SpringBoot教程(十五) | SpringBoot集成RabbitMq(消息丢失、消息重复、消息顺序、消息顺序)
SpringBoot教程(十五) | SpringBoot集成RabbitMq(消息丢失、消息重复、消息顺序、消息顺序)
- RabbitMQ常见问题解决方案
-
- 问题一:消息丢失的解决方案
-
- (1)生成者丢失消息
-
- 丢失的情景
- 解决方案1:发送方确认机制(推荐,最常用)
- 解决方案2:事务(不推荐,因为性能差)
- (2)MQ丢失消息
-
- 丢失的情景
- 解决方案:开启RabbitMQ的持久化+开启镜像队列
- (3)消费者丢失消息
-
- 丢失的情景 1
- 解决方案:无需解决
- 丢失的情景 2
- 扩展:重试机制
- 解决方案:消费者方确认机制(推荐,最常用)
- 问题二:消息重复的解决方案
-
- 什么时候会重复消费
- 如何解决
- 问题三:保证消息顺序的解决方案
-
- 单一队列和单一消费者模式(RabbitMQ)
- 问题四:消息堆积的解决方案
-
- 消息堆积原因
- 预防措施
- 已出事故的解决措施
RabbitMQ常见问题解决方案
问题一:消息丢失的解决方案
首先明确一条消息的传送流程:生产者->MQ->消费者
所以这三个节点都可能丢失数据
(1)生成者丢失消息
丢失的情景
发送消息过程中出现网络问题:生产者以为发送成功,但RabbitMQ server没有收到
解决方案1:发送方确认机制(推荐,最常用)
发送方确认机制最大的好处在于它是异步的,等信道返回ark确认的同时继续发送下一条消息(不会堵塞其他消息的发送)
(一)修改application.properties配置
# 确认消息已发送到交换机(Exchange)
spring.rabbitmq.publisher-confirms=true #旧版本
spring.rabbitmq.publisher-confirm-type=correlated #新版本
# 确认消息已发送到队列(Queue)
spring.rabbitmq.publisher-returns=true
springBoot 2.2.0.RELEASE版本之前 是使用 spring.rabbitmq.publisher-confirms=true
在2.2.0及之后 使用spring.rabbitmq.publisher-confirm-type=correlated 属性配置代替
(二)新建配置文件RabbitTemplate
对于 发送确认 写法有多种方式,以下的是其中的一种方式
import org.springframework.amqp.rabbit.connection.ConnectionFactory;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitTemplateConfig {
@Bean
public RabbitTemplate createRabbitTemplate(ConnectionFactory connectionFactory){
RabbitTemplate rabbitTemplate = new RabbitTemplate();
rabbitTemplate.setConnectionFactory(connectionFactory);
//setMandatory设置表示:消息在没有被队列接收时是否应该被退回给生产者(true:退回;false:丢弃)。
//通常与yml配置文件中的publisher-returns配合一起使用,若不配置该项,setReutrnCallback将不会有消息返回
rabbitTemplate.setMandatory(true);
//帮助生产者判断 确认消息是否成功发送到RabbitMQ
//ack 为true表示已发送成功 false表示发送失败
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
System.out.println("ConfirmCallback: "+"相关数据:"+correlationData);
System.out.println("ConfirmCallback: "+"确认情况:"+ack);
System.out.println("ConfirmCallback: "+"原因:"+cause);
});
//当消息无法 放到队列里面时 返回的提醒
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
System.out.println("ReturnCallback: "+"消息:"+message);
System.out.println("ReturnCallback: "+"回应码:"+replyCode);
System.out.println("ReturnCallback: "+"回应信息:"+replyText);
System.out.println("ReturnCallback: "+"交换机:"+exchange);
System.out.println("ReturnCallback: "+"路由键:"+routingKey);
});
return rabbitTemplate;
}
}
解决方案2:事务(不推荐,因为性能差)
RabbitMQ提供的事务功能,在生产者发送数据之前开启RabbitMQ事务
(2)MQ丢失消息
丢失的情景
RabbitMQ服务端接收到消息后由于服务器宕机或重启等原因(消息默认存在内存中)导致消息丢失;
解决方案:开启RabbitMQ的持久化+开启镜像队列
RabbitMQ的持久化分为三个部分:交换器的持久化、队列的持久化、消息的持久化
三者 都 持久化 才能保证 RabbitMQ服务重启之后,消息才能存在且能发出去
交换机持久化
交换机持久化描述的是当这个交换机上没有注册队列时,这个交换机是否删除。
如果要打开持久化的话也很简单 (上面列子都是有体现的)
//定义直接交换机
@Bean
public DirectExchange directExchange() {
//第一个参数:定义交换机的名称,第二个参数:是否持久化,第三个参数:是否自动删除
return new DirectExchange("directExchange", true, false);
