关于tcc、tlink的编译链接机制的研究
1、学习过程
在c:\下建立文件夹c,并将编译器tcc.exe、连接器tlink.exe、相关文件c0s.obj、cs.lib、emu.lib、maths.lib放入文件夹中。
要搭建一个简单的C语言编译环境,需要TC2.0、c0s.obj、emu.lib、maths.lib、graphics.lib、cs.lib文件。而这里用编译器tcc.exe、连接器tlink.exe代替了TC2.0,而且相关文件也少了graphics.lib,为什么这样也可以呢?我们先尝试在新建立的环境下编译连接一个文件:
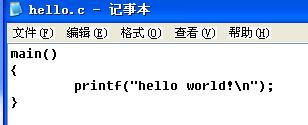
用命令“tcc hello.c”编译连接生成文件hello.obj和hello.exe:

运行结果为:
在编译连接过程中,第一次我用tcc hello.c编译,发现只生成了hello.obj文件,然后我又用tlink hello.obj连接生成hello.exe文件,结果发现运行这个exe文件会出错。经过检查后发现,我把相关文件里的maths.lib错误地复制成了mathl.lib,可能在连接文件时发生了错误,导致exe文件出错。
那么这个环境与之前的环境相比,少了TC2.0、graphics.lib,多了tcc.exe、tlink.exe。在网上查阅资料发现graphics.lib是一个c语言图形库,TC2.0连接需要这个而tcc.exe不需要,我们可以理解为tc2.0在tcc.exe的基础上多了这么一个扩展,每一个库文件都相当于一个小模块,支持一种扩展。我们需要的时候,只需要添加相应的库文件就行了。
从功能上来看,tcc.exe只能从cmd编译当前目录下已存在的文件,而TC2.0则支持文件的创建、修改、保存、编译、连接,是集成了tcc.exe和tlink.exe的一个c语言小型开发平台。
那么既然新建立的环境将所需要的相关文件减少到了4个,那么是不是还可以减少呢?经过实验,我发现不论去掉哪一种相关文件,在编译时都会出错,生成一个错误的hello.obj文件,并且cmd会有相似的提示:
所以我们可以断定,在该环境下,4个相关文件必须都在才能保证编译的成功。
补充研究:在网上查询资料发现,TC2.0是一个集成的开发环境,它集成了以下文件:
INSTALL.EXE 安装程序文件
TC.EXE 集成编译
TCINST.EXE 集成开发环境的配置设置程序
TCHELP.TCH 帮助文件
THELP.COM 读取
TCHELP.TCH的驻留程序
README 关于Turbo C的信息文件
TCCONFIG.EXE 配置文件转换程序
MAKE.EXE 项目管理工具
TCC.EXE 命令行编译
TLINK.EXE Turbo C系列连接器
TLIB.EXE Turbo C系列库管理工具
C0?.OBJ 不同模式启动代码
C?.LIB 不同模式运行库
GRAPHICS.LIB 图形库
EMU.LIB 8087仿真库
FP87.LIB 8087库
*.H Turbo C头文件
*.BGI 不同显示器图形驱动程序
*.C Turbo C例行程序(源文件)
其中: 上面的?分别为:
T Tiny(微型模式)
S Small(小模式)
C Compact(紧凑模式)
M Medium(中型模式)
L Large(大模式)
H Huge(巨大模式)
这个在TC的安装文件夹里其实也可以看出来:
但是我们之前的研究发现只需要需要TC2.0就可以成功编译文件,而不需要tcc.exe也在目录下,所以TC2.0是把tcc.exe集成在自己的文件内部的,而不是对外部的编译器进行调用。
查看tcc.exe的功能:
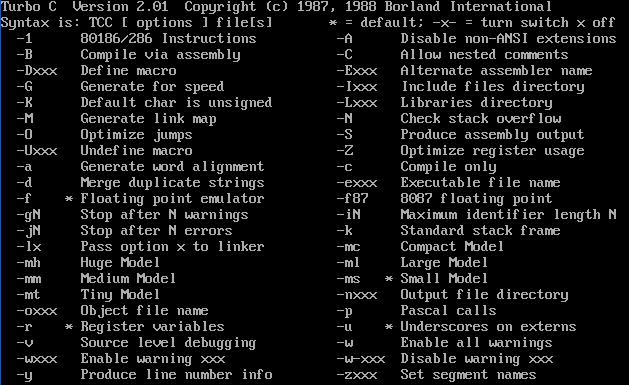
可以看到tcc的命令格式是:tcc [选项] [文件名]
缺少正确的相关文件会对编译造成怎样的影响呢?我先用完整的相关文件进行编译,生成的exe文件有8kb,而删去cs.lib后进行编译,发现生成的exe文件只有536字节,比正确的文件要小得多,所以我认为在用tlink进行连接时因为相关文件的缺失导致有很大一部分相关文件都没有连接进来。
