常见的并发网络服务程序设计方案
方案一.accept+read/write模式
这种模式其实不是并发服务器,而是iterator服务器,因为它一次只能服务一个客户。同时,这种方案不适合长连接,倒是很适合daytime这种write-only短连接服务.以下是python代码展示的用方案一实现echo server的大致做法
import socket; def handle(client_socket,client_address): while True: data=client_socket.recv(4096) if data data=client_socket.send(data) else print "disconnect",client_address client_socket.close() break if __name__=="__main__": listen_address=("0.0.0.0",2007) server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM) server_socket.bind(listen_address) server_socket.listen(5) while True: (client_socket,client_address)=server_socket.accept() print "got connection from",client_address handle(client_socket,client_address)
方案二.accept+fork模型
这是传统的Unix并发网络编程方案,也称之为child-per-client,俗称process-per-connection.这种方案适合并发连接数不是很大的情况,同时适合"计算响应的工作量远大于fork()的开销"这种情况,比如数据库服务器.适合长连接,不适合短连接。
#!/usr/bin/python from SocketServer import BaseRequestHandler,TcpServer from SocketServer import ForkingTcpServer,ThreadingTcpServer class EchoHandler(BaseRequestHandler): def handle(self): print "got connection from ",self.client_address while True: data=self.request.recv(4096) if data: sent=self.request.send(data) else: print "disconnect",self.client_address self.request.close() break if __name__=="__main__": listen_address=("0.0.0.0",2007) server=ForkingTcpServer(listen_address,EchoHandler) server.server_forever()
ForkingTcpServer会对每个客户端连接新建一个子进程,在子进程中调用EchoHandler.handle(),从而同时服务多个客户端.
方案三.accept+thread模型
这是传统的Java网络编程方案thread-per-connection.这种方案的伸缩性受到线程数的限制,一两百个还行,几千个的话对操作系统的scheduler恐怕是个不小的负担。具体代码与方案二差不多,只不过将进程换成线程。
以上三种方案都是阻塞式网络编程,程序流程(thread of control)通常阻塞在read()上,等待数据到达。但是Tcp是个全双工协议,同时支持read()和write()操作,当一个线程/进程阻塞在read()上,但程序又想给这个TCP连接发送数据,那该怎么办?
接下来的方案是使用IO multiplexing,也就是select/poll/epoll/kqueue这一系列的"多路选择器",让一个thread of control能处理多个连接。"IO 复用"其实复用的不是IO连接,而是复用线程。使用select/poll几乎肯定要配合non-blocking IO,而使用non-blocking IO肯定要使用应用层buffer. 这就是Reactor模式,让event-driven网络编程有章可循。
Reactor模式的主要思想:网络编程中有很多事务性工作,可以提取为公用的框架或库,而用户只需要填上关键的业务逻辑代码,并将回调注册到框架中,就可以实现完整的网络服务。
方案四.单线程reactor模式
单线程Reactor的流程:在没有事件的时候,线程阻塞等待在select/poll/epoll_wait上,事件到达后由网络库处理IO,再把消息通知回调客户端代码。Reactor事件循环的所在线程通常叫做IO线程。通常由网络库负责读写socket,用户代码负责解码、计算、编码。
注意由于只有一个线程,因此事件是顺序处理的,一个线程同时只能做一件事情。如果我们想要延迟计算,那么也不能用sleep()之类的阻塞调用,而应该注册超时回调,以避免阻塞当前IO线程.这种方式适合IO密集的应用,不太适合CPU密集的应用,因为较难发挥多核的威力。
server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM) server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) server_socket.bind(' ',2007) server_socket.listen(5) poll=select.poll() connections={} handlers={} def handle_request(fileno,event): if event & select.POLLIN client_socket=connections[fileno] data=client_socket.recv(4096) if data: handle_input(client_socket,data) else poll.unregister(fileno) client_socket.close() del connections[fileno] del handlers[fileno] def handle_accept(fileno,event): (client_socket,client_address)=server_socket.accpet() print "got connection from",client_address poll.register(client_socket.fileno(),select.POLLIN) connections[client_socket.fileno()]=client_socket handlers[client_socket.fileno()]=handle_request poll.register(server_socket.fileno(),select.POLLIN) handlers[server_socket.fileno()]=handle_accept while True: events=poll.poll(10000) for fileno,event in events: handler=handlers[fileno] handler(fileno,evnet)
与前面不同的是,事件的处理通过handler转发到各个函数中,不再集中在一团。
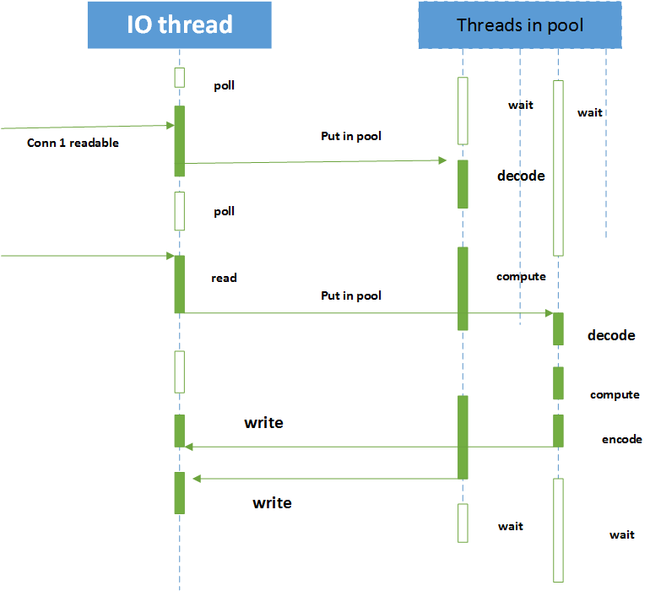
方案五.reactor+thread pool
在收到客户端请求之后,不在Reactor线程计算,而是我们使用固定大小线程池,全部的IO工作都在一个Reactor线程完成,而计算任务交给thread pool.如果计算任务彼此独立,而且IO的压力不大,那么这种方案非常适用.
但是如果IO的压力比较大,一个Reactor处理不过来,我们可以采用多个Reactor来分担负载.
方案六.reactors in threads
这是Netty内置的多线程方案,这种方案的特点是one loop per thread,有一个main Reactor负责accept连接,然后把连接挂在某个sub Reactor中,这样该连接的所有操作都在那个sub Reactor所处的线程中完成.多个连接可能被分派到多个线程中,以充分利用CPU.
在把多个连接分散到多个Reactor线程之后,小规模计算可以在当前IO线程完成并发回结果,从而降低响应的延迟。
c++多线程服务器端编程模式为:one loop per thread + thread pool
event loop用作non-blocking IO 和定时器
thread pool用来做计算,具体可以是任务队列或生产者消费者队列.
实用的方案
| 方案 | 名称 | 接受新连接 | 网络IO | 计算任务 |
| 1 | thread-per-connection | 1个线程 | N线程 | 在网络线程进行 |
| 2 | 单线程Reactor | 1个线程 | 在连接线程中进行 | 在连接线程中进行 |
| 3 | Reactor+ 线程池 | 1个线程 | 在连接线程进行 | C2线程 |
| 4 | one loop per thread | 1个线程 | C1线程 | 在网络线程进行 |
| 5 | one loop per thread +thread pool | 1个线程 | C1线程 | C2线程 |
N表示并发连接数目,C1和C2是与连接数无关,与CPU数目有关的常数。
参考:
《Linux多线程服务器端编程》