}
队列持久化
队列持久化描述的是当这个队列没有消费者在监听时,是否进行删除。
持久化做法:
//定义队列
@Bean
public Queue directQueue() {
//第一个参数:队列的名称,第二个参数:是否持久化
return new Queue("directQueue", true);
}
消息持久化
关键配置 持久化(MessageDeliveryMode.PERSISTENT)
@Test
public void testDurableMessage() {
// 1.准备消息
Message message = MessageBuilder.withBody("hello, rabbitmq".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
.build();
// 2.消息ID,封装到CorrelationData中
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
// 3.发送消息
rabbitTemplate.convertAndSend("simple.queue", message, correlationData);
log.info("发送消息成功");
}
(3)消费者丢失消息
丢失的情景 1
RabbitMQ服务端向消费者发送完消息之后,网络断了,消息并没有到达消费者
解决方案:无需解决
无需解决。因为此情景下服务端收不到确认消息,会再次发送的。
丢失的情景 2
启用了重试机制,重试指定次数之后,还没成功,但消息被确认。
扩展:重试机制
重试机制的三大前提
- 重试模式已启用:通过配置 spring.rabbitmq.listener.simple.retry.enabled=true 来启用重试模式。
- 抛出了异常:在 @RabbitListener 标注的方法中抛出了异常,通常是 RuntimeException 或 Error。
Spring AMQP 会捕获这些异常并根据配置的重试策略来重试消息。- 未达到最大重试次数:消息的重试次数尚未达到配置的最大值(spring.rabbitmq.listener.simple.retry.maxAttempts)。
配置以下即可实现重试操作
# 是否支持重试
spring.rabbitmq.listener.simple.retry.enabled=true
# 重试次数(默认3次)
spring.rabbitmq.listener.simple.retry.max-attempts=5
解决方案:消费者方确认机制(推荐,最常用)
改成手动后就 可以实现 “先操作业务逻辑(数据库操作)后,再手动从队列上删除这个消息” 的动作
其中“从队列上删除这个消息“这个动作体现就是 使用 channel.basicAck 去完成的。
切记改成手动后,这个channel.basicAck方法一定要写。
(一)修改application.properties配置
# 设置消费端手动 ack
spring.rabbitmq.listener.simple.acknowledge-mode=manual
(二)修改Service接收信息项
当消息在进入 emailProcess、smsProcess(被@RabbitListener注解) 方法时就已经被视为“接收到了”,但是需要 你 执行 channel.basicAck(手动确认)才能让这个消息从队列上删除。
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitHandler;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Service;
import java.io.IOException;
@Service
public class DirectReceiver {
@RabbitHandler
@RabbitListener(queues = "emailQueue") //监听的队列名称
public void emailProcess(Channel channel, Message message) throws IOException {
try{
System.out.println(new String(message.getBody(),"UTF-8"));
//TODO 具体业务
.......
//你使用手动消息确认模式时,basicAck 一定要执行,不然会导致会保留在队列中,无法被消费
//第1个参数表示消息投递序号
//第2个参数false只确认当前一个消息收到(大多数情况下都设置为false),true确认所有consumer获得的消息
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
} catch (Exception e) {
//若是消息没有成功接收,第二个参数设置为true的话,代表重新放回队列中,false则为丢弃,在此也可以做成放置死信队列的操作
channel.basicReject(message.getMessageProperties().getDeliveryTag(),false);
}
}
}
确认和拒绝消息:
- basicAck: 这个方法用于确认消息已被成功处理。
第一个参数是消息的delivery tag(用于标识消息),
第二个参数指定是否批量确认(false表示只确认当前消息)。- basicReject: 这个方法用于拒绝消息。
第一个参数同样是delivery tag,
第二个参数指定是否将消息重新放回队列(false表示不重新放回,即丢弃消息)。
方法解释:
- emailProcess: 这个方法监听
emailQueue队列。
当队列中有消息时,它会打印出消息的内容,并尝试确认消息。
如果处理过程中发生异常,它会拒绝消息,但不会重新放回队列(第二个参数为false)。
问题二:消息重复的解决方案
什么时候会重复消费
1.自动提交模式时
消费者收到消息后,要自动提交,但提交后,网络出故障,RabbitMQ服务器没收到提交消息,那么此消息会被重新放入队列,会再次发给消费者。
2.手动提交模式时
情景1:网络故障问题,同上。