在网上查阅资料发现启动代码有T Tiny(微型模式) 、S Small(小模式)、C Compact(紧凑模式) 、M Medium(中型模式) 、L Large(大模式) 、H Huge(巨大模式),那么分别对应的相关文件应该为:c0t.obj,ct.lib,c0s.obj,cs.lib...果然,我们在TC2.0的lib库里发现了相关文件;
我发现,其他的模式都有对应的c0*.obj和c*.lib文件,而微型模式只有c0t.obj文件,这是为什么呢?是该模式的编译特性决定他们只要用一个文件吗?我们来试试是否可以编译成功,将c0t.obj拷贝到c:\c文件夹下,再用tcc -mt hello.c编译,发现可以编译连接成功,生成的exe文件也能成功运行,所以微型模式的编译是不需要特定的lib文件,这说明微型模式在编译时不需要向文件里面加入专门的库函数。
要实现打印出子函数的段地址和偏移地址,首先要知道,子函数的段地址和偏移地址放在哪里。我们在《20140426_综合研究2研究报告》中发现:(1)函数的名字就代表它的偏移地址。(2)函数的调用在汇编里是采用call-ret方法实现的。另外我们知道汇编中存储当前段地址的寄存器为CS寄存器。
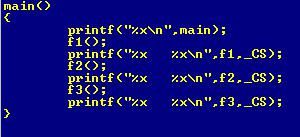
首先填充main函数,分别打印每一个函数的偏移地址,以及运行函数后CS寄存器的值:
显示结果为:
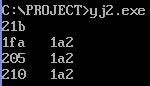
发现main函数的偏移地址为21b,f1的偏移地址为1fa,f2的偏移地址为205,f3的偏移地址为210,cs寄存器的一直为1a2.那么CS里的值真的是子函数的段地址的值吗?我们用debug加载程序:
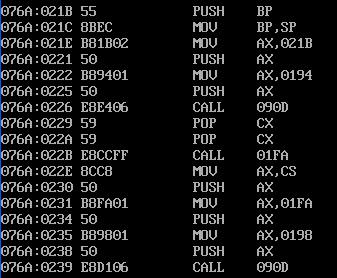
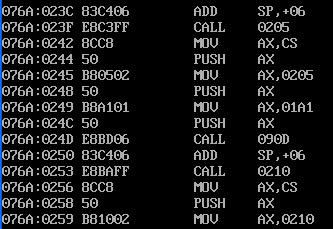
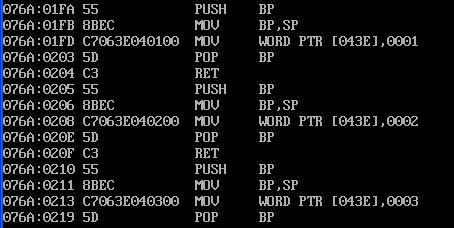
发现main()、f1()、f2()、f3()的偏移地址是对的。但是段地址应为076a而不是打印出来的CS寄存器的值1a2。
如果用长整形将main函数和f1的值全部打印出来:
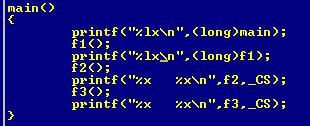

则段地址还是1a2。但是用debug查看并不一样。那么问题在哪里呢?
在网上查看,发现有一个相似问题的解释是这样的:“调试的情况下 是用调试器来实对 单步 断点异常的处理。加载了更多的函数。 当然地址会不一样了。”
我觉得可能是直接运行和debug调试分配的内存空间不一样,如上所说,debug调试要加载更多的函数,所以main函数的段地址会相对较大。
但是这里是子函数和main函数在一个段里,所以子函数的段地址可以在主函数里用_CS
表示,如果子函数和main函数不在一个段里呢?我们知道:用tcc hello.c生成的文件可有两个段,一个为代码段,一个为栈和数据段。所以子函数和主函数都要在同一个代码段里。那么如果代码量超过64kb,一个段存放不下,怎么办?在网上查阅资料如下:
C 语言中提供了6种编译模式,这6种模式是:
微模式(Tiny),小模式(Small),中模式(Medium),紧凑模式(Compact),大模式(Large)和巨模式(Huge)。它们之间的关系如下图所示。用户可以按照自己的程序大小及需要进行选择。
│ 小程序 │ 大程序
━━━━┿━━━━━━┿━━━━━━━━
小数据 │ 微,小 │ 中
大数据 │ 紧凑 │ 大,巨
所谓小程序就是指程序只有一个程序段,大小不超过64KB,缺省的码(函数)指针是near(近程指针)。所谓大程序就是指程序只有多个程序段,每个程序段不超过64KB,但总程序量可超过64KB,缺省的码指针是far(远程指针)。小数据就是指数据只有一个数据段,缺省的数据指针是near。大数据就是指数据有多个数据段,缺省的数据指针是far。
由上可知,我们所说的只有一个代码段的程序是小程序,它的代码不超过64kb,在编译时会以默认的编译模式:小模式来编译。即前面研究里所说的tcc a.c生成的exe文件有一个代码段,一个栈和数据段就可以理解了。我们用TC2.0的时候不可缺少的相关文件里有关编译模式的是c0s.obj和cs.lib,所以TC2.0默认的编译模式是小模式。所以默认的编译只能编译代码量不超过64kb的文件。
