Nutch1.2搜索引擎使用详解
Nutch作为一款刚刚诞生的开源Web搜索引擎,提供了除商业搜索引擎外的一种新的选择。个人、企业都可通过Nutch来构建适合于自身需要的搜索引擎平台,提供适合于自身的搜索服务,而不必完全被动接收商业搜索引擎的各种约束。
Nutch 是基于Lucene的。Lucene为 Nutch 提供了文本索引和搜索的API。如果你不需要抓取数据的话,应该使用Lucene。常见的应用场合是:你有数据源,需要为这些数据提供一个搜索页面。在这 种情况下,最好的方式是直接从数据库中取出数据并用Lucene API建立索引。Nutch 适用于你无法直接获取数据库中的数据网站,或者比较分散的数据源的情况下使用。
Nutch的工作流程可以分为两个大的部分:抓取部分与搜索部分。抓取程序抓取页面并把抓取回来的数据进行反向索引,搜索程序则对反向索引进行搜索回答用户的请求,索引是联系这两者的纽带。下图是对Nutch整个工作流程的描述。
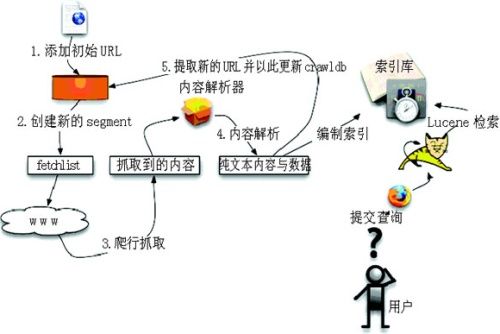
首先需要建立一个空的URL数据库,并且把起始根urls添加到URL数据库中(步骤1),依据URL数据库在新创建的segment中生成 fetchlist,存放了待爬行的URLs(步骤2),根据fetchlist从Internet进行相关网页内容的爬行抓取与下载(步骤3),随后把 这些抓取到的内容解析成文本与数据(步骤4),从中提取出新的网页链接URL,并对UR数据库进行更新(步骤5),重复步骤2-5直到达到被指定的爬行抓 取深度。以上过程构成了Nutch的整个抓取过程,可以用一个循环来对其进行描述:生成→抓取→更新→循环。
当抓取过程完成后,对抓取到的网页进行反向索引,对重复的内容与URL进行剔除,然后对多个索引进行合并,为搜索建立统一的索引库,而后用户可通过 由Tomcat容器提供的Nutch用户界面提交搜索请求,然后由Lucene对索引库进行查询,并返回搜索结果给用户,完成整个搜索过程。
一、爬行企业内部网(http://www.my400800.cn )
爬行企业内部网(Intranet Crawling)这种方式适合于针对一小撮Web服务器,并且网页数在百万以内的情况。它使用crawl命令进行网络爬行抓取。在进行爬行前,需要对Nutch进行一系列的配置,过程如下:
1、数据抓取:需要创建一个目录,并且在此目录中创建包含起始根URLs的文件。我们以爬行搜狐网站(http://www.sohu.com)为例进行讲述。
创建url文件列表
创建urls文件夹并打开urls文件夹,并在内部建立urls.txt文件,其内容为:http://www.sohu.com/。
依据爬行网站的实际情况,可继续在此文件末尾添加其他URL或者在URL目录里添加其他包含URL的文件。
修改conf/crawl-urlfilter.txt文件
文件conf/crawl-urlfilter.txt主要用于限定爬行的URL形式,其中URL的形式使用正则表达式进行描述。将文中MY.DOMAIN.NAME部分替换为准备爬行的域名,并去掉前面的注释。因此在本文中进行域名替换后的形式为:
+^http://([a-z0-9]*\.)*sohu.com/ |
该配置文件还能设置更多相关信息,比如如下,设定那些文件不被抓取
# skip image and other suffixes we can't yet parse -\.(gif|GIF|jpg|JPG|png|PNG|ico|ICO|css|sit|eps|wmf|zip|ppt|mpg|xls|gz|rpm|tgz|mov|MOV|exe|jpeg|JPEG|bmp|BMP|rar|RAR|js|JS)$ |
修改文件conf/nutch-site.xml
//这个地方每次抓取前一定要修改,否则就会出现抓不到的现象
< ?xml version="1.0"?>
< ?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
< configuration>
< property>
< name>http.agent.name< /name>
< value>sohu.com< /value>
< description>sohu.com< /description>
< /property>
<property>
<name>http.agent.description</name>
<value></value>
<description></description>
</property>
<property>
<name>http.agent.url</name>
<value></value>
<description></description>
</property>
<property>
<name>http.agent.email</name>
<value></value>
<description></description>
</property>
< /configuration>
|
开始爬行抓取
完成对Nutch的配置后,运行crawal命令进行爬行。
