快餐式的使命召唤系列、Cryengine至今无法染指游戏机领域就是这个道理。
所以,架空硬件的引擎是不可取的,唯有充分利用有限的GPU资源,通过各种辅助技术最大化画面表现力,才是图形技术公司和游戏开发商首当其冲要解决的内容。
因此,在DX10发布四年、成为主流之后,业界将期望都寄托在了DX11身上,虽然DX11并没有带来全新的特效,但却通过各种手段提升了GPU的渲染效率,当GPU有了富裕的运算资源之后,游戏开发商就可以大胆的去使用更多的特效和技术,如此一来DX11游戏很容易就能从画面到速度全面超越DX10游戏!
DX11最关键的特性有以下五点:
1. Tessellation:镶嵌式细分曲面技术(第三章做专门解析)
2. Multi-Threading:多线程处理
3. DirectCompute 11:计算着色器(第二章做专门解析)
4. ShaderModel 5.0:着色器模型5.0版
5. Texture Compression:纹理压缩
下面笔者就对这些特性进行详细分析,来看看DX11是通过什么手段来提升渲染效率的。
第一章/第四节 Shader Model 5.0
Shader(译为渲染或着色)是一段能够针对3D对象进行操作、并被GPU所执行的程序,ShaderModel的含义就是“优化渲染引擎模式”,我们可以把它理解成是GPU的渲染指令集。历代DirectX每逢重大版本升级时最主要的更新内容就包括在了ShaderModel之中:
ShaderModel 1.0 → DirectX 8.0
ShaderModel 2.0 → DirectX 9.0b
ShaderModel 3.0 → DirectX 9.0c
ShaderModel 4.0 → DirectX 10
ShaderModel 5.0 → DirectX 11
高版本的ShaderModel是一个包括了所有低版本特性的超集,对一些指令集加以扩充改进的同时,还加入了一些新的技术,现在我们就来看看DX11 SM5.0都有哪些新特性:
由于统一渲染架构的特性,Shader Moder 5.0是完全针对流处理器而设定的,所有类型的着色器,如:像素、顶点、几何、计算、Hull和Domaim(位于Tessellator前后)都将从新指令集中获益。
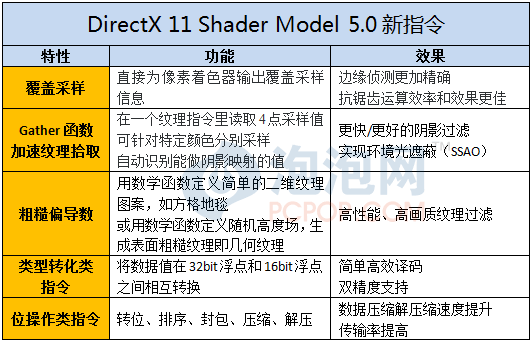
其中,覆盖采样及Gather4纹理拾取两项指令是从在DX10.1基础上发展而来的,SM5.0要比SM4.1更加智能和灵活,它可以针对特定颜色分别采样、还能自动识别可做阴影映射的值,精度和效率都进一步提高。
由于DX10.1与DX10在指令方面的相似性,现有的DX10.1游戏可以很容易的通过更新程序代码升级支持DX11,从而获得更好的运行效率,比如《风起云涌》、《潜行者》、《科林麦克雷》将会率先引入DX11。
第一章/第五节 Multi-threading多线程处理
如果一个软件能够对多核心多线程处理器进行优化的话,那么在使用双核或四核处理器时,其运行效率将会提升2-4倍,遗憾的是如今的游戏都无法支持多核处理。
通过大量的游戏性能测试来看,GPU占绝对主导,而CPU只是考验单核效能,通过对CPU极限超频可以让游戏性能提高不少,但使用四核或者带HT技术的“八核”处理器几乎不会有任何性能提升。在多核成为大势所趋的情况下大量CPU资源被白白浪费,瓶颈可能依然卡在CPU上面。
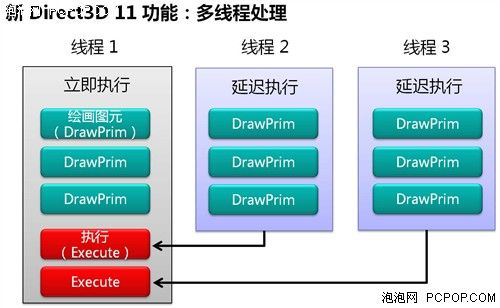
多线程技术的引入对于双卡甚至多卡互联系统更为重要,以往多颗GPU在DirectX中只能模拟成一个虚拟GPU,所有的GPU必须共享指令缓冲区并接受CPU调度,渲染线程的拆分与合并指令延迟都很大,GPU越多则效率越低!而在DX11当中,如果用四核CPU搭配四路交火系统的话,每颗CPU都可以单独控制一颗GPU的渲染线程,在均分CPU负担的同时,提高了GPU资源利用率,从而大幅提升游戏性能。
其实多线程技术也能应用在DX9/DX10甚至是OpenGL上面,但由于API及函数指令的限制,开启多线程会产生很多重复的指令,导致性能提升有限甚至不升反降,因此微软并不建议在旧API模式开启多线程模式,除非程序员做过严格的测试与优化。
第一章/第六节 两种新的纹理压缩格式
丰富的纹理细节对于最终图像的质量尤为重要,目前的游戏也都在朝着超大规模、超精细的纹理细节方向发展。但是,大规模的纹理非常占用显存以及带宽。而纹理 压缩就是为了解决这个问题,将大规模的纹理以一种优化的算法进行压缩。试想,如果图象的纹理都不进行压缩的话,那么2GB的显存容量恐怕都不够用。
但是,目前纹理压缩技术并不支持HDR(高动态范围)图像,这也是开启HDR很占用显存的一个很大的原因。为了解决这个问题,DirectX 11加入了两种新的压缩算法——BC6H和BC7。其中,BC6H是专门针对HDR图像设计的压缩算法,压缩比为6:1;而BC7是专门给高品质 RGB[A]纹理设计的压缩算法,压缩比为3:1。
第二章 DirectCompute:不止是通用计算
此前在测试阶段,微软将DirectX 11中包含的GPU通用计算称为Compute Shader或DirectX Compute,而在近期的正式版本中又改名为Direct Compute,一字(X)之差何必呢?显然,微软为了将GPU通用计算和主要是3D应用的DirectX区别开,进一步凸出Direct Compute的重要性并与OpenCL分庭抗力,由此足以见得微软对GPU通用计算的重视程度。
DirectCompute主要针对GPU计算,但由此可以衍生出一些在图形渲染方面的特殊应用,因此笔者将其单列一章,对一些重要技术进行详细介绍。
第二章/第一节 DirectCompute与Stream/CUDA/OpenCL的关系
提起GPU通用计算,自然会让人想到nVidia的CUDA、ATi的Stream以及开放式的OpenCL标准,再加上微软推出的DirectCompute,四种技术标准令人眼花缭乱,他们之间的竞争与从属关系也比较模糊。
首先我们来明确一下概念:
-
OpenCL类似于OpenGL,是由整个业界共同制定的开放式标准,能够对硬件底层直接进行操作,相对来说比较灵活,也很强大,但开发难度较高;
-
DirectCompute类似于DirectX,是由微软主导的通用计算API,与Windows集成并偏向于消费领域,在易用性和兼容性方面做得更出色一些;
-
CUDA和Stream更像是图形架构或并行计算架构,nVidia和ATi对自己的GPU架构自然最了解,因此会提供相应的驱动、开发包甚至是现成的应用程序,通过半开放的形式授权给程序员使用。