关于不同模式的区别,查询资料如下:
C语言编译模式—微模式(Tiny)
在微模式下程序中的数据及代码均放在同一段内,即它们不超过 64KB。在微模式下代码段、堆栈段和数据段的段地址均相同,即CS=DS=SS=ES。在微模式下,数据指针都是 near,一般小程序可采用此编译模式进行编译。还可用 DOS 中的 EXE2BIN 转换程序将.EXE 程序转换成.COM 程序。代码段、数据段和堆栈段均在同一段内,对它们进行寻址时,均以同一地址偏移的参考点,具有这种特点的段又称为属于同一组段(DGROUP),栈是向上生长的,即每压栈一次,栈指针SP减2,即向地址减少的方向移动,它开始的初始值指向栈底,即0xffff(64KB)。堆是向下生长的,即向增加地址的方向改变。堆和栈地址相向生长,当两者未相遇时,便出现了自由空间。一般程序均是这种状态,当占用栈地址较多时,两者可能重合并覆盖部分堆空间。
C语言编译模式—小模式(Small)
在小模式下,程序中的代码放在64KB的代码段内,数据放在64KB的数据段内。在小模式下,栈段、附加数据段和数据段均指向同一地址,它们合三为一,即DS=SS=ES,指针都是near,一般程序均采用小模式编译。在小模式下,内存分配如下图所示。从图中可以看出数据段、堆栈段和附加段为同一段组,即它们的偏移地址均以同一段地址为参考点。
C语言编译模式—中模式(Medium)
在中模式下,所有数据放在64KB的数据段内,因而数据段内使用near,代码量可以大于64KB(允许达到1MB),因而可以在不同的代码段内,代码段使用(far远程指针)。这种编译模式适用于大代码量、小数据量的大程序。中模式下的内存分配如下图所示。
C语言编译模式—紧凑模式(Compact)
在紧凑模式下,数据量超过64KB时,可放在多个数据段中,数据段内的指针是(far)。代码量不超过64KB时,可在一个段内,因而代码段内指针为近程的(near)。但在该模式下,静态数据仍不能超过64KB,堆用far指针来存取。紧凑模式下的内存结构如下图所示。
C语言编译模式—大模式(Large)
大模式下,代码及数据均采用far指针,且都可达到1MB。静态数据仍跟紧凑模式一样,不能超过64KB。大模式下的内存结构如下图所示。
C语言编译模式—巨模式(Huge)
巨模式下,代码段及数据段均用far指针,代码分布在不同的代码段内,数据也分布在不同的数据段内,它们来自不同的源程序,大堆栈只有一个。而且静态数据大小允许超过64KB。巨模式下的内存结构如下图所示。
即不同模式的区别在于可编译的代码量和数据量不一样。那么在编译的时候对于超过64kb的文件该如何选择编译模式呢?
无论采用哪一种编译模式,C 源程序编译生成的代码和数据量都不能超过64KB,对于超过的源程序,可以视代码或数据多少将其分解成两个或多个程序分别编译。大代码量程序要选用大代码编译模式(中模式、大模式和巨模式),大数据量程序应选用大数据编译模式(紧凑模式、大模式和巨模式),这样编译生成的.obj 文件将会带给连接程序信息,将代码和数据安排在不同段内。这样生成的.exe 文件在加载时将告诉 DOS 该程序应如何装入代码段和数据段,如何初始化寄存器。这样,就可确定在不同编译模式下开辟数据区的大小,即大于64KB,或不超过64KB。
2、解决的问题
(1)TC2.0集成了tcc.exe、tlink.exe,并且包含了更多的功能。而tcc.exe、tlink.exe、c0s.obj、cs.lib、emu.lib、maths.lib是编译c文件必不可少的文件。
(2)怎么打印所有函数的段地址和偏移地址?
答:可以用printf(“%lx”,(long)函数名);来打印,这样段地址和偏移地址是连在一起的,也可以用printf(“%x %x”,_CS,函数名);来打印,这样段地址和偏移地址是分开的。
(3)为什么输出的段地址和debug调试的段地址不一样?
答:debug调试要加载更多的函数,所以main函数的段地址会相对较大。
(4)用tcc hello.c生成的文件可有两个段,一个为代码段,一个为栈和数据段。所以子函数和主函数都要在同一个代码段里。那么如果代码量超过64kb,一个段存放不下,怎么办?