#bin/nutch crawl urls -dir crawl -depth 5 -threads 4 -topN 1000 |
其中命令行中各参数项含义分别为:
- dir指定爬行结果的存放目录,此处dir为crawl;
- depth指定从根URL起将要爬行的深度,此例depth设定为5;
- N设定每一层爬行靠前的N个URL,此例N值设定为1000。
另外,crawl还有一个参数项:threads,它设定并行爬行的进程数。在爬行过程中,可通过Nutch日志文件查看爬行的进展状态,爬行完成后结果存放在logs目录里,可在最后加上
>& logs/crawl.log |
如:
bin/nutch crawl urls -dir crawl -depth 2 -threads 4 -topN 1000 >&logs/crawl.log |
执行完成后,生成的目录:
- crawdb,linkdb 是web link目录,存放url 及url的互联关系,作为爬行与重新爬行的依据,页面默认30天过期。
- segments 是主目录,存放抓回来的网页。页面内容有bytes[]的raw content 和 parsed text的形式。nutch以广度优先的原则来爬行,因此每爬完一轮会生成一个segment目录。
- index 是lucene的索引目录,是indexs里所有index合并后的完整索引,注意索引文件只对页面内容进行索引,没有进行存储,因此查询时要去访问segments目录才能获得页面内容。
- 可以执行 bin/nutch readdb crawl/crawldb/ -stats查看抓取信息。
- 可以执行bin/nutch org.apache.nutch.searcher.NutchBean 字符串 做简单的测试。
2、项目部署:把nutch-1.2文件夹下的nutch-1.2.war拷到tomcat的webapps文件下打开tomcat,nutch-1.2.war会自动被解压成同名的nutch-1.2文件夹。
配置nutch-1.2/WEB-INF/classes/nutch-site.xml
修改后如下:
<configuration>
<property>
<name>searcher.dir</name>
<value>E:\cygwin\nutch-1.2\crawl</value>
</property>
</configuration>
|
注:E:\cygwin\nutch-1.2\crawl这个路径就是你之前抓取数据的存放路径。
中文乱码问题
配置tomcat的conf文件夹下的server.xml。
修改如下:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"
useBodyEncodingForURI="true"/>
|
修改页面元素,屏蔽中文乱码
另外:在webapps\nutch\zh\include 下面新建header.jsp,内容就是复制header.html,但是前面加上:
<%@ page contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> |
同时在webapps\nutch\search.jsp里面,找到并修改为:
<% String pathl= language + “/include/header.jsp"; System.out.println(pathl); %> <jsp:include page="<%= pathl %>"/> |
3、抓取目录分析
一共生成5个文件夹,分别是:
Crawldb:存放下载的URL,以及下载的日期,用来页面更新检查时间。
Linkdb:存放URL的互联关系,是下载完成后分析得到的。
Segments:存放抓取的页面,下面子目录的个数于获取的页面层数有关系,通常每一层页 面会独立存放一个子目录,子目录名称为时间,便于管理.没抓取一层页面就会生成一个目录,如20101222185215(按时间缩写的),.每个子目录里又有6个子文件夹如下:
- content:每个下载页面的内容。
- crawl_fetch:每个下载URL的状态。
- crawl_generate:待下载URL集合。
- crawl_parse:包含来更新crawldb的外部链接库。
- parse_data:包含每个URL解析出的外部链接和元数据。
- parse_text:包含每个解析过的URL的文本内容。
indexs:存放每次下载的独立索引目录。
index:是lucene的索引目录,是indexes目录里所有index合并后的完整索引,注意索引文件只对页面内容进行索引,没有进行存储,因此查询时要去访问segments目录才能获得页面内容。
二、 爬行整个互联网
爬行整个互联网(Whole-web crawling)是一种大规模网络爬行,与第一种爬行方式相对,具有更强的控制性,使用inject、generate、fetch、updatedb等比较低层次的命令,爬行量大,可能需要数台机器数周才能完成。
1、名词解释:
web 数据库: nutch所知道的page,以及在这些page里头的links (由injector通过DMOZ往里添加page,Dmoz(The Open Directory Project/ODP)是一个人工编辑管理的目录集合,为搜索引擎提供结果或数据。) WebDB存储的内容有(url、对内容的MD5摘要、Outlinks ,page的link数目、抓取信息,可决定是否重新抓取,Page的score,决定页面的重要性)
段(segment)集合:是指page的一个集合,对它进行抓取与索引都作为同一个单元对待。它包含以下类型:
- Fetchlist 这些page的名称的集合
- Fetcher output: 这些page文件的集合
- Index: lucene格式的索引输出
2、抓取数据,建立web database与segments
首先,需要下载一个包含海量URL的文件。下载完成后,将其拷贝到Nutch主目录,并且解压缩文件。
Linux下下载并解压:

content.rdf.u8包含了约三百万个URL,在此仅随机抽取五万分之一的URL进行爬行。同第一种方法一样,首先需要建立包含起始根URL的文件及其父目录。
#mkdir urls #bin/nutch org.apache.nutch.tools.DmozParser content.rdf.u8 -subset 50000 > urls/urllist |
采用Nutch的inject命令将这些URL添加crawldb中。这里,目录crawl是爬行数据存储的根目录。
#bin/nutch inject crawl/crawldb urls |
然后,编辑文件conf/nutch-site.xml,内容及方法与“爬行企业内部网”类似,此处略过。接着,开始爬行抓取。可以将整个爬行抓取 的命令写成一个shell脚本,每次抓取只需执行此脚本即可,即生成→抓取→更新的过程。根据需要可反复运行此脚本进行爬行抓取。脚本范例及相应的说明如 下:

最后,进行索引。爬行抓取完后,需要对抓取回来的内容进行索引,以供搜索查询。过程如下:
#建立索引 #bin/nutch invertlinks crawl/linkdb crawl/segments/* //倒置所有链接 #bin/nutch index crawl/indexes crawl/crawldb crawl/linkdb crawl/segments/* |
3、数据部署与查询:索引建立之后,便可以按照单网抓取的方式进行部署和查询了,其过程在此就不在一一介绍了。
nutch 手动抓取命令讲解
最近在研究nutch,找到了关于使用底层命令进行全网爬行的资料。
首先获得网址集,使用http://rdf.dmoz.org/rdf/ 目录下的content.example.txt 文件做测试,建立文件夹dmoz
命令:bin/nutch org.apache.nutch.tools.DmozParser content.example.txt >dmoz/urls
注射网址到crawldb数据库:
命令:bin/nutch inject crawl/crawldb dmoz
创建抓取列表:
命令:bin/nutch generate crawl/crawldb crawl/segments
把segments下的文件保存到变量s1中,供以后调用:
命令:s1=`ls -d crawl/segments/2* | tail -1`
命令:echo $s1
注`不是单引号,而是左上角跟~一个键位的那个
运行fetcher获取这些url信息:
命令:bin/nutch fetch $s1
更新数据库,把获取的页面信息存进数据库中:
命令:bin/nutch updatedb crawl/crawldb $s1
第一次抓取结束。
接下来选择分值排在前10的url来进行第二次和第三次抓取:
命令:bin/nutch generate crawl/crawldb crawl/segments -topN 10
命令:s2=`ls -d crawl/segments/2* | tail -1`
命令:echo $s2
命令:bin/nutch fetch $s2
命令:bin/nutch updatedb crawl/crawldb $s2
命令:bin/nutch generate crawl/crawldb crawl/segments -topN 10
命令:s3=`ls -d crawl/segments/2* | tail -1`
命令:echo $s3
命令:bin/nutch fetch $s3
命令:bin/nutch updatedb crawl/crawldb $s3
根据segments的内容更新linkdb数据库:
命令:bin/nutch invertlinks crawl/linkdb crawl/segments/*
建立索引:
命令:bin/nutch index crawl/indexes crawl/crawldb crawl/linkdb crawl/segments/*
可以通过此命令进行查询:
命令:bin/nutch org.apache.nutch.searcher.NutchBean faq 此处的faq代表所要搜索的关键词