其中ATi最先提出GPGPU的概念,Folding@Home和AVIVO是当年的代表作,但在被AMD收购后GPGPU理念搁浅;此后nVidia后来者居上,首次将CUDA平台推向市场,在这方面投入了很大的精力,四处寻求合作伙伴的支持,并希望CUDA能够成为通用计算的标准开发平台。

nVidia CUDA示意图
在nVidia大力推广CUDA之初,由于OpenCL和DirectCompute标准尚未定型,nVidia不得不自己开发一套SDK来为程序员服务,这套基于C语言的开发平台为半开放式标准,只能用于nVidia自家GPU,因此并未得到业界的认可,AMD认为CUDA是封闭式标准,不会有多少前途,AMD自家的Stream虽然是完全开放的,但由于资源有限,对程序员帮助不大,因此未能得到大量使用。

于是在去年由苹果牵头,以苹果OpenCL草案为基础,联合业界各大企业共同完成了标准制定工作。随后Khronos Group成立相关工作组,工作组的26个成员来自各行各业,且都是各自领域的领导者,具体包括3DLABS、Activision Blizzard、AMD、苹果、ARM、Barco、博通、Codeplay、EA、爱立信、飞思卡尔、HI、IBM、Intel、Imagination、Kestrel Institute、摩托罗拉、Movidia、诺基亚、nVidia、QNX、RapidMind、三星、Seaweed、TAKUMI、德州仪器、瑞典于默奥大学。
OpenCL标准一经成立,IT三巨头Intel、nVidia和AMD都争先恐后的加入支持。AMD由于自家Stream推广不利、支持OpenCL并不意外;Intel即将发布的Larrbee GPU一大卖点就是强大的计算能力,支持OpenCL有百利而无一害;nVidia虽然在大力推广CUDA开发平台,但无奈势单力薄,小有所成但前途未卜,OpenCL虽然与CUDA C语言有交集但并不冲突,是相辅相成的互补关系,nVidia自然也大力支持。
OpenCL组织中唯独微软不在其列,微软有自己的如意算盘。经过多年的发展,DirectX凭借快速更新换代策略、相对轻松的开发与移植方式,在与 OpenGL的交战中已全面占据上风,OpenGL的传统强项——专业绘图领域也在被DirectX不断的蚕食。因此微软打算用相同的策略来对抗尚未站住 根基的OpenCL,于是DirectCompute诞生了。
就如同GPU能同时支持DirectX与OpenGL那样,nVidia和AMD对DirectCompute和OpenCL都提供了无差别支持,真正的GPU通用计算之战,不在CUDA与Stream之间,而是OpenCL与DirectCompute之争,DX11时代才刚刚开始……