答:那应该使用别的内存编译模式,TC下默认的模式是小模式,只支持64kb以下的代码和数据,若代码和数据超过64kb,可以使用大模式或者巨模式。
3、研讨会解决的问题
(1)如果缺少相关文件,tcc.exe会调用tlink.exe吗?生成的obj文件是含有其他相关文件吗?
答:根据讨论,如果缺少相关文件,tcc.exe调用了tlink.exe但是无法找到文件,需要再用tlink.exe来连接obj文件,生成exe文件。如果缺少相关文件,tlink会连接其他相关文件。经过实验,如果缺少maths.lib,程序能够输出helloworld,而如果缺少c0s.obj或者cs.lib编译成的exe文件就会运行出错,这是因为maths.lib是运算相关的库,如果程序里没有运算的话,即使缺少也不影响程序的执行,而c0s.obj或者cs.lib是程序启动运行所需要的文件,所以一旦缺少就会出错。
修改:经过再次的实验,我发现缺少maths.lib文件,编译连接生成的exe文件也会显示出错,这说明之前的结论是不成立的。tcc.exe的功能是把c源文件编译成二进制obj文件,再调用tlink.exe进行连接生成exe文件。即只要执行一条命令就能把c源文件编译连接成可执行的exe文件。我们没有改变tcc.exe文件的内容,那么tcc还是会调用tlink,只是因为相关文件不全而出错导致tlink没有正确执行连接而已。实验发现先用tcc -c hello.c或者tcc -linclude hello.c将源文件编译成obj文件,再连接成exe文件还是执行出错,在网上有资料说这样编译连接会导致返回错误,但没有说明具体原因。我觉得可能单独用tlink连接hello.obj会在调用相关文件上出错,就是说tlink没有调用相关文件的能力,只是tcc调用它的时候告诉它应该按什么顺序来连接,它才能正常连接。但是这个猜想和上面的问题一样,我暂时还找不到方法和资料来验证,希望学长能在衍生课上讲一讲,具体的问题是这样的:
如果缺少相关文件,生成的obj文件是含有其他相关文件吗?为什么一定要tcc.exe调用tlink.exe才能生成正确的可执行文件?
(2)为何在原来的平台上即使没有tcc和tlink也能够编译链接成功。
答:TC2.0集成有多种编译器,c语言和汇编语言是可以混合编译的。如果出现汇编语言,那么TC2.0就会调用tcc.exe来进行编译。Turbo c包有两种编译器,集成开发环境下的叫做TC.EXE和命令行方式的叫做TCC.EXE. 集成开发环境包括:集成编辑器、命令行编译器、连接器、调试器。
(3)库文件是怎么搜索的?
答:在turboc.CFG中可以指定tcc可以用来搜索的库文件的位置。但是用TC2.0修改路径不会保存在turboc.CFG中,而是生成另一个配置文件。
(4)三种模式,是否可以互相的替换
答:其实c语言编译有6种模式,这6种模式编译的结果都是一样的,只是支持的数据大小和程序大小不一样。
(5)为何打印出来的段地址的值和用debug调试的时候出来的地址的值是不一样的?
答:编译时给定了偏移地址,载入时cmd或者debug再给定段地址,所以段地址不一样。
(6)假如代码量超过了64K后,会如何?
答:那么就不能用默认的内存编译模式(小模式)来编译,会出错。应该用支持大程序的模式来编译(如中模式、大模式、巨模式)。编译器会把代码分成几个不超过64kb的程序来编译。
(7)为什么打印出来的偏移地址改变,在平常的时候main函数的偏移地址是1fa但是此时的main函数的偏移地址不是这样的了?
答:主函数的偏移地址不一定是1fa,而是第一个程序的偏移地址是1fa。之后函数的偏移地址按程序的长度发生变化。其实原理和汇编语言里不同段的地址不同是一样的。C0s.Obj里的函数加载完后正好到了1fa处应该加载源文件的内容了,这时那个函数在第一个就把哪个函数放在1fa处。
(8)如何用一条语句打印出段地址和偏移地址。
答:可以用printf(“%lx”,main);打印出段地址和偏移地址。
4、学习感想
其实TC2.0也是别人写的方便开发者使用的一个程序。它是调用了tcc.exe、tlink.exe和一些库文件来实现程序的编译连接,而更高级的开发工具只是编写的功能更全、调用的文件更多、采用更高级的编译器和连接器而已。它们都是由这一个小小的tcc.exe衍生开的。庞大的、复杂的事物,其实可能起核心作用的就是那么一点点东西而已。
这一个研究涉及到很多前面研究的知识,特别是汇编。所以掌握了汇编语言为我们学习C语言打下了良好的基础。