情景2:接收到消息并处理结束了,此时消费者挂了,没有手动提交消息。
总体来说就是:网络不可达、消费端宕机。
如何解决
消费端处理消息的业务逻辑保持幂等性
比如你拿个数据要写库,先根据主键查一下,如果这数据有了,就别插入了,update 一下。
比如你是写 Redis,那没问题了,反正每次都是 set,天然幂等性。
问题三:保证消息顺序的解决方案
单一队列和单一消费者模式(RabbitMQ)
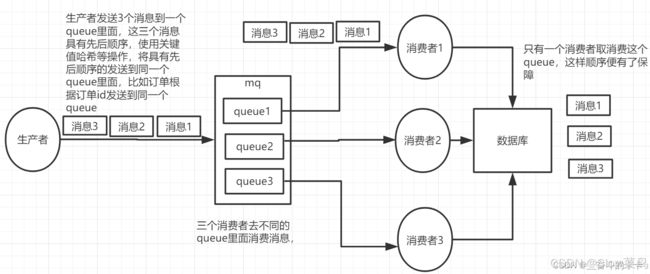
在RabbitMQ中,可以确保一个队列只被一个消费者消费,这样可以保证消息按照发送的顺序被处理。
因为队列本身就是一个先进先出的结构。
适用场景:RabbitMQ用户且对消息顺序有严格要求的场景。
优点:实现简单,易于管理。
缺点:可能成为性能瓶颈,在处理大量消息时需要考虑扩展性。
问题四:消息堆积的解决方案
消息堆积原因
消息堆积即消息没及时被消费,是生产者生产消息速度快于消费者消费的速度导致的。
消费者消费慢可能是因为:本身逻辑耗费时间较长、阻塞了。
预防措施
生产者
1.减少发布频率
3.考虑使用队列最大长度限制
消费者
1.优化代码
已出事故的解决措施
情况1:堆积的消息还需要使用
方案1:简单修复
修复 消费者(consumer)的问题,让他恢复消费速度,然后等待几个小时消费完毕
方案2:复杂修复
单队列消费转变为多队列并行消费
也是需要先 修复 消费者(consumer)的问题,再进行下面的步骤
步骤 1: 队列和路由设置
1.创建新队列:在RabbitMQ中创建10个新队列,每个队列分配一个独特的名称。
2. 设置交换机:定义一个直连型(Direct)交换机。
3. 绑定路由键:将每个新队列通过唯一的路由键绑定到直连型交换机上。
伪代码例子:
// 假设这是配置类的一部分
@Bean
Queue queue1() {
return new Queue("queue1", false);
}
@Bean
Queue queue2() {
return new Queue("queue2", false);
}
// 以此类推,为其他9个队列创建Bean
.........
@Bean
DirectExchange exchange() {
return new DirectExchange("myExchange");
}
@Bean
Binding binding1(Queue queue1, DirectExchange exchange) {
return BindingBuilder.bind(queue1).to(exchange).with("routingKey1");
}
@Bean
Binding binding2(Queue queue2, DirectExchange exchange) {
return BindingBuilder.bind(queue2).to(exchange).with("routingKey2");
}
// 以此类推,为其他队列和路由键创建绑定
......
步骤 2: 消息分发
1.接收堆积数据:现有消费者(或分发者)接收从发送者处堆积的数据。
2.分发到新队列:实现分发逻辑,将接收到的消息根据路由键分发到相应的10个新队列中。
伪代码例子:
@RabbitListener(queues = "oldQueue")
public void emailProcess(Message message, Channel channel) throws IOException {
try {
// 生成1-10之间的顺序数
SequentialRandom sequentialRandom = new SequentialRandom()
String key = sequentialRandom.getNextSequentialRandom();
// 重新发送消息到交换机,交换机将根据routingKey将消息路由到正确的队列
rabbitTemplate.convertAndSend("myExchange", "routingKey"+key, new String(message.getBody(),"UTF-8"));
// 确认原始队列中的消息(如果您想要的话)
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
// 处理异常,可能包括记录日志、发送警报等
channel.basicReject(message.getMessageProperties().getDeliveryTag(), false);
}
}
public class SequentialRandom {
private int currentIndex = 1; // 初始索引为1
/**
* 获取下一个顺序数
* @return 下一个数字,从1到10循环
*/
public int getNextSequentialRandom() {
int next = currentIndex;
currentIndex = (currentIndex % 10) + 1; // 使用模运算实现循环,并更新索引
return next;
}
}
步骤 3: 并行消费
1.开发新消费端:编写新的消费端程序,该程序能够监并处理来自10个新队列的消息。
2. 部署并启动:将新消费端程序部署到服务器,并启动它以开始并行消费。
伪代码例子:
@Component
public class ParallelConsumer {
@RabbitListener(queues = {"queue1"})
public void receiveMessage1(Message message) {
// 处理消息
}
@RabbitListener(queues = {"queue2"})
public void receiveMessage2(Message message) {
// 处理消息
}
// ...
@RabbitListener(queues = {"queue10"})
public void receiveMessage3(Message message) {
// 处理消息
}
}
情况2:堆积的消息不需要使用
删除消息即可。(可以在RabbitMQ控制台删除,或者使用命令)。